Manifold Learning
t-SNE的“N E”就是Neighbor Embedding的缩写。现在要做的事情就是之前讲过的降维,只不过是非线性的降维。
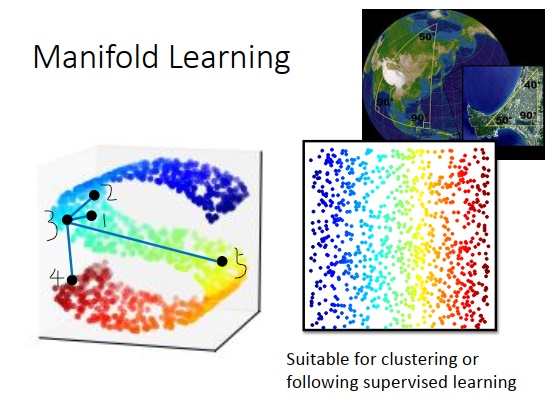
我们知道数据点可能是高维空间里的一个流形曲面,也可以说,数据点的分布其实是在一个低维的空间里面,只是被扭曲塞到了一个高维空间里。流形曲面常举的例子是地球,地球表面是一个流形曲面,是一个二维的平面,但是被塞到了一个三维的空间里。
在流形曲面里,只有距离很近的点,欧式距离才成立,距离远的时候欧式几何不一定成立。也就是如上图左边所示,在S形的这个空间里面取某一个点(黑点3),比较黑点3和黑点1,黑点3和黑点2的距离或者是合理的,黑点3和黑点1更像。如果距离比较远的点,要比较黑点3和黑点4,黑点3和黑点5的相似程度时,在高维空间中直接算欧式距离就不合理。如果根据欧式距离,那黑点3和黑点4更近,但实际上有可能黑点3和黑点5更近。所以流形学习要做的事情是把S形的曲面展开,把塞在高维空间里的低维空间摊平,摊平后可以在降维空间上用欧式距离计算点和点之间的距离。这对接下来要做的聚类或监督学习都是有帮助的。
LLE
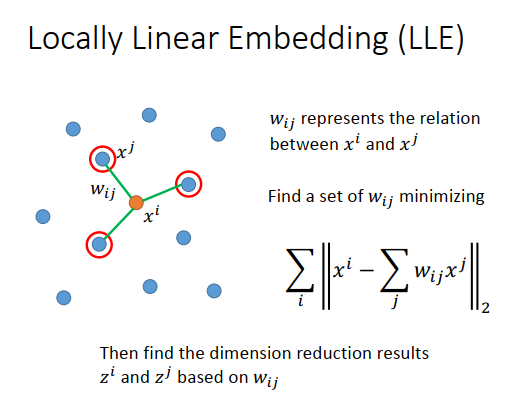
类似的方法有很多,其中一个叫做Locally Linear Embedding(局部线性嵌入)。
在原来空间里点的分布如上图左边所示,有某个点\(x^i\),先选出\(x^i\)的邻近点叫做\(x^j\),用\(w_{ij}\)表示\(x^i,x^j\)之间的关系。
\(w_{ij}\)是怎么找出来的?
假设每个\(x^i\)都可以由它的邻近点做线性组合而成,那\(w_{ij}\)就是线性组合的权重。现在找一组\(w_{ij}\),让\(x^i\)的所有邻近点\(x^j\)的线性组合\(\large \sum\limits_j w_{ij}x^j\)和\(x^i\)越接近越好,损失函数就是summation over所有的\(x^i\),使得2-norm越小越好。
接下来就要做降维,把原来所有的\(x^i,x^j\)转成\(z^i,z^j\) ,这里的原则是从\(x^i,x^j\)转成\(z^i,z^j\) ,中间的\(w_{ij}\)是不变的。

所谓的“在天”就是\(x^i,x^j\),在原来的空间上面,“比翼鸟”就是\(w_{ij}\) ,“在地”就是把\(x^,x^j\)转换到另外一个空间,就是\(z^i,z^j\),“连理枝”等于“比翼鸟”,还是\(w_{ij}\)

LLE做的的事情是这样的。首先在原来的空间找到\(w_{ij}\)后就固定住不变,接下来给每个\(x^i,x^j\)找另一个向量,因为要做降维,那新找的向量要比原来的维度小,比如原来100维降到10维2维之类的。\(z^i,z^j\)就是另外的向量,\(z^j\)使用同样的组合权重(\(w_{ij}\))去接近\(z^i\)。为找到\(z_i,z_j\),相当于\(w_{ij}\)已知,最小化\(\large ||z^i-\sum\limits_j w_{ij}z^j ||\),然后summation over所有的数据点\(z^i\)。
