引言
本文主要介绍了什么是结构化学习(Structured Learning),并简要介绍了下原理。最后对一些应用场景进行了一些说明。
结构化学习
到目前为止,我们考虑的问题它的输入和输出都只是向量。

实际上我们面对的问题可能比这更复杂,可能输入或输出是序列(sequence),列表(list)、树(tree)或边框(bounding box)。
我们想要一个更强大的函数 ,它的输入是一种对象,输出是另一种对象。
它其实有很多应用。
- 语音识别
- : 语音讯号(序列) → :文字(序列)
- 翻译
- : 中文语句(序列) → :英文语句(序列)
- 中文分词
- : 句子(序列) → :切分树(parsing tree,树结构)
- 目标检测
- : 图像 → :边框(bounding box)
- 摘要生成
- : 文档 → :摘要(短片段)
- 检索
- : 关键字→ :搜索结果(网页列表)

那如何做结构化学习呢,虽然它听起来困难,实际上有个统一的框架。
Unified Framework

训练的时候,找一个函数 ,它的输入是 和 ,输出是实数 。该实数代表这两个结构化对象有多匹配。
在测试的时候,给定一个新的结构化对象 ,穷举所有可能的 ,代入函数 ,求得使其结果最大的 。
目标检测
假设我们要做的是目标检测,给定一张图像,需要从图像中框出某个物体(目标)。
- : 图像 → :边框(bounding box)

比如要做凉宫春日人物(戴黄色丝带的那个)检测。这只是举个例子,看来李宏毅老师很喜欢二次元啊。实际上可以用同样的技术来检测人脸。

来识别车辆并测距离。
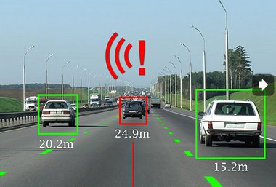
回到识别凉宫春日的图。

输入就是一张图像,输出就是一个边框, 说的是假设这张图片这个位置和这个红色边框有多匹配。
你可能期待你的模型能做到框的很正确。下面是一些正确和错误的示例:

接下来测试的时候,给定一张从来没看过的图像,穷举所有的边框。然后看哪个边框得到的分数最高。

可能红色的得到10分,黄色的分数最低。那么红色就是你模型的输出。
摘要生成
在摘要生成中,给定一篇很长的文章(文档),输出一个摘要。

我们训练的时候,当它的文章和正确的摘要配成一对的时候, 的值就很大,否则就很小。

在测试的时候就穷举所有可能的摘要,看哪个最匹配。

检索
在检索的时候,输入是一个关键字,输出是搜索结果的列表。

训练的时候,我们要知道输入某个关键字(query)的时候,输出哪个列表是最匹配的。

测试的时候,穷举所有可能的列表,看哪个列表得分最高。

虽然这个框架看起来很强大,但是这里有三个问题需要解决。
三个问题

- 长什么样子

当输入是个图像+边框,这个
是怎样的?
当输入是关键字+列表,这个
是怎样的?
- 如何解
arg max问题
的空间可能非常大。

要做目标检测要穷举所有可能的边界。
- 给定训练数据,如何找到

在训练的时候,我们希望正确的 的结果是最大的。
只要解决这三个问题,就能解结构化学习的问题。
与DNN的关系
结构化学习和深度神经网络是有关系的,怎么说。

假设现在要做手写数字识别,我们的
是这样的

先把 丢到DNN,得到一个向量叫 ,接下来再输入 ,这个 就是手写数字识别中的那个10维向量(只有一个维度是1其他都是0)。
然后把 和 做交叉熵(CE),把交叉熵的结果取负就是 。
接下来在测试的时候,需要穷举10个所有可能的结果。

每一个结果都代入这个函数中,看哪个结果让 最大。
所以这件时候和用交叉熵训练神经网络是一样的。
我们可以把
想成输入一个
输出它们有多匹配。
