引言
本文主要探讨了什么是迁移学习,以及它的主要思想和例子。
迁移学习
什么是迁移学习呢?

假设现在要做猫和狗的分类器,我们需要一样标签数据告诉机器哪些是猫,哪些是狗。
同时,假设现在有一些与猫和狗没有直接关系的数据,这里说是没有直接关系,并不是说是完全没有关系。就是说有一些关系,但又不是直接相关的。

假设现在有自然界真实存在的老虎和大象的图片,那老虎和大象对分辨猫和狗会有帮助吗。

或者说我们有一些卡通动画中的猫和狗图像,但不是真实存在的,有没有帮助呢。
迁移学习把任务A开发的模型作为初始点,重新使用在为任务B开发模型的过程中。迁移学习是通过从已学习的相关任务中转移知识来改进学习的新任务。
为什么用迁移学习

这三个说的是,第一个是做闽南语(台湾腔)的语音识别,但是没有太多的训练数据,只有很多无直接关系的英文、普通话数据;第二是做医疗方面的图像识别,同样样本不多,但有很多其他真实动物的图像;第三个说的是在特定领域,这里是法律方面的文本分析,缺少数据,但是可以找到很多不相关的网页数据。
这时候迁移学习就会很有用,因为可能实际情况就是这样,我们无法收集太多想要的数据,但是存在很多不直接相关的其他数据。
其实在现实生活中我们会做迁移学习(有点像类比的思想)。

这里用漫画家的生活对应到研究生的生活。漫画家要画漫画,研究生要跑实验等。
迁移学习的概述
我们主要把迁移学习分为四大类。
在迁移学习中,有一些arget data,就是和你的任务由直接关系的数据;
还有很多source data,是和你现在的任务没有直接关系的数据。
根据它们是否有标签,可以分成四类。

我们先看下target data和source data都是有标签的情况。
这种情况下我们可以做什么事情呢,一件事情是模型的微调(Fine-tuning)。
模型微调

假设你有一组大量的source data,和一组少量的target data。它们都是有标签的。
你可能听过单样本学习(one-shot learning):说现在的样本很少,只有几个或一个样本。
在语音识别中,我们有大量的source data,我们有几万个人说的不同的句子,并且知道这些句子是什么。target data是某个具体的使用者他说的话,和说的话对应的文字。
因为每个人发音都是不一样的,你拿一大堆人语音的数据训练出来的模型,对某个特定的使用者,可能并不是一定好的。所以我们期望说,假设特定的使用者可以对我们的语音识别系统说5句话,我们知道这5句话对应的文字。
有了这些少量的target data后,就可以拿这些数据让某个特定使用者的语音识别做得更好。这让我想到了"Hey,siri"初次启用时需要说几句话。
这里面的问题是target data数据量很少,所以我们需要特殊的处理方法。一个比较常见的方法叫保守训练(conservative training)。
保守训练
假设我们有大量的source data,比如,有大量的不同人说的句子。我们可以拿这些数据训练一个神经网络。

接下来我们有少量的某个人说的句子。我们可以拿soure data训练出来的NN,去初始化另外一个NN的参数,然后用少量的target data去微调这个新的NN的参数。

但是因为target data非常少,可能很容易过拟合。保守训练说的是我们在训练的时候必须要比较保守,比如,希望新的NN和旧NN不要相差太多。毕竟旧的NN是拿大量的数据训练出来的。
那怎么做呢,举例来说,希望这两个不同的NN,给它们同样的输入时,它们的输出不会有太大的差别;或者说新的NN的参数和旧的NN的参数不要有太多的差别。
或者在训练的时候做一些限制。
Layer Transfer
可以限制在对NN参数微调的时候,只调整某层的参数。

比如我们用大量的数据训练出左边的NN,左边这个NN的大部分参数可以直接复制到右边。然后固定这些参数,拿少量的target data来训练某层的参数。
如果今天target data你觉得足够多的话,也可以调右边整个NN的参数。
接下来的问题是应该调哪层的参数呢?
在不同的任务中会有不同的做法。
在语音识别中比较常见的是调第一层,因为我们相信每个人的发音可以做某种转换后,把它们都变成一样的。比如对男生和女生的声音做转化后,可以得到比较中性的声音。
所以在语音识别中,通常会训练比较接近于输入层的那几层。而在图像识别中,常见的是固定前面几层,只调比较接近输出层的几层。

在图像识别中,前几层可能只是检测比较基础的东西,比如说是简单的图案或纹路。这些简单的图案和你的任务是没有关系的,不同的任务可以共用训练出来的前几层的参数。
接下来我们介绍下多任务学习(Multitask Learning)
多任务学习
我们现在有多个不同的任务,我们希望机器能同时学会做好这几个不同的任务。
比如说你要训练某个人打篮球,同时要训练他唱、跳、Rap。
我们希望NN也能做到这件事情。

