上一篇博客介绍了无监督学习中的线性降维方法,本篇博客将继续介绍无监督学习在文字中的降维方法——Word Embedding。
目录
Word Embedding
Word Embedding介绍
Word Embedding希望通过训练大量的材料(结合上下文关系),将词汇描述成一个向量。
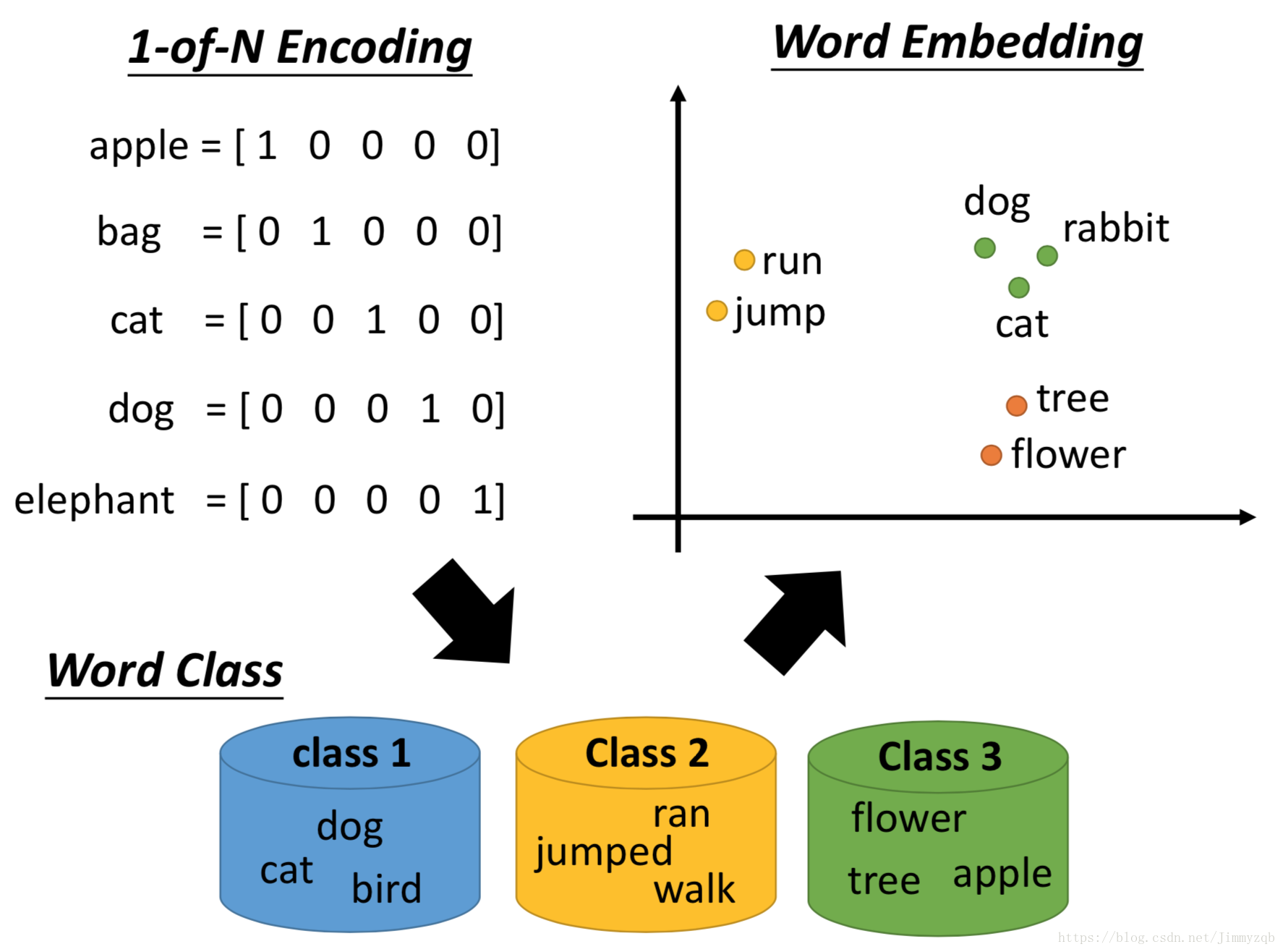
