引言
主要讲了集成学习(Ensemble)
集成学习的框架
集成学习体现了一个团队合作的思想。

(这里我改了一下李宏毅老师的例子,改成了LOL)。
假设你有很多分类器,每个分类器扮演不同的角色,比如在LOL中,有的分类器是ADC,有的是TOP。这些分类器应该具有一定的差异性。

把这些角色都集合在一起,形成配合,比如SUP控制,TOP抗,ADC输出。
在Ensemble中有很多不同的方法,先来看下Bagging方法。
Bagging

先来回顾下模型的偏差和方差。
假设有个简单的模型,它有很大的偏差(都没打到靶心),但是方差比较小(比较集中)。就是如上图红框所示;如果是复杂的模型,一般会有小的偏差,但是方差较大。如上图紫框。
上面的趋势图中,横坐标是模型的复杂度,纵坐标是模型的错误率。可以看到,错误率先是随着模型复杂度的增加而减少,随后变成上升。

假设在不同的宇宙里面都在抓宝可梦,每个宇宙都可以得到一个模型。每个宇宙预测宝可梦的模型都不一样,我们可以把不同的模型都结合起来(输出就均值),得到新的模型
,这个新的模型可能就会很接近真实模型。
虽然我们不可能从不同的宇宙取收集数据,但是我们可以创造出不同的数据出来,再用不同的数据集,各自去训练一个复杂的模型,虽然每个模型单独看的话方差很大,但是把不同的模型结合起来后,它的方差就不会那么大。
怎么制造不同的数据呢

假设你有N笔训练数据,从这N笔训练数据中取样
笔,通常
可以等于
,因为Bagging是放回取样,很大的可能会重复取数据。
这里假设我们做4次这样的取样,就可以得到4份训练数据,然后分别训练4个复杂的模型。

在测试的时候,可以用同一份测试数据对这四个模型进行测试,然后结合它们的输出。这里的方法有投票(分类)或求均值(回归)。
当你的模型很复杂,容易过拟合时,可以做Bagging来减低方差。
那什么样的模型容易过拟合呢,最容易过拟合的其实是决策树。
决策树可以在训练数据上拿到100%的正确率。
决策树做Bagging就可以得到随机森林。
初音实验

初音数据下载地址为: http://speech.ee.ntu.edu.tw/~tlkagk/courses/MLDS_2015_2/theano/miku
这里以初音图像作为决策树分类的应用例子,这个例子输入是二维(图像的坐标),红色部分是初音轮廓的填充,标记为类别1(乘以255后变成了白色),蓝色部分相当于是背景,标记为类别0(0灰度值代表黑色)。 相当于输入是坐标,输出是该点为白色还是黑色。
import pandas as pd
import numpy as np
from PIL import Image
# 1st column: x, 2nd column: y, 3rd column: output (1 or 0)
miku=pd.read_csv('miku.csv',sep=' ',header=None)
miku = np.array(miku.values)
miku_grayscale = miku[:,2]#得到类别
miku_grayscale = miku_grayscale.reshape((500, 500))#总共250000份数据
miku_grayscale = miku_grayscale.transpose()#这里进行装置,不然图像是倒着的
image = Image.fromarray(miku_grayscale*255)#*255得到灰度值
image.show()
关于sklearn中决策树代码是如何使用的可以参阅机器学习入门——图解集成学习(附代码)
这里我们跟着李宏毅老师来实作下这个例子,加载初音数据并展示的代码如上。

接下来,用不同深度的决策树来看下分类效果。
先定义显示图像的函数:
def show_image(data):
data = data.reshape((500, 500))
data = data.transpose()
image_show = Image.fromarray(data*255)
image_show.show()
然后先用一颗深度为5的决策树进行分类:
from sklearn.tree import DecisionTreeClassifier
dt_clf = DecisionTreeClassifier(max_depth=5)
# 拆分输入和输出
miku_data = miku[:,0:2]#输入:坐标
miku_target = miku[:,-1]#输出:黑或白
dt_clf.fit(miku_data, miku_target)
predict = dt_clf.predict(miku_data)
show_image(predict)

下面分别是深度为5,10,15,20的结果。

当深度为20的时候,就可以完美的画出初音的样本,其实这也没什么,因为决策树能达到错误率是0。
因为决策树太容易过拟合,所以在测试数据上如果只用一颗决策树,往往很难达到比较好的结果。
所以我们要结合多颗不同的决策树,通过Bagging的方式结合的决策树就是随机森林。