在这种神经网络的架构设计上可以是像上面这种。这里假设任务A和任务B可以共用同一组输入特征。就是这两个NN,它们前面几层是共用的,但是在某个隐藏层会产生两个分支,一条产生的是任务A的分支,另一条是任务B的。

那如果这两个任务的输入特征都不能共用呢,我们就可以采用上面的设计,在这两个NN中对不同的输入特征做一些转换,然后丢到共用的网络层中去,再从共用的层中分两个分支出来。
如果可以选择适当的不同的任务合在一起的话,是可以有帮助的。
什么样的任务可能有帮助呢,举例来说,现在在做语音识别的时候,我们不仅让机器学会某国语言的语音识别,我们让机器学会多国语言的。

此时,多任务学习就会有帮助。
这多国语言前面几层是共用的,因为不同的语音声音讯号是一样的(人类的语言都会有一些同样的特征,比如中文里面的嘿和英语里面的hey发音很像)。
从这些共用的层出来后分成多个分支,分别做不同国家语言的语音识别。
这整个NN可以同时一起训练,这时候学出来的效果比只用一种语言还要好。
这里是文献上的实验的例子,纵轴是错误率,横轴是中文语言识别训练的数据量。

从实验结果看到,如果仅让机器学中文的话,就是蓝色的线,它达到红线交点处的错误率需要的中文数据量会超过同时与欧洲语言一起学习的数据量。并且可以看到橙色的曲线是在蓝色曲线的下方,说明效果更加好。
还有另外一个任务学习方法叫渐进式网络。
渐进式神经网络(Progressive Neural Networks)
渐进式神经网络说的是,我们希望机器学习先学任务A,再学任务B。在任务A中已经学过了,在任务B中也可以学得比较好。
我们在生活中会碰到这样的例子,例如,我们可能会发现学习识别苹果可能有助于识别梨,或学习弹电子琴有助于学习弹钢琴。
但是,这时会有个问题是,在做好任务B后,任务A会不会反而忘了。就是先学会打篮球,再去学习唱、跳、RAP,后面会不会忘了打篮球了。人一般不会这样,但是神经网络可能会。
如何防止出现这个问题呢。有人就提出了渐进式神经网络。

现在有个NN,它先学会了任务1,接下来希望机器从任务1学到的东西可以对学习任务2会有帮助,但又不希望它忘掉在任务1中学到的东西。

在渐进式神经网络中,任务2用另一个NN来做,注意这里不同的任务输入的特征可以不同,如果今天只是独立训练任务2的话,那么学会了任务2的网络就不知道任务1。
所以任务2的网络会把任务1的网络每个隐藏层的输出,也当做是它的每个隐藏层的输入。但是在做反向传播的时候,任务2的网络只会单纯的调整自己的参数,不会去调整任务1网络的参数。这样就可以确保,机器不会忘记任务1,因为任务1的参数是固定了的。

如果还要第三个任务要怎么办呢,那就把前两个任务的输出当成新任务网络隐藏层的输入。依此类推。但这样会随着任务的增多,整个网络会变得越来越大。
这时又有人提出了一种新的网络,它做的事情和渐进式网路一样,只不过它的参数不会越来越多。

它的核心思想是先找一个比较大的网络,然后第一个任务只选网络中的某一部分的参数来做训练,在任务1结束后会固定它调整后的参数;接下来再让第二个任务去学这个大网络中剩余的参数。因为一开始的大网络就确定下来了,所以随着任务的增加,整个网络也不会扩张。
上面介绍的都是source data和target data有标签的情况,那如果只是source data有标签,target data无标签呢。
Domain-adversarial training

在概念上你可以把有标签的source data当成训练数据,把无标签的target data当成测试数据,但是这样的效果肯定是很差的,因为它们的分布不同。
假设今天要做手写数字识别,你有有标签的MNIST的数据,但是你要识别的对象是无标签的来自MNIST-M的数据,在MNIST-M中的数字甚至是彩色的,它的数据样本分布和原来的MNIST分布不一样。

所以需要特别的处理。Domain-adversarial training就是干这件事的。Domain-adversarial training可以看成GAN的一种。它想要把source data和target data转换到同样的领域上,让它们有同样的分布。

如果我们没有对数据做任何处理,单纯的拿source data来训练一个分类器,它输入是一个图像,输出是该图形的类别。那今天得到的特征分布可能是下面这样子。

MNIST的数据它是蓝色的点,确实可以看到它们分成一群一群的,把几群数据的点拿出来看的话,得到的结果可能是左边的样子,能区分出4,0和1。 但是把和MNIST分布不同的MNIST-M手写数字的图片丢到这个分类器中去,这些不一样的图片,它们的特征分布可能像红点一样。可以看到,红点和蓝点根本没有交集。
如果今天这个NN无法用同样的特征表示这两种数据,那么就会无法得到好的分类结果。
怎么办呢

