现在你总共有 n 门课需要选,记为 0 到 n-1。
在选修某些课程之前需要一些先修课程。 例如,想要学习课程 0 ,你需要先完成课程 1 ,我们用一个匹配来表示他们: [0,1]
给定课程总量以及它们的先决条件,返回你为了学完所有课程所安排的学习顺序。
可能会有多个正确的顺序,你只要返回一种就可以了。如果不可能完成所有课程,返回一个空数组。
示例 1:
输入: 2, [[1,0]]
输出: [0,1]
解释:
总共有 2 门课程。要学习课程 1,你需要先完成课程 0。
因此,正确的课程顺序为 [0,1] 。
示例 2:
输入: 4, [[1,0],[2,0],[3,1],[3,2]]
输出: [0,1,2,3] or [0,2,1,3]
解释:
总共有 4 门课程。要学习课程 3,你应该先完成课程 1 和课程 2。
并且课程 1 和课程 2 都应该排在课程 0 之后。
因此,一个正确的课程顺序是 [0,1,2,3] 。
另一个正确的排序是 [0,2,1,3] 。
说明:
输入的先决条件是由边缘列表表示的图形,而不是邻接矩阵。详情请参见图的表示法。
你可以假定输入的先决条件中没有重复的边。
提示:
这个问题相当于查找一个循环是否存在于有向图中。如果存在循环,则不存在拓扑排序,因此不可能选取所有课程进行学习。
通过 DFS 进行拓扑排序 - 一个关于Coursera的精彩视频教程(21分钟),介绍拓扑排序的基本概念。
拓扑排序也可以通过 BFS 完成。
来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/course-schedule-ii
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
思路
一开始我是直接用传统的拓扑排序,遍历每个节点,计算入度,访问入度为0的点,但是这样做的复杂度是O(n*e),n是节点数,e是边数,因为每次要遍历边集合来计算每个点的入度
class Solution {
public:
vector<int> findOrder(int numCourses, vector<vector<int>>& prerequisites)
{
vector<int> ans;
vector<bool> vis(numCourses, false);
while(1)
{
vector<int> cnt(numCourses);
for(int i=0; i<prerequisites.size(); i++)
if(!vis[prerequisites[i][0]] && !vis[prerequisites[i][1]])
cnt[prerequisites[i][0]]++;
bool flag = false;
for(int i=0; i<numCourses; i++)
if(cnt[i]==0 && !vis[i]) {vis[i]=true; flag=true; ans.push_back(i);}
if(!flag) break;
}
if(ans.size()==numCourses) return ans;
return {};
}
};
但其实可以建立邻接表存储图关系(注意这里是逆邻接表),然后用dfs,对节点x进行dfs,需要注意的顺序:
- 先递归访问 x 的所有前驱节点
- 输出x节点
这样可以保证输出的顺序
值得注意的是,如果图中有环的判断,因为可能存在不同的连通分量,我们必须枚举起点,对每个起点都跑一遍dfs,但是就可能会出现以下情况:
我们dfs了一个起点 a,接下来我们dfs起点 b, b的前驱是a,但是 a 已经被访问过了,如果单纯地以 “当前节点的前驱节点已经被访问过” 来判断出现环的话,这里就会出现误判
正确的判断是:
在同一趟递归中,当前节点的前驱节点已经被访问过,才说明出现环
使用int数组存储节点的访问情况,引入状态 [2] 能有效规避因为枚举起点造成的环的误判
- 0表示未被访问
- 1表示已经被访问(也就是曾经进了dfs,但是退栈了
- 2表示正在递归中(也就是进了dfs,还没退栈
如图,节点上的数字表示他们的状态
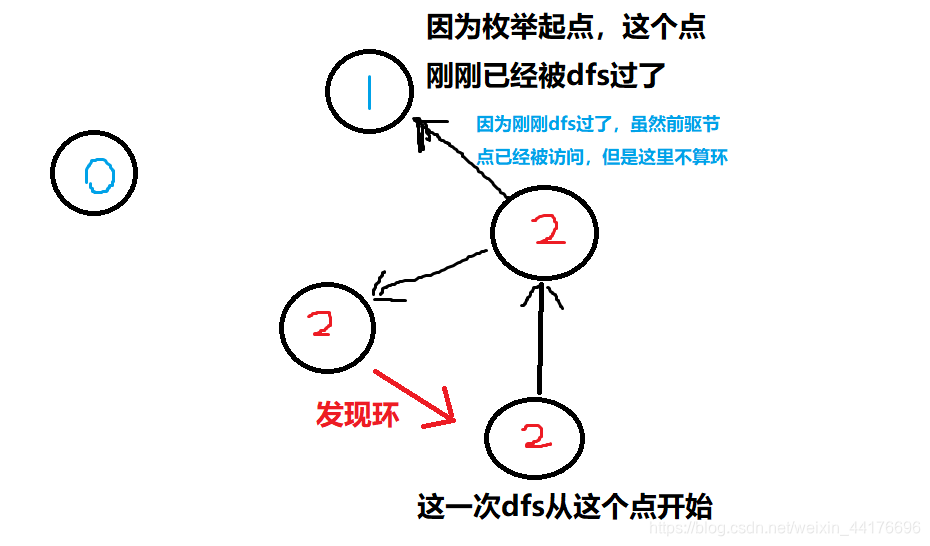
dfs需要返回结果,如果是1表示发现环
- 如果我们dfs遇到了1,那么直接返回0,因为之前已经判断过了,这个节点及其所有前驱已经加入答案
- 如果dfs遇到2,返回1,说明发现环
- 如果dfs遇到0,dfs当前节点的所有前驱节点
代码
相比于上面的拓扑排序,这里我们每访问k条边,就会访问k个顶点,复杂度降低为O(n),而上面的方法1,每访问所有的边,才删除一个顶点,总体复杂度O(n*e)
class Solution {
public:
vector<int> ans;
int dfs(vector<vector<int>>& adj, vector<int>& vis, int x)
{
// 2表示x节点还未退栈,说明发现环
if(vis[x]==2) return 1;
if(vis[x]==1) return 0;
// 节点置2,表示正在递归
vis[x]=2; int flag=0;
for(int i=0; i<adj[x].size(); i++)
if(dfs(adj, vis, adj[x][i])) return 1;
// 递归所有前驱未发现环,退栈之前vis置1
ans.push_back(x); vis[x]=1;
return 0;
}
vector<int> findOrder(int numCourses, vector<vector<int>>& prerequisites)
{
vector<vector<int>> adj(numCourses);
// 逆邻接表
for(int i=0; i<prerequisites.size(); i++)
adj[prerequisites[i][0]].push_back(prerequisites[i][1]);
vector<int> vis(numCourses);
for(int i=0; i<numCourses; i++)
if(dfs(adj, vis, i)) return {};
return ans;
}
};
