引言
要介绍半监督学习(Semi-supervised learning)需要先介绍下监督学习(Supervised learning)。
- 监督学习: 假设有 笔训练数据,每笔训练数据都有对应的输出 (标签/类别)
- 半监督学习:
有另外一组没有标签的数据
- 通常 ,没有标签的数量远大于有标签的
- 直推学习(Transductive learning) : 学习过程中所考虑的未标记样本恰是待预测数据
- 归纳学习(Inductive learning):训练数据中的未标记样本并非待测的数据
为什么做半监督学习?
- 数据数据很容器,但是收集有标签的数据很麻烦
- 人类一直在做半监督学习
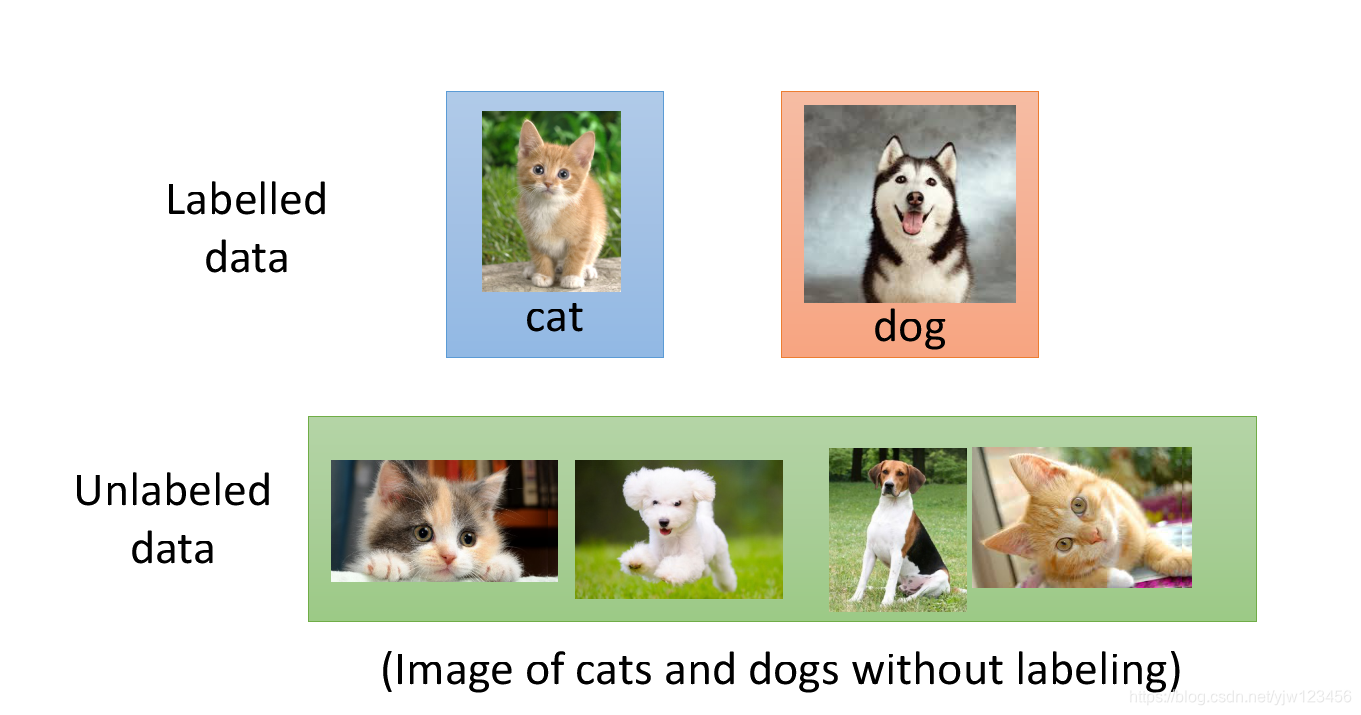