我们希望在一个NN中,前面几个网络层做的事是特征抽取,也就是说,希望这个特征抽取器能把不同领域的source data和target data都转成同样的特征。

也就是我们希望说,红点和蓝点的分布不是上面这样,而是像下面混合在一起。

那怎么让我们这个特征抽取器做到这件事情呢。
这里需要引入一个领域的分类器(domain classifier),就像我们做GAN的时候引入的鉴别器。它也是一个神经网络。

这个领域分类器的作用是,要侦测出现在特征抽取器输出的特征是属于哪个领域的(来自哪个分布的)。现在特征抽取器要做的事情是尽量骗过这个领域分类器,而后者是尽量防止被骗。
特征抽取器要做的是去除source 领域和target 领域不一样的地方,让提取出来的特征分布是很接近的,可以骗过领域分类器。
但是如果只有这两个神经网络是不够的。因为绿色的特征抽取器可以轻易的骗过红色的分类器,只要它不管输入是什么,只把所有的输出都变成0就可以了。

所以需要引入另外一个东西叫标签预测器(Label predictor)的东西。
现在特征抽取器不仅要骗过分类器,还要让预测器尽量有准确的预测结果。这是一个很大的神经网络,但是这三个不同的部分有不同的目标。
预测器想要正确的分类输入的图片,分类器想要正确分别输入是来自哪个分布。它们都只能看到特征抽取器抽取后的特征。
抽取器一方面希望可以促使预测器做的好,另一方面要防止分类器做的好。
那么要怎么做呢

一样用梯度下降来训练,红色的分类器部分要调整参数,去让分辨领域的结果越正确越好;蓝色的预测器需要调参数,让标签的预测正确率越高越好;
这两者不一样的地方在于,当分类器要求绿色的抽取器去调整参数以满足以及的目标时,绿色的抽取器会尽量满足它的要求;还当红色的神经网络要求绿色的神经网络调整参数的时候,红色的网络会故意乘以 ,以防止分类器做的好。
最后红色的神经网路会无法做好分类,但是它必须要努力挣扎,它需要从绿色的NN给的不好的特征里面尽量去区分它们的领域。这样才能迫使绿色的NN产生红色的NN无法分辨的特征。难点就在于让红色的NN努力挣扎而不是很快放弃。
Zero-shot Learning
零次学习(Zero-shot Learning)说的是source data和target data它们的任务都不相同。

比如source data可能是要做猫和狗的分类;但是target data要做的是做草泥马和羊的分类。

target data中需要正确找出草泥马,但是source data中都没出现过草泥马,那要怎么做这件事情呢
我们先看下语音识别里面是怎么做的,语音识别一直都有训练数据(source data)和测试数据(target data)是不同任务的问题。 很有可能在测试数据中出现的词汇,在训练数据中从来没有出现过。语音识别在处理这个问题的时候,做法是找出比词汇更小的单位。通常语音识别都是拿音位(phoneme,可以理解为音标)做为单位。
如果把词汇都转成音位,在识别的时候只去识别音位,然后再把音位转换为词汇的话就可以解决训练数据和测试数据不一样的问题。
其实在图像上的处理方法也很类似。

如果让机器识别不同的动物,而有些动物只在测试数据中出现,那怎么识别这些没有在训练数据中出现的动物呢。同样要找出更小的识别单位,可以是动物的特征:有毛(furry)、四只脚(4 legs)、有尾巴(tail)。
如果是狗它都具备这三个特征;鱼只有尾巴具备;而猩猩只是毛茸茸的,没有四只脚,没有尾巴。
通常需要足够多的特征,让每个类别都有独特的特征。
现在不直接让机器学习输入的图片属于哪一类,而是让它学习它有哪些特征。

在测试时,如果有个动物在训练集中从没有出现过,那也没关系。因为我们只要找到这张输入的动物图片有哪些特征。

另外一种做法是把属性(特征)和图像都投影到同一个嵌入空间(Embedding Space)。

我们要先学习一个函数
,这个函数可以是DNN,把某张图片
丢进去可以得到一个向量,同理把
丢进去也能得到一个向量(图中橙点表示)。现在把每只动物的属性也表示成向量,把这个向量通过另一个函数
投影到同一个空间上。就是说,这两个函数输出的维度是相同的。

