在机器学习的领域,有两类主要的任务:监督学习与无监督学习。这两种方法上的区别在于,监督学习是使用真实的标签来完成的,但是在无监督中,却不存在这样的标签。因为这样的特性,监督学习的目标是学习一个函数,在已知该样本数据与输出值的情况下,尽最大的可能去拟合输入与输出的关系,无监督学习一般是推断一组数据的内部结构.
监督学习中有两大主要的任务,即分类任务与回归任务.
下图形象的展示了什么是分类,什么是回归问题
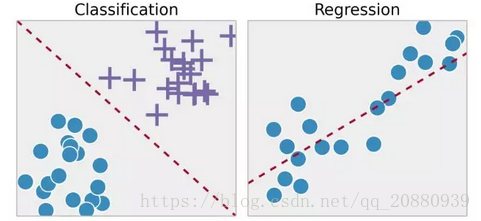
进行监督学习时,有的一些问题需要综合考虑模型复杂度。
模型的复杂程度取决于训练数据的性质,这时需要根据具体问题具体的分析,比如我们需要在两个点之间拟合一条曲线,从理论上来说,我们可以使用任意的复杂的函数曲线进行拟合,但是这样往往会导致过拟合,因为一般的情况下,我们仅仅会考虑一条直线来拟合两个点之间的直线。
无监督学习
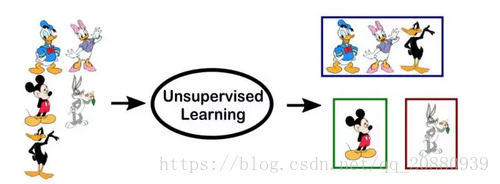
无监督学习最常见的就是聚类任务、表示学习、密度估计。在这些任务中,我们希望不提供任何的标签的情况下,了解数据的内在结构。最常用的就是聚类,由于没有提供标签,因此大多数无监督的学习方法中没有具体的方法去比较模型之间的性能.
无监督学习的两种常见的用法是探索性分析与降维.
无监督学习在探索性分析的任务中很有用,我曾经在数据挖掘中,就用到了关于无监督的聚类的问题,其问题的背景就是根据人流在某一个区域的流动范围,让我们去估计这一个地带的特征,当时记得用到的就是无监督学习中的层次聚类,因为数据是非常多的,并且有时候收集到的数据有不同的属性,因此单凭我们去分析,很难能够发现数据之间的联系,但是如果我们使用聚类的算法思想,我们就可在数据趋势不明朗的情况下,具体的将我们的数据分为几个不同的类型,为我们进一步的分析作为指引,(因为在有的数据挖掘实现中,我们需要提前知道该样本的具体分成了几个类别,将我们的类别数目作为参数传入到我们的函数中,因此需要聚类的方式先对数据进行分析)
降维指的是使用比较少的特征表示数据的一种方式,这一问题可以使用无监督的方法来完成,在表示学习中,我们希望了解各个特征间的关系,使得我们可以用初始特征间的潜在特征来表示数据,这种稀疏的潜在特征通常比原始特征的维度要低,因此可以使数据特征变得更加稠密,并且可以消除冗余.(说了这么多废话,主要就是当我们要降维时,要考虑到利用无监督的学习方式去操作)
(本文的部分内容来自于微信公众号:专知)