假设我们要做分类的项目,要建一个猫和狗的分类器,同时有一大堆有关猫和狗的图片,但是这些图片是没有关于哪些是猫哪些是狗的标签的。只有少一部分是有标签的。
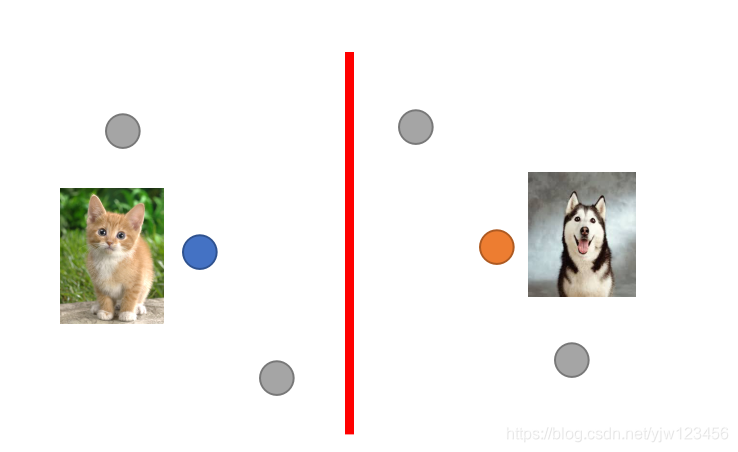
假设我们只考虑这些有标签的数据,然后需要找到一个边界,将猫和狗的训练数据分开。可能会像上图红线那样画。如果哪些未标记的数据的分布像是灰色点那样,
虽然这些灰色点没有标签,但是它们还是可以告诉我们一些信息。比如你可能会改成下面这样划分。

半监督学习使用无标签的数据往往伴随着一些假设,这些假设的精确程度会影响半监督学习的有用程度。

可能红框的那个灰点实际上是狗,它们因为背景都是绿色的而看起来很像。
半监督学习中的生成模型
先来回顾下监督学习中的生成模型。

假设有有标签的训练数据 属于类别 或
- 估测 和
- 假设每个类别的分布都是高斯分布,它们分别由 和 生成出来