通常做训练决策树模型的时候,除了采用Bagging的方法,还随机限制了特征,每次只取部分特征(虽然这里只有两个特征),这样得到的模型更具有差异性。
通过采用Bagging的方法会有一些没有被取样的数据,称为Out-Of-Bag。可以通过这份数据进行测试,这样就可以不单独的分出测试数据集,留更多的数据给训练数据。
单一随机树的话,上面我们用一颗深度为20的决策树才能得到最好的结果,那如果是用随机森林呢。
下面通过随机森林的方式来对初音轮廓进行分类:
from sklearn.ensemble import RandomForestClassifier
rnd_clf = RandomForestClassifier(n_estimators=100,max_depth=5,n_jobs=-1) # n_jobs=-1指定cpu核数,可以并行训练
rnd_clf.fit(miku_data, miku_target)
predict = rnd_clf.predict(miku_data)
show_image(predict)

这里用100颗深度为5的树,得到的结果如上,可以看到,结果也是很差,但是比单独一颗深度为5的树结果更加平滑。因为这里只是将100颗树的分类结果平均起来(投票)。
所以,我们保持100颗树不变,增加深度为10,分类结果:

可以看到大概的轮廓了,但是怎么少了一只脚。和单独一颗决策树比起来的话,结果很明显更加平滑,也就是不容易过拟合。
深度为15呢?

最终深度为20:

可以看到随机森林会让分类的结果更加平滑,也就是可以减少模型的方差,要想得到好的结果,还是要用到较好的模型(比如这里深度为20的决策树)。
下面我们介绍一个牛逼的方法,可以通过一个一般的模型(深度为5的决策树),最终得到一个非常好的模型。
Boosting
通过提升方法可以将多个比较弱(分类准确度不高,但是至少要比随机好)的模型,集成成一个分类性能很好的模型。

上面说的是只要你能提供分类准确率高于50%的分类器,通过Boosting方法最终就能得到错误率为0的分类器。
要怎么做呢,首先得到第一个分类器
,这个分类器可能只是高过50%,分类效果不好没关系;
然后Boosting帮你找到另一个分类器
来提升
分类不好的部分;
最终,组合所有的分类器。
这里会训练很多个基分类器,每个基分类器都是基于上一个分类其训练的,因此它们是顺序训练的,无法进行并行训练。
关于提升算法《统计学习方法》这本书就写的不错,博主也做了笔记,感兴趣的可以参阅一下。
如何得到不同的分类器
在Bagging中我们学习过可以通过训练不同的训练集来得到不同的分类器。
在提升方法中说过通过分类器 可以得到分类器 ,通过 也可以得到 …
那是怎么做的呢
这里要给每笔数据一个权重,这了初始化权重为 ,通过 表示。可以通过改变权重来制造不同的数据集。

比如这里有3笔数据,初始权重都为
,如果我们改变权重,就可以得到不同的训练数据。

改变权重后,对训练其实也没有太大的影响。在训练时,每笔数据的结果前乘上权重即可。

如果有笔数据的权重比较大,那么在训练的时候就会多考虑一点。
下面就开始学习提升算法中的经典算法——AdaBoost
AdaBoost的思想
主要思想就是在上一个分类器分类错误的样本中训练新的分类器。
当然你需要提供第一个分类器,只要比随机效果好就行了,比如二分类问题中,高于50%就行。
先来看下如何计算第一个分类器
的错误率:

这里的
其实就是指数函数,国内书籍一般是用
表示。这里相当于只是计算了分类错误的样本权重之和,再除以所有权重之和。
这里相当于做了一个归一化。这里错误率要小于50%(这里说的是二分类问题,如果错误率大于0.5,只要把输出反过来就可以了)。
接下来就通过下面的式子更新每笔数据的权重:

用 作为新数据的权重,使得 在新的训练数据上的结果为0.5,接下来就用这个权重 训练 , 的计算方式和 一样, 计算的是 之和。
这里看起来真的不容易理解,下面通过一个例子可以帮助大家理解。

假设有4笔训练数据,开始时权重都是 ,然后用这份数据来训练一个模型 ,这里假设它只在第2笔数据上分类错误。所以它的错误率是0.25。
接下来修改权重,使得 在这些新权重上的错误率为0.5。
要用 的错误率变大,也就是让分类错误样本的权重变大,让分类正确样本的权重变小。
比如你得罪了一个老师,然后你做的卷子分数还不错,但是还没达到满分,但是这个老师为了整你,故意将你答错题目的分数调高,将你答对题目的分数调低,这样最终你的分数就会变低。
所以还是在绝对的实力面前(你考得满分),任何计谋都没用了。

