上一篇博客介绍了无监督学习在文字中的降维方法——Word Embedding,本篇博客将继续介绍无监督学习算法的降维方法——Neighbor Embedding。
目录
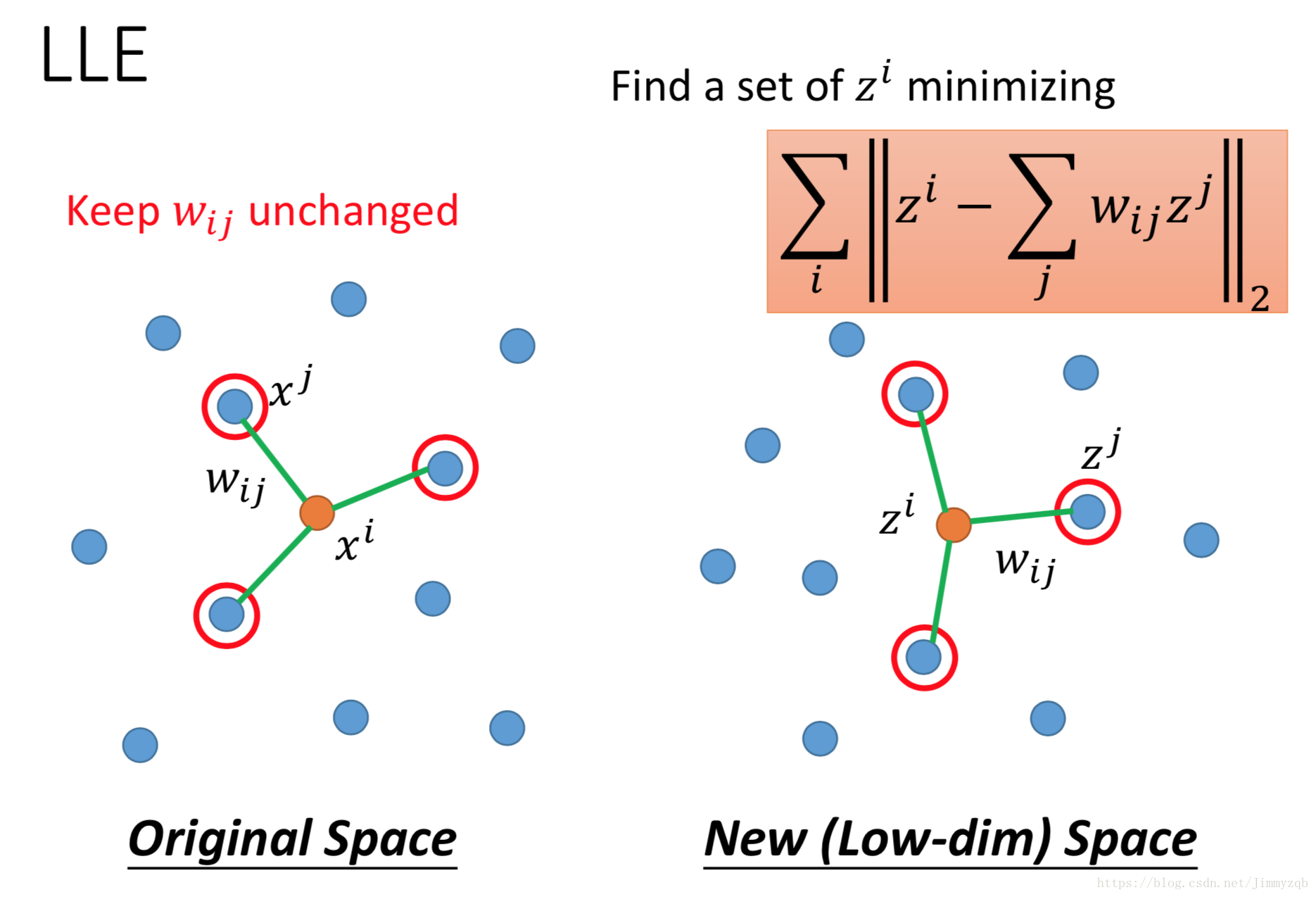
Locally Linear Embedding (LLE)
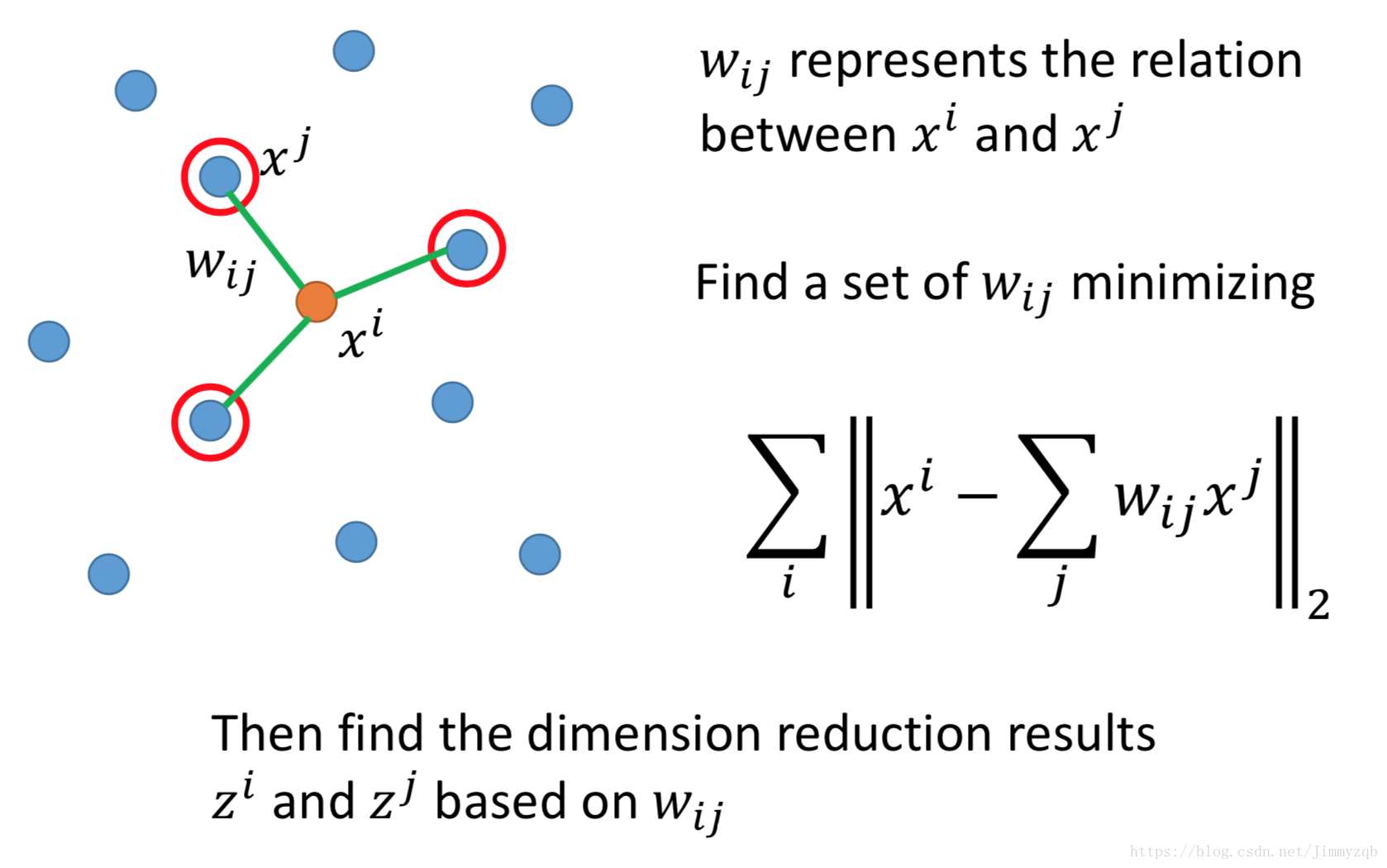
现在考虑 和 两点, 表示 和 这两点的关系,现在要找到所有 使得下式最小。
利用上一步求得的 在转化后的数据空间最小化下式
Laplacian Eigenmaps
在半监督学习的博客中详细介绍过类似的思维。

现在应用在无监督学习中,算法如下。

T-distributed Stochastic Neighbor Embedding (t-SNE)
t-SNE算法
上述两个方法都存在一个问题:算法说明了原来数据空间上很近的两个点在转化后的新数据空间上会很近,但是并没有说明原来数据空间上很远的两个点在转化后的新数据空间会怎么样,因此会出现本来不相关的数据在降维之后聚集在了一起。t-SNE可以解决这一问题,算法如下, 和 是原数据, 和 是降维后的数据,然后利用KL散度计算降维前后分布的相似度。
KL散度计算降维前后分布的相似度可以不管量纲

t-SNE –Similarity Measure
- SNE对距离很远的不敏感
- t-SNE会尽量扩大原数据的差异(降维空间分得很开)