有了这些参数后,就可以做分类问题,就可以计算一笔新的数据属于哪个类别的概率大。
如果给了很多无标签的数据,它们就会影响判断。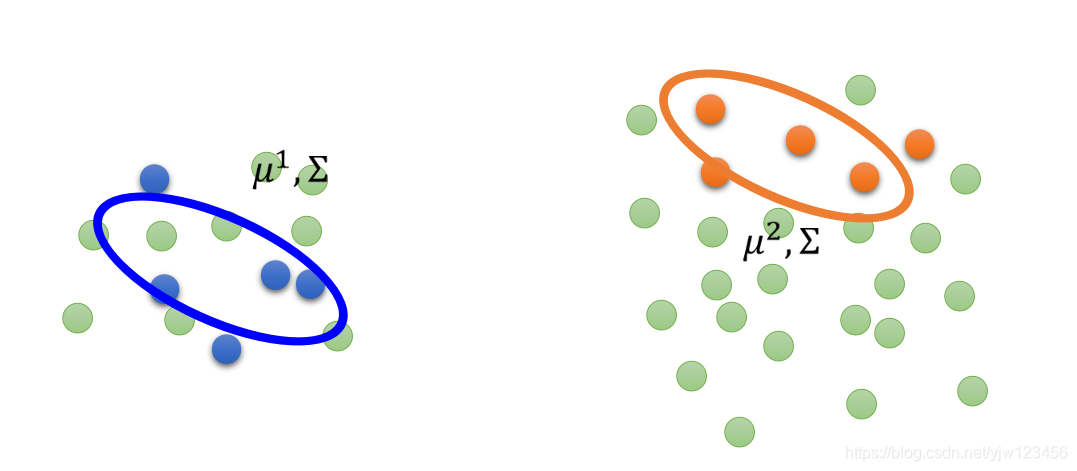
上面的绿色点都是无标签的数据,那么上面的参数是不合理的,因为还有很多分布没有考虑到。
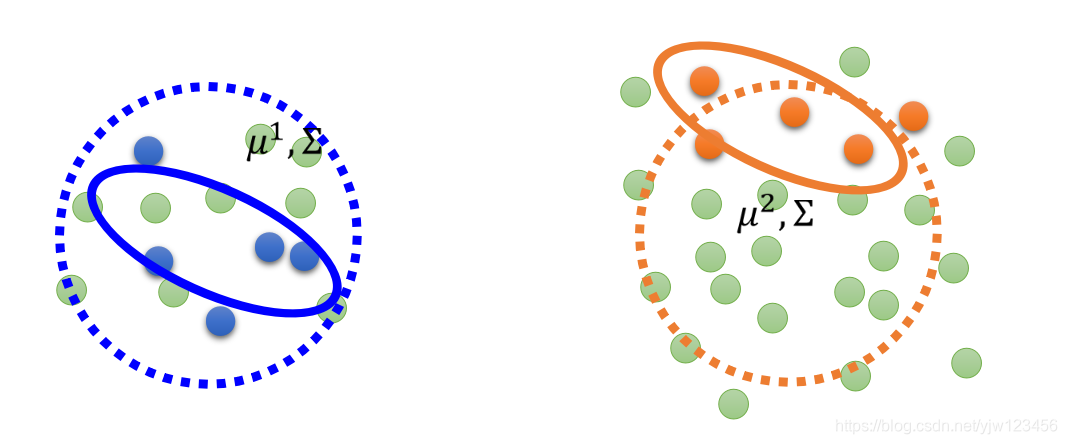
虚线圆圈的分布可能更加合理。总之这些无标签的数据会影响对 的估测。
那么实际上要怎么做呢
- 初始化一组参数 。
- 第一步:计算每笔无标签数据的后验概率(posterior probability) , 表示无标签的数据。
- 第二步:通过
(
是所有样本的数量,
是被标记为
的样本数量)来更新
,其中
出现的次数就是所有无标签数据属于
的概率之和。