- 一种最简单的词汇描述成向量的方法就是1-of-N Encoding方法,假设现在世界上只有下面5个单词,则可以使用5维的向量分别表示一个词汇,但是这种方法不能描述向量之间的关系
- 因此在此基础上进行词汇归类
- 但是直接归类的方法很粗糙,所以进一步提出了Word Embedding方法,每一个词汇用多个维度描述
利用上下文
利用上下文来推断词汇的关系有两种主要的思路——Count based和Perdition based。
Count based
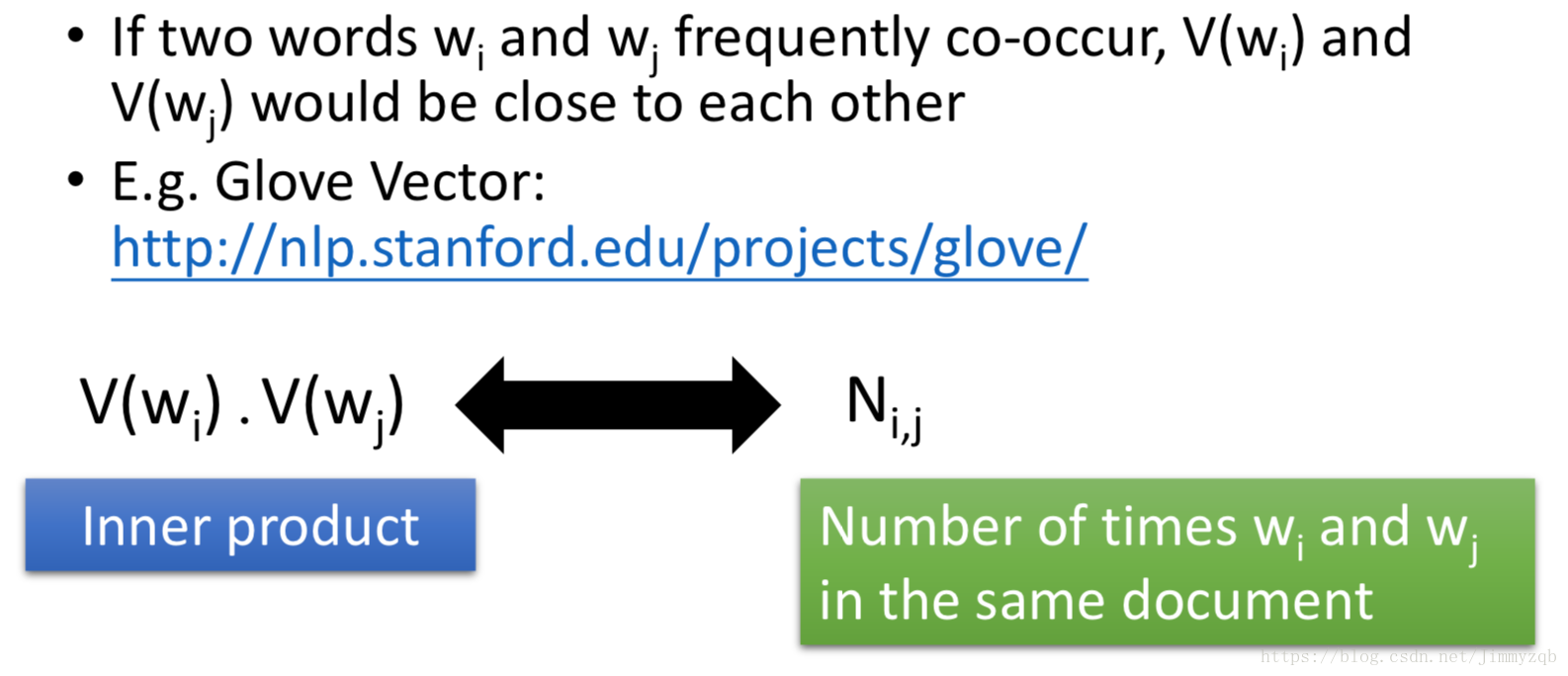
Count based寻找词汇向量
的思路就是如果
两个词汇经常一起出现,则两者的词汇向量
应该很接近。算法执行就是让的