这里假设是这样修改了权重,3个正确的权重才等于一个错误的权重,这样使得
在上面的分类错误率为0.5。
接下来,在这组新的训练数据上面,训练 ,相当于是让它重点考虑上一个分类器分类错误的部分。
上面只是讲了一个思想,那实际上是怎么做的呢

如果某笔数据 被 错误分类,那么就把该笔数据的权重乘上一个值 (大于1),使得权重增加;
如果某笔数据 被 正确分类,那么就把该笔数据的权重除上一个值 (大于1),使得权重减少;
这样就可以得到每笔数据新的权重 ,然后基于这个权重来训练 ,那 的值要怎么取呢
和上面的公式一样,我们要得到 使得 在上面的错误率为0.5。

因为上面用了指示函数,分类正确的指示函数结果为
,因此实际上考虑的是分类错误的样本权重。上面分子的地方可以写成:
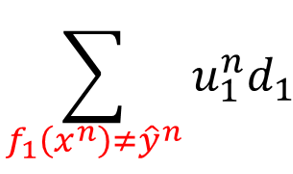
分母
还是所有的权重之和,包括分类正确的和错误的,也就可以写成:

所以整个式子就是下面的样子:

两边都取倒数得:
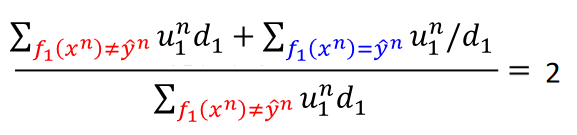
然后可以约掉相同的项,

也就是:
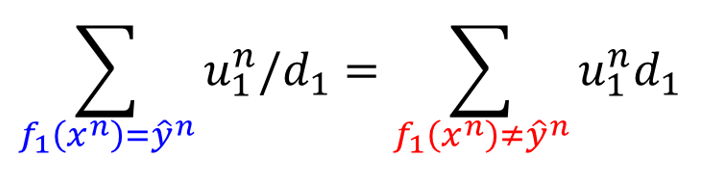
(注意求和下面的条件,左边说的是分类正确的样本,右边说的是分类错误的样本)。
接下来分别把 和 提出来。
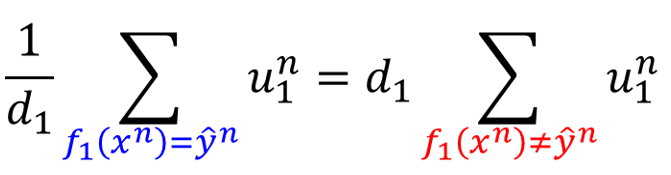
根据之前的式子,错误率可以写成这样:
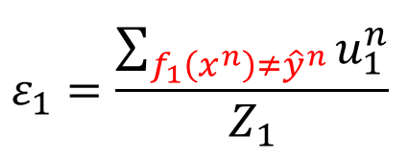
它的分子出现在上面倒数第二个图右边。
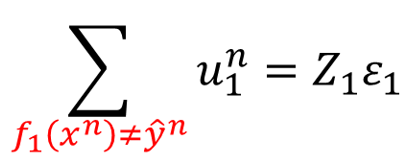
把分母乘过去就得到上式,带入之前的等式。而
就是1减去正确率。

也就是:
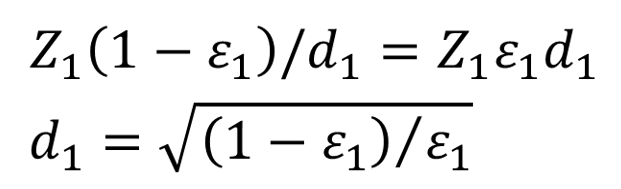
最终可以算出
的式子。
因为错误率是小于0.5的,所以 一定大于1。
整个AdaBoost的算法如下:

这里重点说下上面红框框出来的部分,其实就是我们上面推导的那个式子,不过引入了
,
。
利用了
来表示除法运算,简化最终的式子。
如果
和
同号,就是分类正确,相乘就是
(基于
),前面有个负号,就变成了除法的形式;反之分类错误,就是直接相乘。这样就写到了一个式子中。
(算法还没完)
经过上面的训练后,可以得到一把分类器,下面如何把它们集合在一起呢
因为我们的分类器有好有差,我们希望它们对最终结果的影响是不同的,因此很容易想到的是要加个权重。其实这个权重上面已经计算过了,就用
即可。
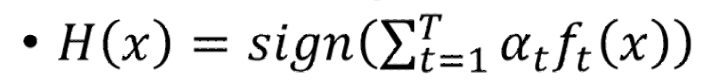
如果某个分类器的错误率比较低,比如是0.1,那么它得到的权重会是1.1。