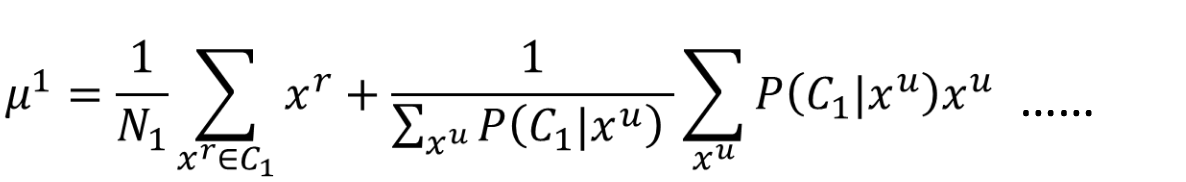
而 通过上面的公式更新(等式右边第一个式子是计算所有属于 的样本的均值,第二个式子,如果 偏向于 ,那么就对 的影响就大一点,反之就小一点。把它们加起来,再除以所有 中 的和)。 - 有了新的参数后就可以回到第一步(EM算法)
为什么是这样。
- 假设原来只有有标签数据,我们要做的事情是最大化似然 ,如果给定参数 ,那么每笔训练数据的 是可以算出来的:
- 现在同时有有标签数据和无标签数据 使用 ,其中一笔无标签数据出现的几率 就是 的先验概率乘以 类别产生无标签数据的概率加上 的先验概率乘以 类别产生无标签数据的概率(全概率公式)。就是说这笔无标签数据可能从 来,也可能从 中来,接下来就要最大化 。
上面是生成模型,下面介绍一种比较通用的方式,基于低密度分离(Low-density Separation),也就是非黑即白