LLE没有一个明确的函数告诉你说怎么做降维,不像我们在做auto-encoder的时候,学习一个encoder的网络,input一个新的数据点,就可以得到降维的结果。LLE不会让你找到一个明确的函数,告诉我们说怎么从\(x\)变到\(z\),\(z\)就是另外凭空找出来的。
如果用LLE或者其它类似的方法会有一个好处,就算不知道原来的\(x^i,x^j\) ,只知道\(w_{ij}\) ,即不知道\(x^i,x^j\)用什么向量来描述,只知道它们之间的关系,也可用LLE这种方法。
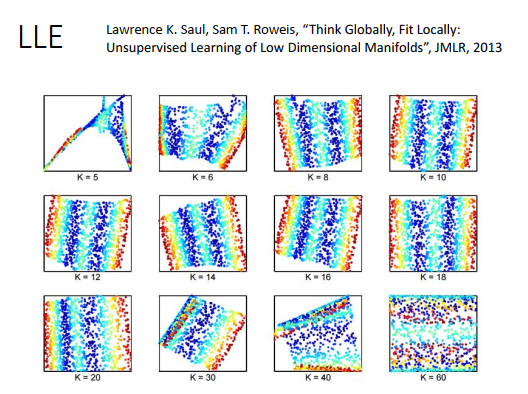
用LLE需要好好调整邻近点的个数K,个数要合适才会有好的结果。原始论文里调了不同的K,K太小和K太大得到的结果都不太好。
为什么K太大结果不好呢?
只有在距离很近的时候,才可以近似用欧式距离计算,所以点和点之间关系,在转换前后才可以被保持住。当K很大的时候,就会包括一些距离比较远的点,和这些点的关系在转换后就没办法保持住,有些关系太弱了。
拉普拉斯特征映射
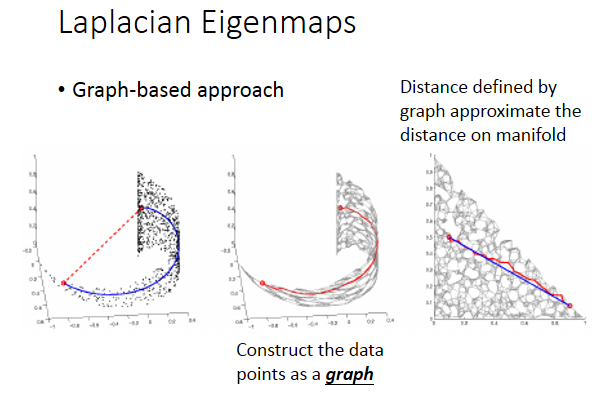
另外一个方法是laplacian eigenmap。 之前讲半监督学习的时候,讲过平滑度假设。想比较点和点之间的点,只计算欧式距离是不够的,要看它们在高维区域之间的距离,如果两个点之间有高维的连接,那它们才是真正的接近。这件事情可以用一个图来描述,也就是说你把你的数据点构造成一个图,算数据点两两之间的相似度,如果相似度超过一个阈值,就把它们连接起来。建一个图的方法有很多,总之就是把近的点连起来变成一个图。
如上图右边所示,把点变成图之后,考虑这个平滑距离(蓝色线条),就可以用图上点的连接来近似(红色折线)。
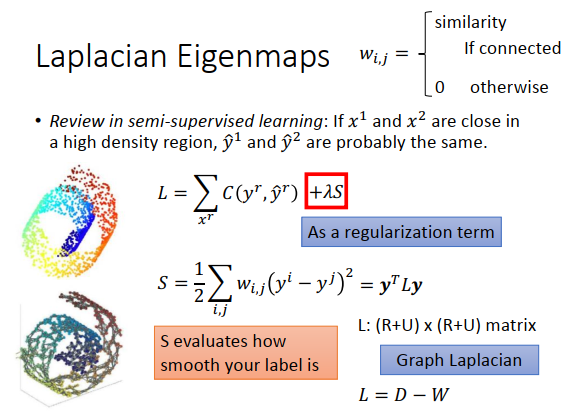
之前讲半监督学习的时候,我们这样说过,如果\(x^1\)跟\(x^2\)在高维区域上面是相近的,那么它们的label \(\hat {y}^1\)和\(\hat {y}^2\)很有可能也是一样的。虽然半监督学习的时候,我们有一项是考虑有label数据的项(\(\large \sum\limits_{x^r} C(y^r,\hat{y}^r)\))。另外一项是unlabel数据项\(\large \lambda S\),作用是考虑现在得到的label是不是平滑的,它的作用很像一个正则化项。 \(S\)为\(y^i\)跟\(y^j\)的距离乘上\(w_{i,j}\),如果两个数据点\(x^i\)和\(x^j\)在图上是相连的,那么\(w_{ij}\)就是它们的相似程度,如果没有相连,\(w_{ij}=0\)。如果\(w_{ij}\)是一个很大的值,那希望\(y^i,y^j\)越接近越好,如果\(w_{ij}=0\),\(y^i,y^j\)什么值都可以。\(S\)越小越平滑,用来评估你现在得到的label有多平滑,\(S\)可以写成\(\bf{y}\)的向量乘以\(L\)再乘以\(\bf{y}\),这个\(L\)就是图拉普拉斯。

同样的道理可以被用在完全非监督的问题上。
如果\(x^1\)和\(x^2\)在高维区域是相近的,那我们自然希望\(z^1\)和\(z^2\)也是相近的。