如果错误率较大,比如0.4,得到的权重会是0.2。
因此,错误率小的分类器在最终投票会具有更大的权重。
这里应该有个例子,推荐去看《统计学习方法》——提升算法,博主通过代码实现了书中AdaBoost的例子,可以结合上面的理论和代码很容易的理解AdaBoost的思想。
证明

这一小节是证明AdaBoost算法在迭代次数(子模型数)越来越多的情况下,最终分类器
的错误率越来越小。

我们先列出这个错误率的计算公式。
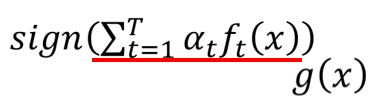
然后用 表示上面括号内的这一项。
所以错误率的这一项可以写成:

这里利用了
与
同号(分类正确)为
,异号为
改成了小于零。

然后说这个错误率有一个上界。为什么呢,这里通过画图来说明。

可以看到蓝线始终在绿线上方,所以是它的上界。接下来证明这个上界会越来越小。
我们先来计算 ,就是 的权重之和。
那
是怎样的呢

我们知道在初始的时候权重都为
。
通过AdaBoost的思想这一节我们知道了 的计算式子:
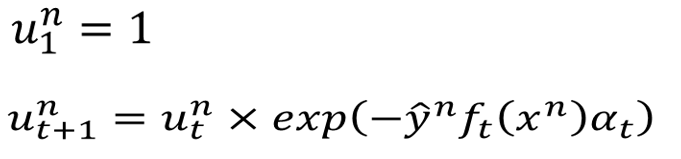
也就是第 个时间点的权重与第 个时间点的权重之间有上面这样的关系,我们就可以得到 的式子:
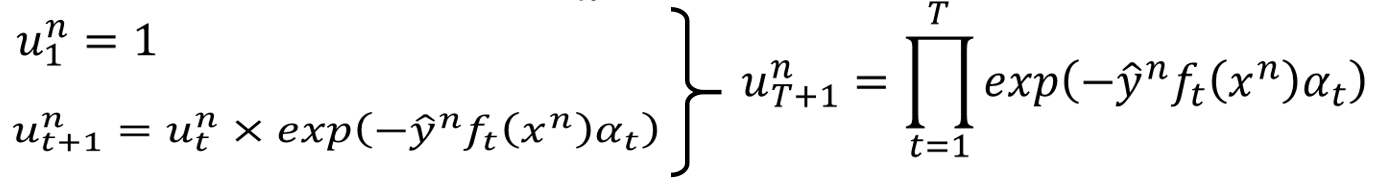
所以就可以得到 的表达式:

我们可以把连乘放到
里面,变成了求和。

红线标出来的这一项就是
。

并且篮筐框出来的其实就是一样的,也就是错误率小于等于下面这个

可以发现权重之和竟然与训练数据的错误率有关。
接下来要证明这个权重之和会越来越小。
我们可以写出
的式子。

带入
的式子得:

最终化简得到最后一个式子

它的函数图像是这样的,当错误率等于0.5时,取最大值1。而我们知道错误率是小于0.5的,所以 会比 还要小。
的式子可以写成:
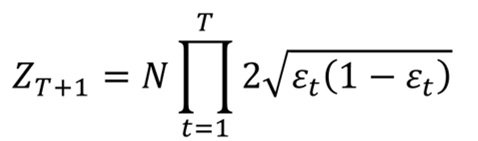
其中
是
。

所以随着迭代次数
的增加,错误率是越来越小的。
证明完毕。
用AdaBoost对初音进行分类
这里我们保持深度不变,采用一个比较弱的分类器,验证通过增加子模型的数量就可以提升最终分类器的性能。
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
miku=pd.read_csv('miku.csv',sep=' ',header=None)
miku = np.array(miku.values)
# 拆分输入和输出
miku_data = miku[:,0:2]#输入:坐标
miku_target = miku[:,-1]#输出:黑或白
forest_clf = AdaBoostClassifier(DecisionTreeClassifier(max_depth=5), n_estimators=10)
forest_clf.fit(miku_data, miku_target)
forest_predict = forest_clf.predict(miku_data)
show_image(forest_predict)