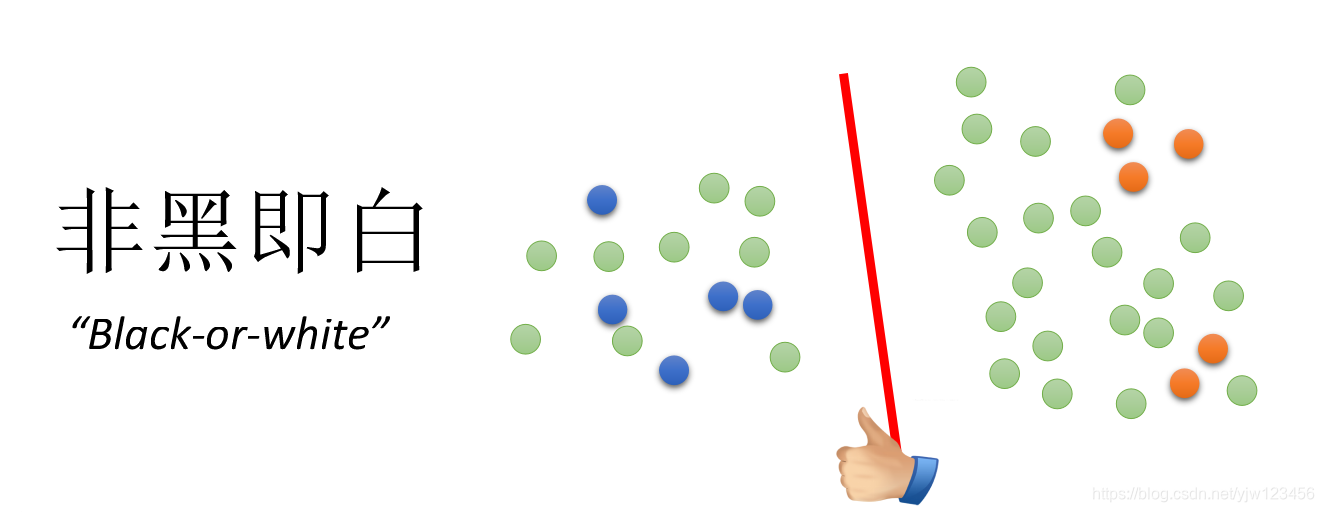
就是说在这两个类别的交界处密度很低,可以很容易的分开这两个类别。
其中最典型的方法就是Self-training(自训练算法)
Self-training
- 给定有标签数据集 ,和无标签数据集
- 重复
- 从有标签数据集中训练模型
- 将
应用到无标签数据集
- 获得
- 从无标签数据集中拿出一些数据,加到有标签数据集中
与基于生成模型的半监督学习类似。
在做自训练时用的是Hard label,在做生成模型的时候用的是Soft label;在做自训练时我们会强制一笔训练数据一定属于某个类别;在生成模型时,可能一部分属于类别A,另一部分属于类别B。
那么哪个好呢。
假设用于神经网络, 是来自有标签数据。