今天把\(x^1,x^2\)变成\(z^1,z^2\)后,如果\(x^i,x^j\)很像(\(w_{i,j}\) 很大),那\(z^i,z^j\)的距离就应该很近。
所以我们可以用最小化上图的\(S\)来寻找\(z^i,z^j\)吗?
这里面会有问题,如果只是最小化\(S\),那\(z^i,z^j\)都等于0向量不就可以了,这样\(s\)就等于0,最小了。所以光有最小化\(S\)是不够的。
那半监督学习为什么只要最小化\(S\)?
在半监督学习中,还有监督学习的那一项,如果把所以的\(y\)(label)都设成一样,会导致监督学习那一项的损失会很大,我们需要平衡监督学习那一项和平滑度那一项,所以不会选择所有的\(y\)都是一样。
这边少了监督学习的东西,所以可以选择所有的\(z\)都一样。
所以需要给\(z\)一些约束,如果降维后的\(z\)是M维的空间,那你找出来的N个点的空间维度等于M,即\(Span\{z^1,z^2,...,z^N\}=R^M\)。解这个\(z\)会发现和图拉普拉斯\(L\)是有关系的,其实就是\(L\)的比较小的特征值对应的特征向量。所以它叫做拉普拉斯特征映射,因为找得是拉普拉斯矩阵的特征向量。
找出\(z\)后再去做k-means聚类,就是光谱聚类。
t-SNE

t-SNE是t-distributed stochastic neighbor embedding(t分布随机邻居嵌入)的缩写。
前面的方法有个最大的问题是只假设相近的点要接近的,没有假设不想近的不接近。
比如在MNIST上使用LLE,你会遇到这种情形。如上图左下方所示,它确实会把同一个类的点都聚集在一起,但同时也把不同类的点叠在了一起,所以这些点都挤在一起,还是没有办法分开。
另外一个例子在COIL-20(一个图像库,比如一个对象小汽车做旋转不同角度的图)上使用LLE,如上图右下方所示,同样颜色代表同一个对象。你会发现它找到一些圈圈,这些圈圈代表同一个对象在旋转后降维得到的结果。同样的,不同的对象都挤在了一起。

t-SNE是怎么做的呢?
t-SNE也是做降维,把\(x\)降维到\(z\)。在原来\(x\)的空间上,我们会计算所有配对点\(x^i,x^j\)之间的相似度,写成\(S(x^i,x^j)\),接下来会做一个标准化。如上图计算\(P(x^j|x^i)\),分子的地方就是\(x^i,x^j\)之间的相似度,分母就是summation over \(x^i\)和所有其他点的相似度。
假设我们已经找到了低维度的向量\(z^i,z^j\),那也可以计算\(z^i,z^j\)的相似度,写成\(S'(z^i,z^j)\),同样的做一个标准化\(Q(z^i|z^j)\)。
做标准化是有必要的,因为你不知道高维空间中计算出来的距离\(S(x^i,x^j)\)和\(S'(z^i,z^j)\)的尺度是不是一样的。标准化后就可以都变成概率,值就都介于0和1之间。
到现在我们还不知道\(z^i,z^j\)的值到底是多少,这是我们要去找的。我们希望找一组\(z^i,z^j\)让\(P(x^j|x^i)\)的分布和\(Q(z^i|z^j)\)的分布越接近越好。我们知道KL散度可以衡量两个分布的相似度。那么我们就要最小化(\(x^i\)对其他点的分布)与(\(z^i\)对其他点的分布)之间的KL散度。如上图右下方所示。
这个最小化怎么做?
