引言
本文主要探讨无监督学习的线性方法(Linear Methods)。
聚类
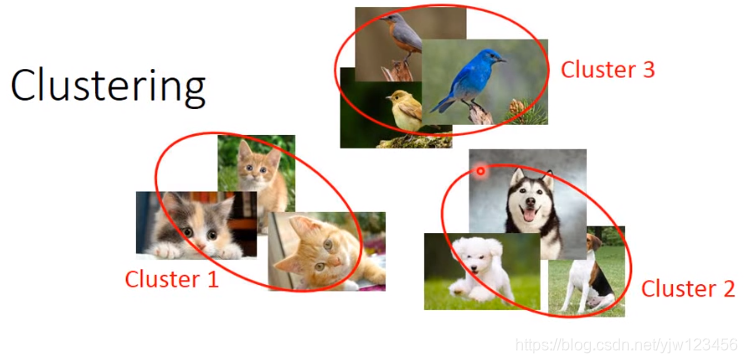
把很多不同的图像,根据它们的相似度分成不同的组(类别),问题是要分成多少个组。
最常用的方法有:
K-means
- 聚类 个数据 到 个组
- 初始化 个分组中心点: ,可以从 中随机 个点出来
- 重复
- 对 中的所有数据 :如果 最接近 ,那么 就属于 ,同时令 ;否则令
- 更新所有的中心点
层次凝聚聚类算法(Hierarchical Agglomerative Clustering,HAC)
- 步骤一:建一个树
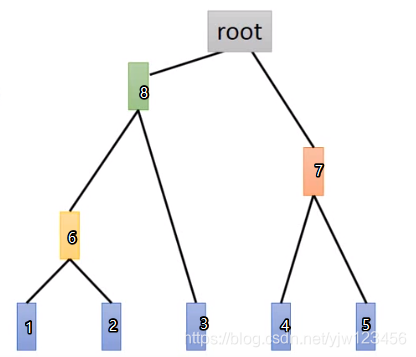
假设有5个样本,这种方法怎么聚类呢,首先把这5个样本相互之间计算相似度,然后选择最相似的两个合并成一个新的样本6。现在只剩下4个样本了,再计算之间的相似度,把最相似的两个数据合并起来,这里假设是4,5合并成了7。同理,最后只剩2个样本8和7。它们之间有共同的父节点root。
- 步骤二:选取一条分割线(threshold)
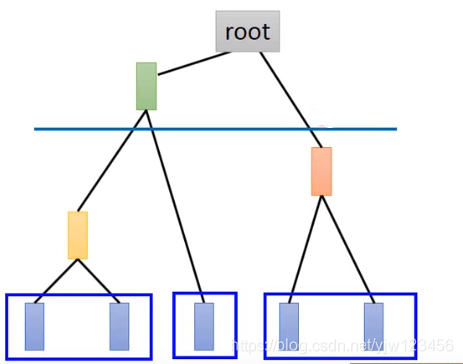
假设像上面这样切一刀,那么就得到三个分组。
降维(Dimension Reduction)
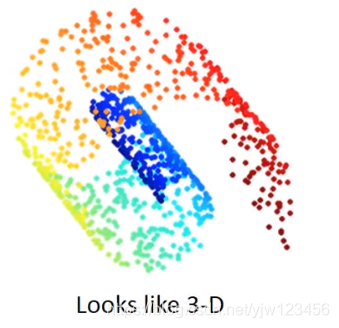
假设你的数据从三维空间看是长这样的,但是用三维来描述它是不必要的。可以通过二维的图像来描述它。
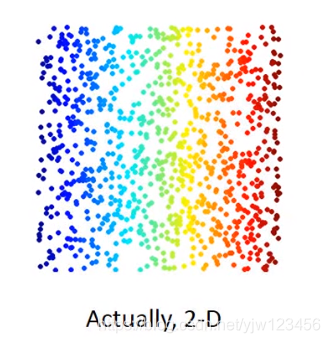
比如在MNIST的手写数字识别中,一个图像有28*28的。实际上其中大多数像素点代表的东西并不是数字,可能是空白啥的。
一个极端的例子是把数字三按不同的角度进行旋转。
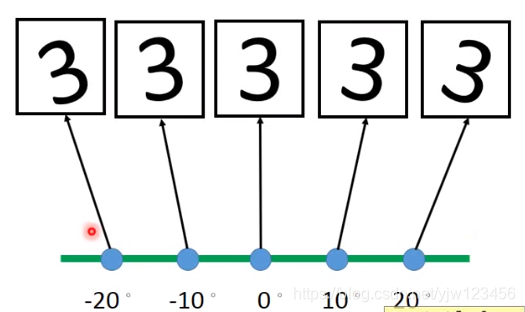
只要知道其中一幅图像和它的角度,就可以知道其他图像。
那怎么做降维呢。