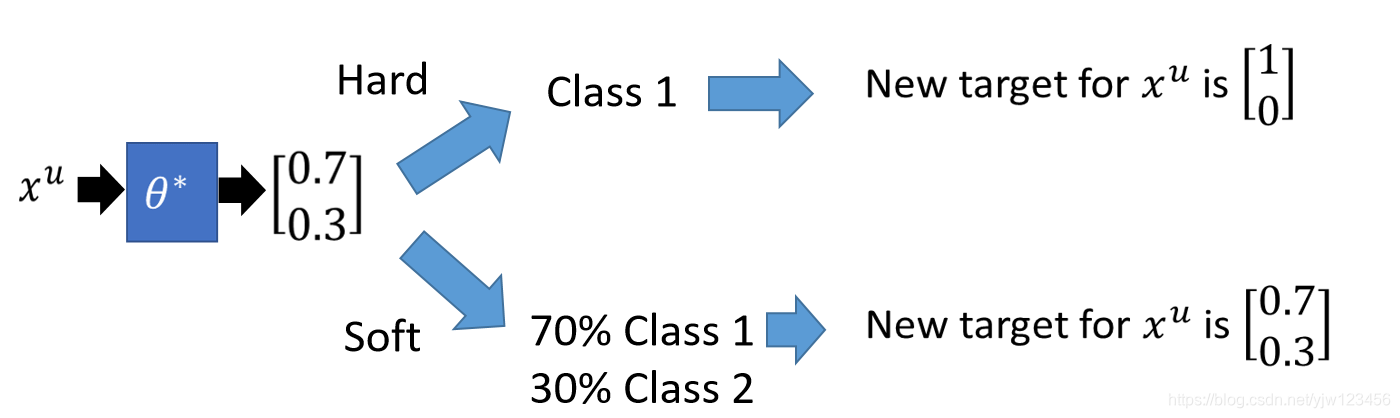
将一笔无标签数据喂给NN,如果是Hard那么得到的输出是[1 0],如果是Soft得到的是[0.7 0.3]。如果用Soft,那么得到的结果和经过NN的输出没有变化。就不会有用,因此在NN中是要用Hard的方法。
基于熵的正则化(Entropy-based Regularization)
如果用NN的时候,输出是一个分布的话,我们可以不限制它一定是某个类别,但是假设它的这个分布很集中。
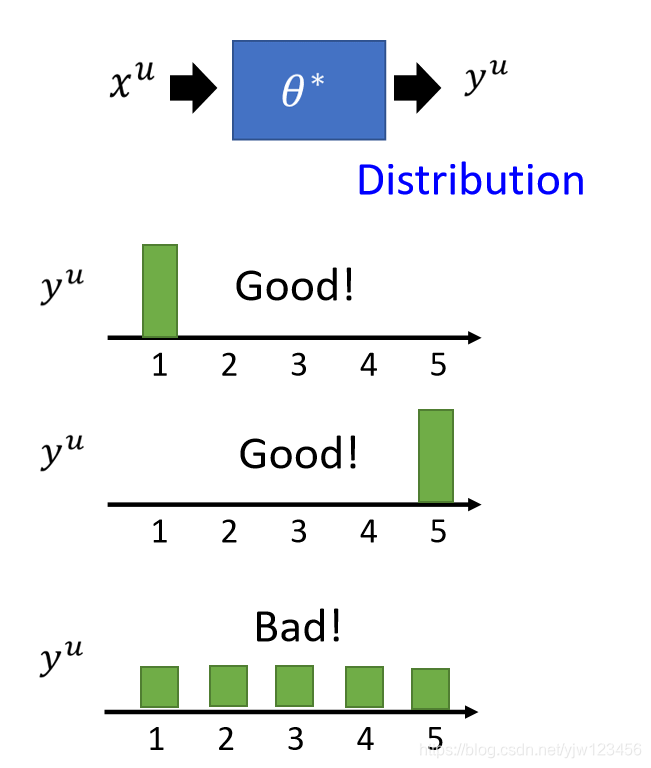
上图中最后一个例子中,分布是平均的,这样就不符合非黑即白的假设。
那我们如何用数值的方法来计算这个分布的好坏。
这里类别数N=5。
是这笔数据属于某个类别的概率。