10个看起来结果很差,保持深度不变,将基分类器数量改成20(n_estimators=20):

20个轮廓很明显了,再试下50个基分类器:

50个基分类器的时候提升还是很明显了,但是还不是最好的,我们直接改成100看下(训练时间也会相应的增长):

可以看到,100个深度为5的决策树通过AdaBoost的方式集成起来后,效果已经很接近深度为20的决策树一样好。也就是我们不需要分类效果特别好的模型,直接集成多个具有差异的一般模型就能得到很好的结果。这就是集成学习的威力。
虽然100个深度为5的决策树已经很好,但还不是最好效果,如何达到最好效果呢,这里直接增加基分类器的数量为200:

除了增加基分类器的数量外,还可以尝试提升基分类器的性能,这里可以通过增加决策树的深度来实现,我就不演示了。
Gradient Boosting
刚才提升算法更通用的版本

怎么找到比较好的
呢
要先设一个目标函数
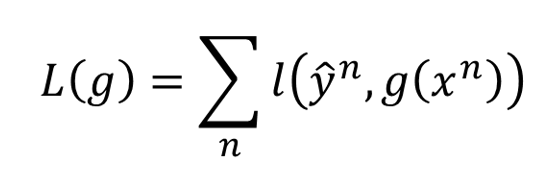
这里
是损失函数,可以这样定义:
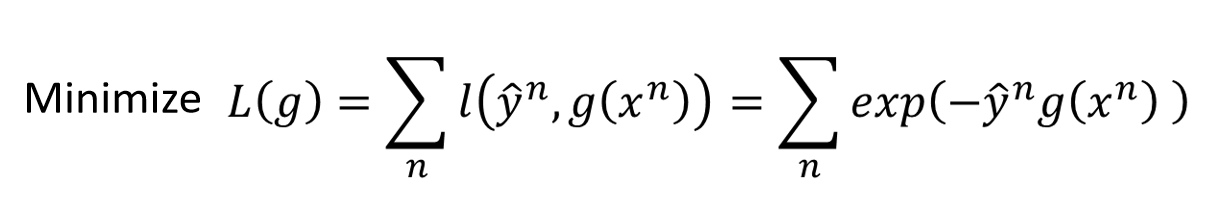
这样,我们希望
与
要同号,并且相乘的结果越大越好。
我们可以通过梯度下降法来最小化。

这里函数
如何求
对它的微分呢。可以把它的每个点当成参数,取
得到
,取
得到
,假设
取得很密,那么
就是一个向量。

如果从提升算法的角度来看,我们知道提升算法要找一个
和
。我们希望红框这两项表示同一个意思,至少它们的方向要一样。
我们知道
的式子是这样的
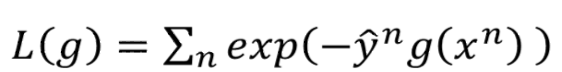
让它对
求导,得到:
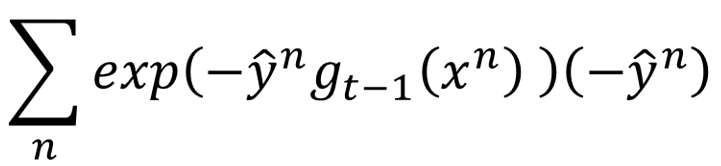
消掉学习率前面的负号就得到

我们希望
和这个式子方向越一致越好。每个函数可以想象成一个无穷多维的向量,上面两个式子都是一个向量。如果我们只考虑训练数据中的那些情况,那么它们的维度就是有限的。

就是想要上面这个式子的值越大越好,

我们希望对每笔训练数据来说,
和
是同号的,并且前面都乘以一个权重。

把 的式子代入,就得到上式。把求和变成连乘。

可以发现它就是AdaBoost的权重。

所以我们今天找出来的
相当于AdaBoost中的
。
在AdaBoost中找
可以想成是做梯度下降一样。
相当于是学习率,给定了 后,我们要找到一个 使得 的损失最小。
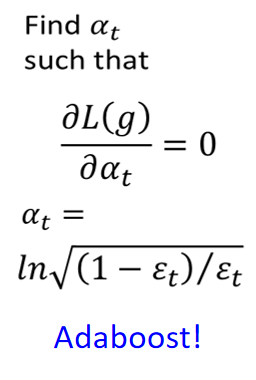
就是要计算
对
的微分,最终可以得到
所以可以把AdaBoost想象成是在做梯度下降。
参考
1.李宏毅机器学习

 博客专家
博客专家