内积和两个词汇出现在同一篇文章中的次数
接近,从而找到
。
Perdition based
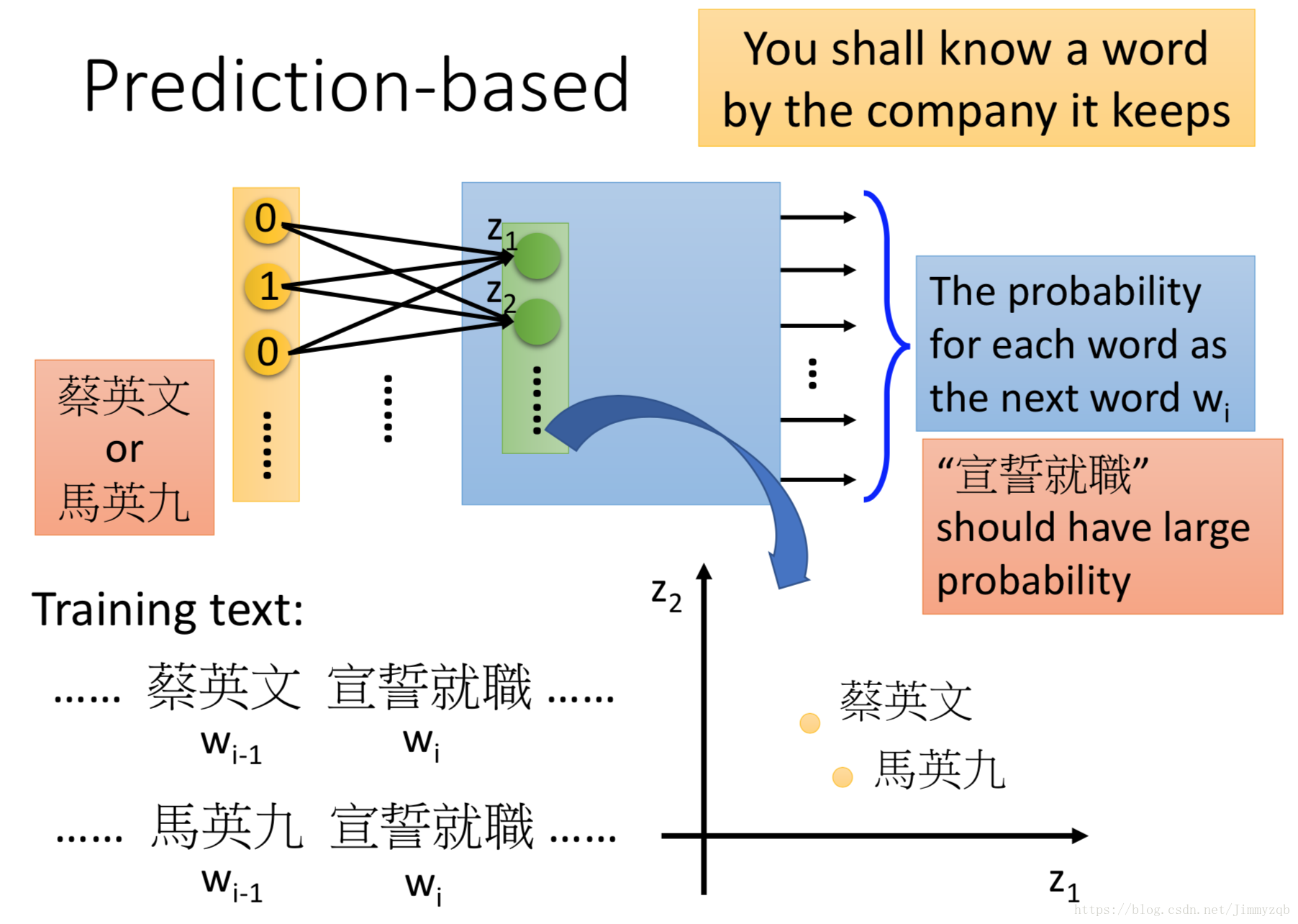
Perdition based即预测词汇出现后的下一个词汇,如下例。

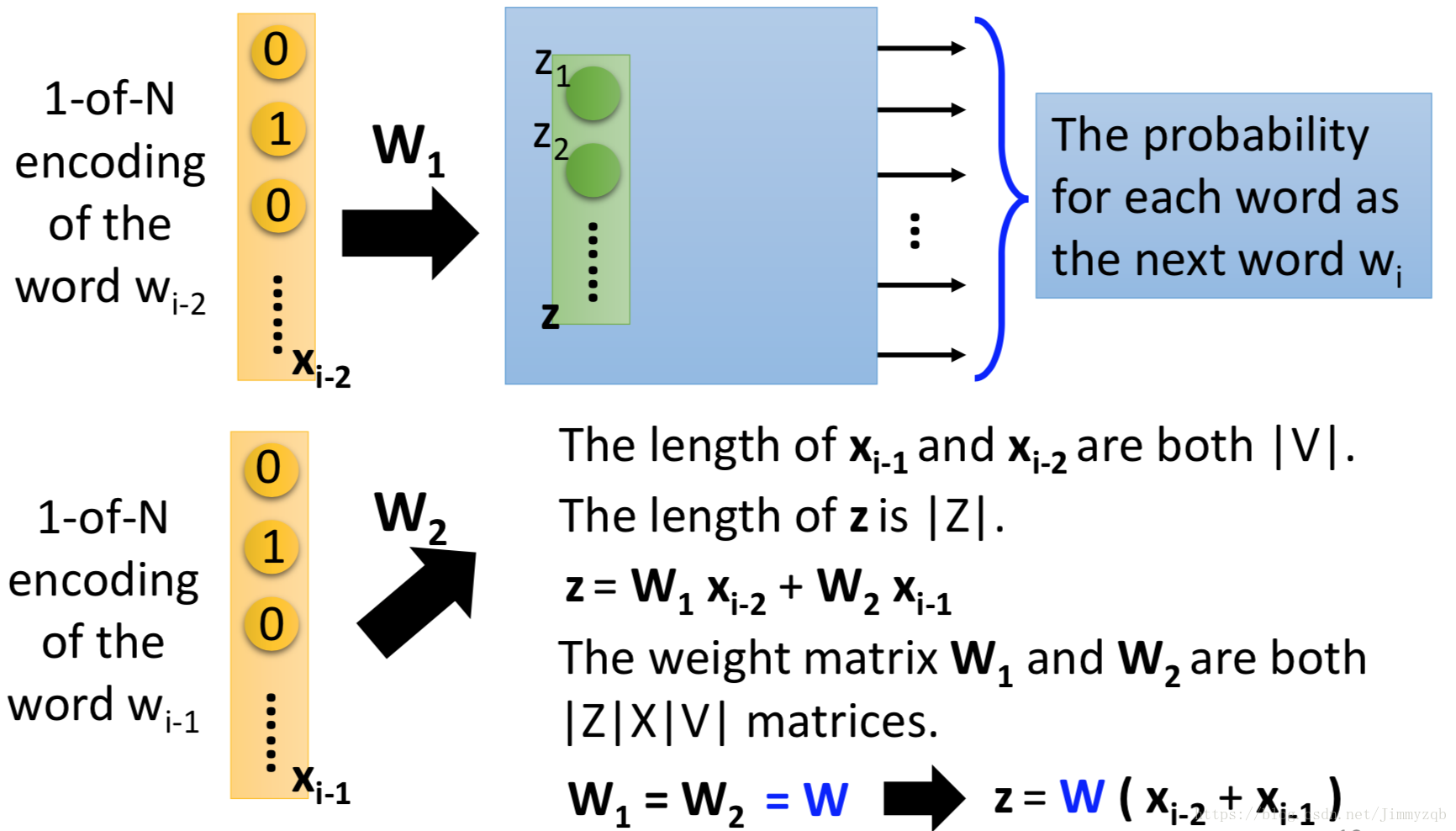
使用神经网络模型实现算法如图:
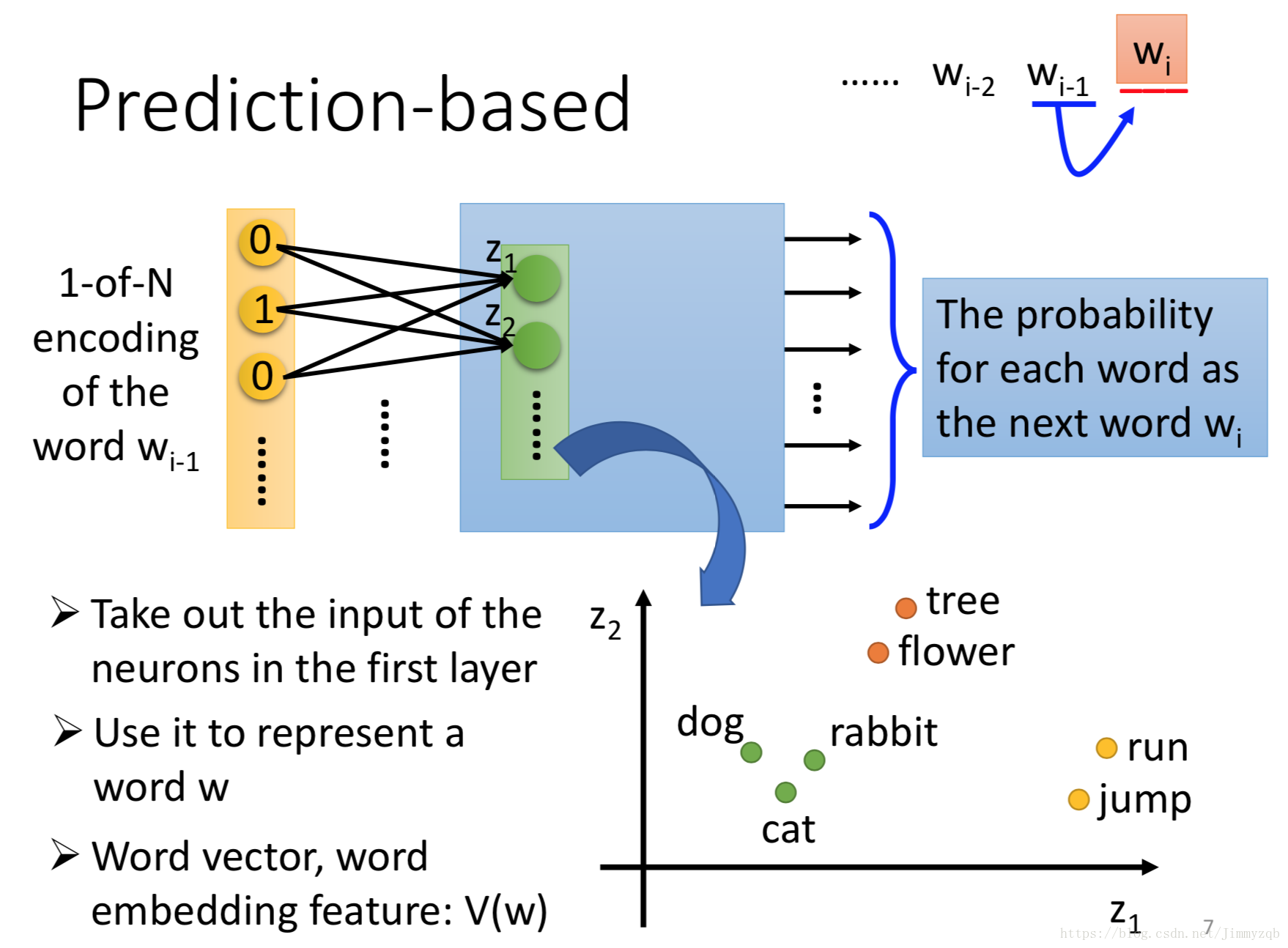
直观地举例理解,对于这个例子,“蔡英文宣誓就职”和“马英九宣誓就职”,我们希望不管输入“蔡英文”还是“马英九”,“宣誓就职”这一词汇都有比较大的概率,因此得出来的
函数空间里“蔡英文”和“马英九”两个向量点应该是很接近的:
现在考虑到前面两个词汇
,为了减少参数过多,令
。