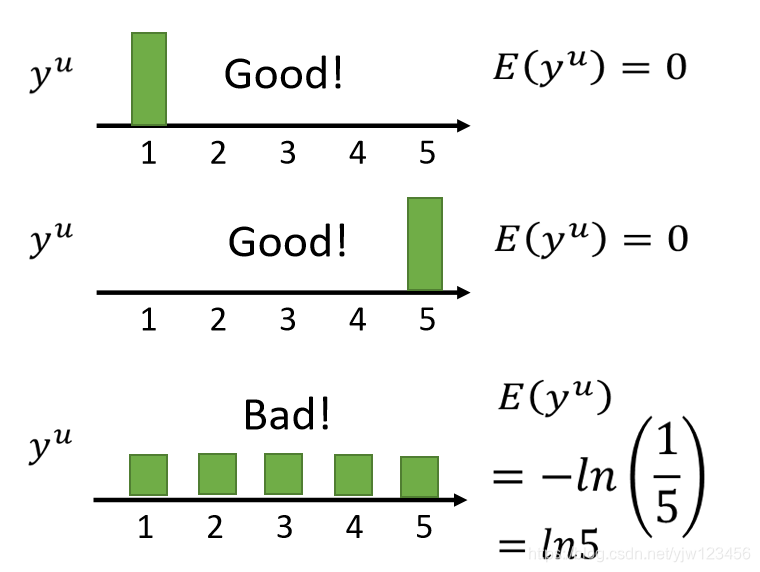
通过上面的公式可以算出它们对应的 。
我们希望这个模型的输出在无标签数据上的熵越小越小。
现在我们可以重新设计损失函数:
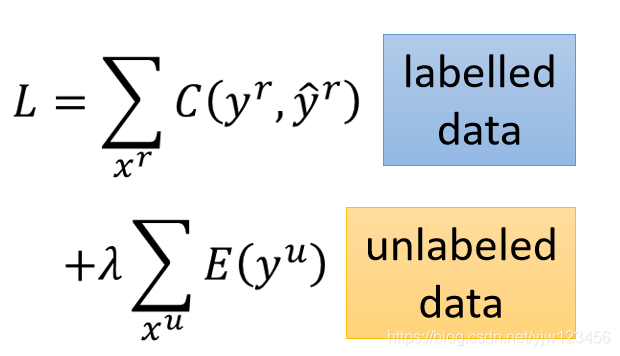
是权重,可以调的。
Smoothness Assumption
- 假设:相似的 有相同的输出
- 更精确的假设是:
- 的分布是不平均的
- 如果 和 都接近于某个高密度区域,那么说它们的输出是一样的
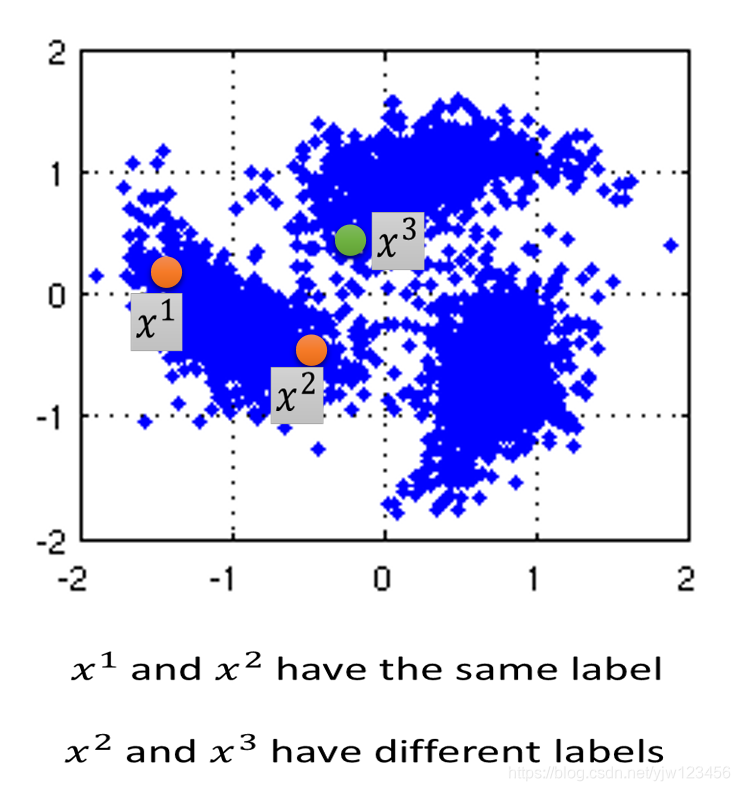
都属于某个高密度的区域,因此说它们的输出是一样的。
我们考虑手写数字识别的例子。

我们看这两个2,第一2有个圈圈,第二个2没有,粗看上去这两个2不太相似。
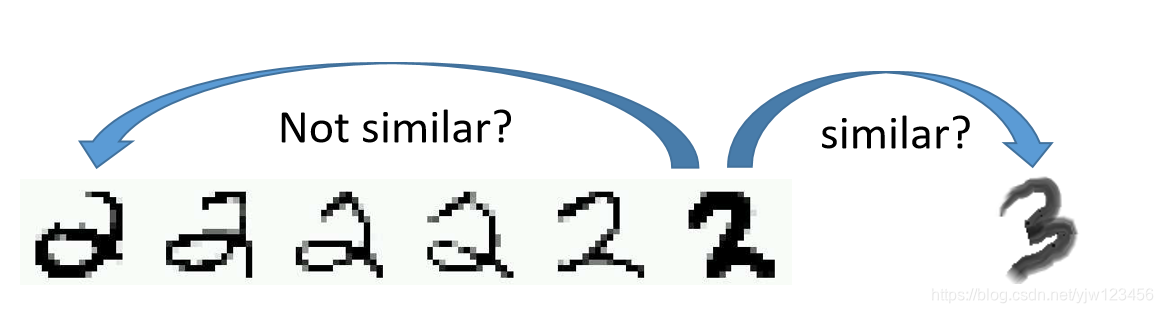