在训练的时候,要调整 和 的参数,让 投影到这个空间的向量和 投影到这个空间的向量越接近越好。
如果找到这样的 和 以后,有张新的图片 进来,就算你的训练数据中没有这种动物,我们也可以通过 这个函数把它变成这个空间中的一个向量,我们再看这个向量和哪一组属性比较接近。最接近的属性所对应的动物,就是 的类别。

那怎么训练呢
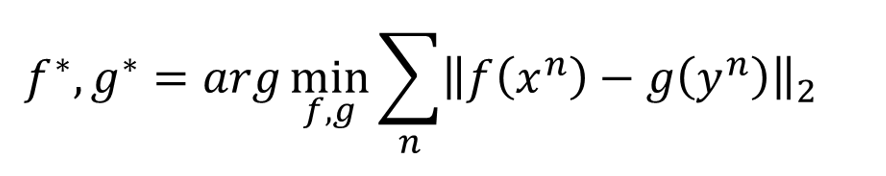
有一种方法是这样的,调整
的参数,使它们对于训练数据中的所有数据,得到的结果越接近越好。但是如果要最小化这样一个方程的话,可能导致的结果是
的输出永远都是
。
但是仅这样是不够的,我们在学习的时候,不仅要使 和 越近越好,还要让 与无关的 越远越好。

上面是一个可能的做法,
叫做margin(感觉点像阈值),取
和后面那项的最大值,对于所有的样本。也就是说,后面这项大于0的时候才会有loss,小于0的时候没有loss。
所以希望后面这项小于0

就是让 与 的内积减去 与 的内积要大于 ,注意这里要穷举所有可能的 以找打最大的内积。
这整个式子说的是我们希望 与 越近越好,而 与 要足够远,至少距离要大于一个 。
那假设我们今天连动物的属性都不知道的话,我们可以用动物的名字来做词向量,把这些词向量丢到 中去即可。

刚才说的都是需要训练一个 和 。我们现在考虑的是Zero-shot问题,也就是说可能我们连一个数据都没有,有个方法可以做Zero-shot 学习,而且不需要额外的训练。

直接拿一个现成的图像识别系统,把一张图像丢到这个系统中,它输出是狮子和老虎的概率都是 。接下来找出狮子和老虎的词向量,然后根据它们在这个系统输出的概率,做weight sum,就是乘以权重加起来。这时得到黑色的点。

接下来再找与这个黑色的点最接近的词向量,可能找出来的是liger(狮虎兽)。
在这个例子中,只需要一个NN,和一组词向量,其他都不需要,也不需要训练。
接下来举个文字翻译的例子。

现在有英文翻译成韩文(英文->韩文),韩文->英文,英文->日文,日文->英文,这些转换的训练数据,但是没有从日文->韩文的训练数据,没有韩文->日文的训练数据,机器都可以翻译。
虽然机器从来没有被教过怎么从韩文->日文,但是机器在翻译不同语言的过程中,它已经学到了要把不同的语音投影到共同的空间中去,接下来做翻译的时候,再根据投影的结果,把输入的文字翻译成另外一种语言。
可以理解为,不管是英文、日文还是韩文,输入到这个机器翻译系统里面去,都会被翻译成一种共同的语言,接下来机器再去学,如何从这种共同的语音翻译成英文、韩文、日文。
其实这种共同的语言是一种embedding。

这是embedding的结果,左边是 embedding space,其中每条由点连成的线都是一个句子,比如把这一小块的句子拿出来。

然后会发现
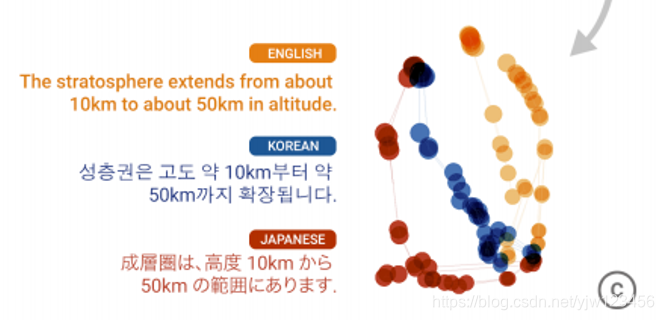
红色点连成的线代表是日文,蓝色的代表是韩文,橙色的代表是英文。
这三句话虽然语言不一样,但是有共同的意思,所以机器在表达这些语言是,会给它们共同的表示。
自我学习
自我学习(Self-taught learning)其实和半监督学习很像,都是有少量的有标签数据,和非常多的无标签数据。但是与半监督学习有个很大的不同是,有标签数据可能和无标签数据是没有关系的。
自学成簇
如果target data和source data都是无标签的话,可以用Self-taught Clustering来做。
可以用无标签的source data,可以学出一个较好的特征表示,再用这个较好的特征表示用在聚类上,就可以得到较好的结果。
参考
1.李宏毅机器学习