还是要找到一个函数,它的输入是向量 ,输出是向量 ,其中 的维度必须必 小。
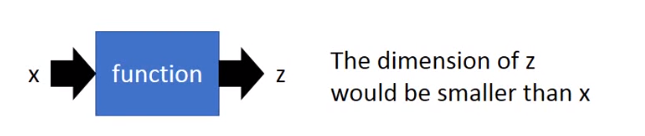
其中最简单的方法是特征选择(Feature selection)
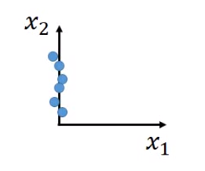
最简单的情况是,
这个维度的特征完全没用,我们就可以直接只选择
这个维度。但是这种情况比较罕见。通常每个维度或多或少都有一定的作用。
有一种常见的方法叫主成分分析(Principle component analysis,PCA)
这个
是个很简单的线性函数,输入
和输出
之间的关系,就是一个线性的转换。
现在要做的事情就是根据很多输入,找出这个
。
假设我们要降到1维的情况。此时
就是一个标量,
是行向量:
,
表示
的第一行,我们把
与
做内积,得到
假设
的长度是1,
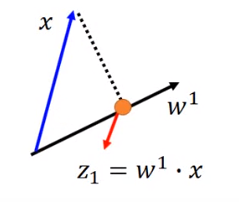
意味着 是 在 上的投影。
现在问题是应该选哪个
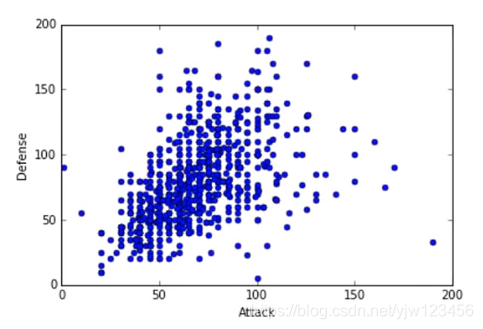
假设上图中的每个点代表一只宝可梦,横坐标是攻击力,纵坐标是防御力。把二维投影到一维,应该要选什么样的 呢
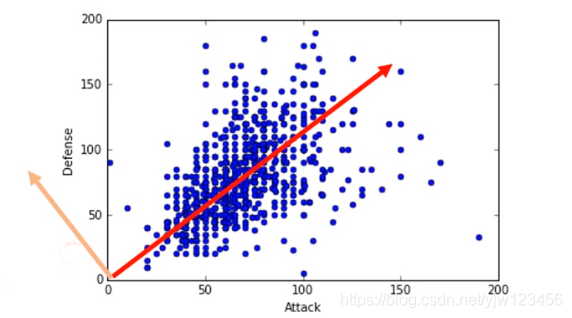
上图的两个带箭头的直线代表两个不同的 ,我们希望经过投影后得到的 分布越大越好。即经过投影后还能保持数据点之间的区别。
在上面的例子中,可以看出如果选择红线,点的分布会大一点。
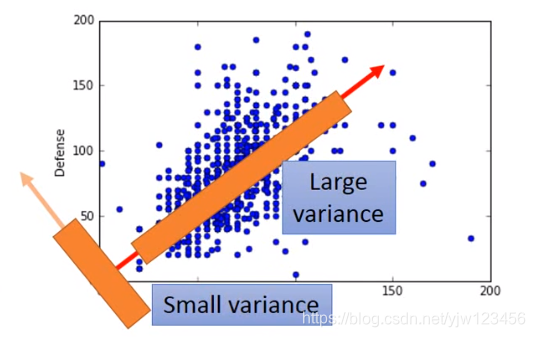
选择的
可能是具有具体意义的,比如这里这个
代表宝可梦的强度。
如果用式子来表示的话,就是需要最大化 的方差:
如果想投影到二维的平面上,这是把 和另外的 做内积可以得到 。
首先 的长度也是1。
同时也要最大化 。但是如果仅仅是这样那不就和找 的做法是一样的,因此这里需要增加一点东西,我们限制 ,即它们之间的内积是0。