但是如果考虑更多的数据,会发现这两个2之间有很多连续的形态,因此这两个2应该属于同一个类别。
这一招在文本分类中也很有用。
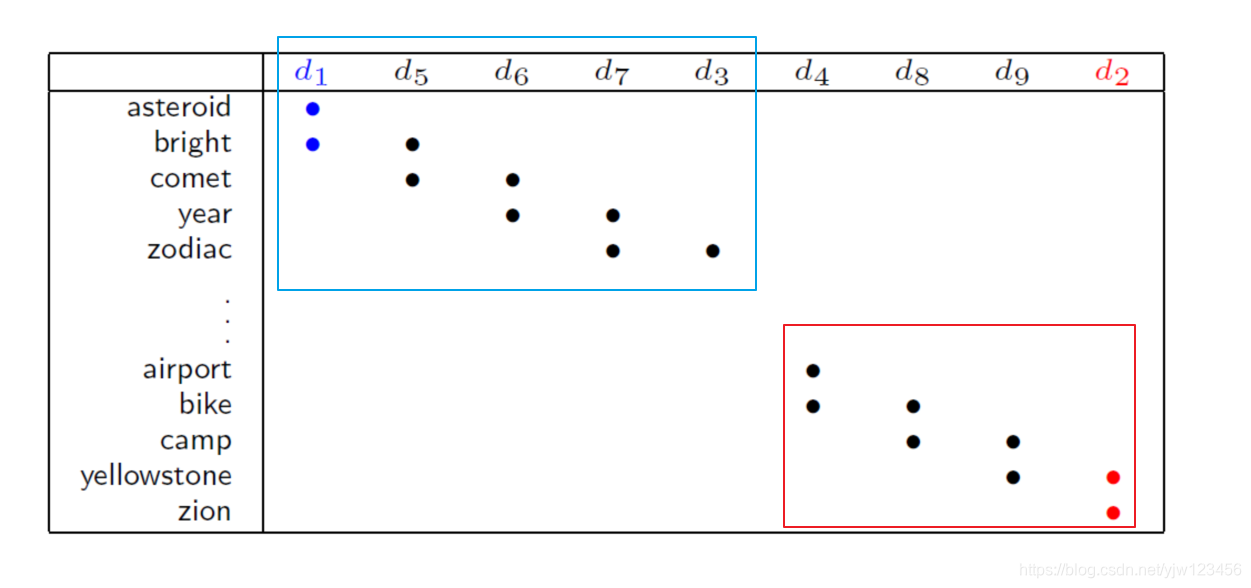
假设它们会出现左边那些单词,可以说 和 像, 和 像,最终得到 和 像。
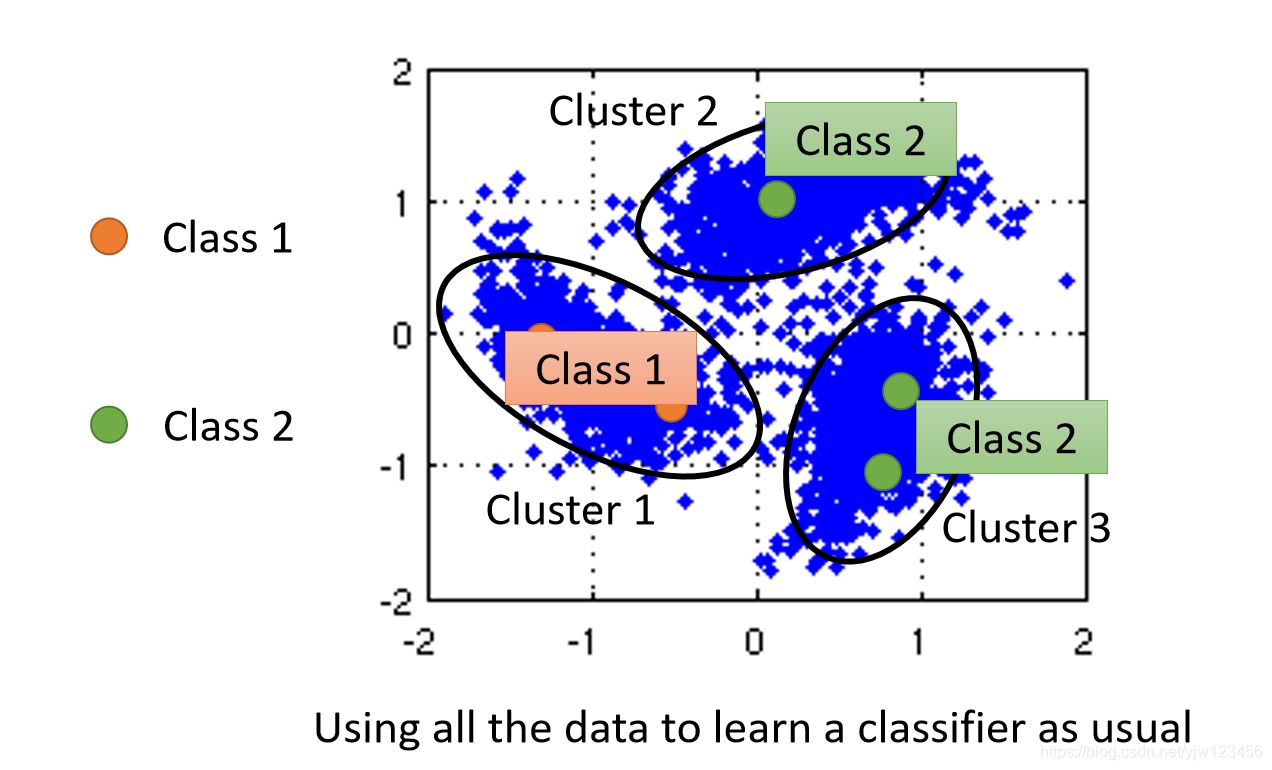
聚类打标签(Cluster and then Label)
基于图的方式(Graph-based Approach)
如何知道 和 是否接近于某个高密度区域。
用图结构来表示这些数据点。
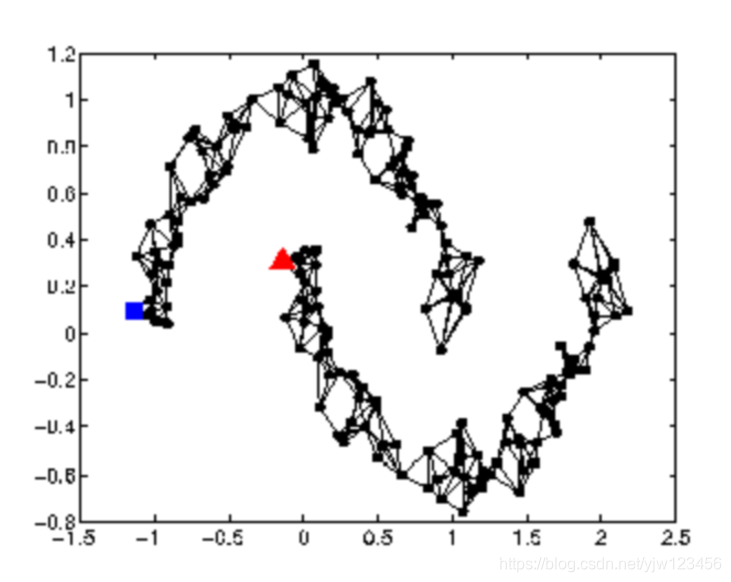
如果这两个顶点是相连的,就说它们属于同一个高密度区域。
例如,通过引用关系来进行论文的分类。