也是使用梯度下降,假设你知道\(S(x^i,x^j),S'(z^i,z^j)\)的式子长什么样子,代进公式里,对\(z\)做微分就可以了。
t-SNE有个问题是会计算所有点的相似度,所以计算量会有点大。所以常做的做法会先做降维,不从原来的高维空间里做t-SNE,会先做PCA降到低维空间(比如50维),然后再用t-SNE降维到2维。
给t-SNE一个新的数据,它就没办法处理,只能处理训练集\(x\),帮你找到\(z\),找完训练集的\(z\)之后,再给它一个新的\(x\),你就要重新做一遍t-SNE,很麻烦。所以t-SNE常常用来做可视化。
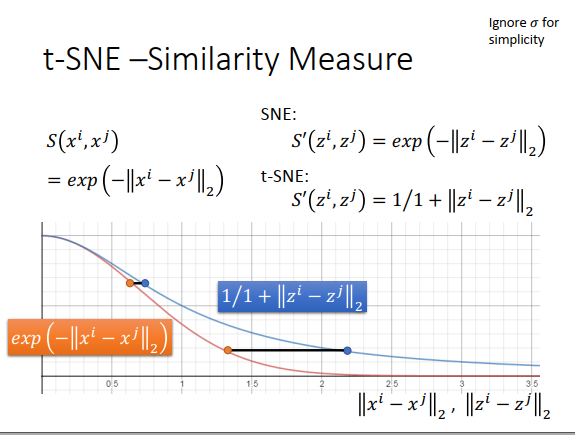
t-SNE一个非常有趣的地方是,它的这个相似度的选择非常神妙。在原来的空间上,\(x\)相似度的选择是RDF的函数,计算\(x^i,x^j\)的欧式距离,然后取负号,再取exp。之前也有说过,在图上计算相似度的话,用这种方法会比较好,因为它可以确保只有非常近的点才有值,exp变化很快,只要距离大,相似度就会变得很小。
在t-SNE之前有个方法叫做SNE,在新空间上也是用原空间的相似度计算方式,而t-SNE在新空间会选择一个不一样的相似度计算方式,在降维后计算方式是t-分布的其中一种(\(\large \frac{1}{1+||z^i-z^j||_2}\))。
为什么要使用t-分布样子的计算方式?
一个直觉的理由如上图,假设横轴代表欧式距离,橙色线是\(S\)相似度(RBF函数),蓝色线是\(S'\)相似度(t分布)。可以发现如果欧式距离很小,那么RBF函数和t分布值一样时,两个空间的欧式距离的差距就会很小,而欧式距离很大,RBF函数和t分布值一样时的,两个空间的欧式距离的差距就会很大。也就是说,原来高维空间里,如果距离很近,那做完转换后还是很近,如果原来距离很远,那转换后会拉得很远。
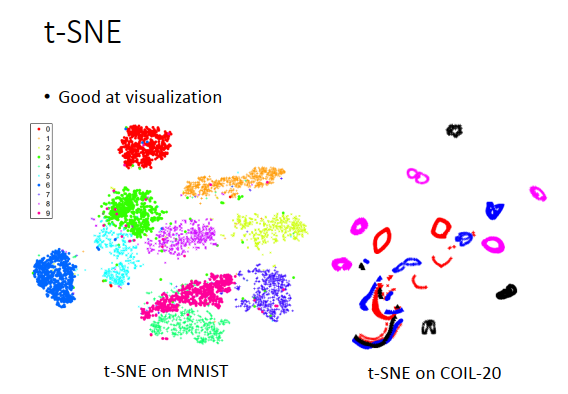
你会发现,t-SNE处理后,画出来的图会如上图一样。会把数据点聚集成一群一群的,因为原来数据点之间只要有一些差距,做完t-SNE只有,会让这种差距更明显。上图是t-SNE在MNIST上的结果,但是先对像素点做了PCA,最后效果会好一点。
上图不同颜色代表不同数字,会发现不同的数字变成一群一群的。
上图右边是t-SNE在COIL-20上的结果,每一个圈圈代表了同一个对象,是旋转了一周之后的结果。你会发现有一些扭曲的圈圈,这是因为有一些东西比如杯子,转圈圈后的图像样子是一样的。