目录
监督学习(Supervised Learning):
定义:根据已有的数据集,知道输入和输出结果之间的关系。根据这种已知的关系,训练得到一个最优的模型。也就是说,在监督学习中训练数据既有特征(feature)又有标签(label),通过训练,让机器可以自己找到特征和标签之间的联系,在面对只有特征没有标签的数据时,可以判断出标签。
分类:Regression(回归)、Classfication(分类)
Regression:
回归问题主要针对的是连续型变量
举个吴恩达老师上课的例子
下图给了个不同面积房子的大小的房价,X轴为尺寸,Y轴为房价
通过给出的数据集训练得出一个y=f(x)的函数(蓝线和红线是根据不同算法得出的不同函数)。
以后再估计房价时便可用此函数计算出房价

Classfication
分类问题与回归问题不同,针对的是离散型变量
还是吴恩达老师上课的例子
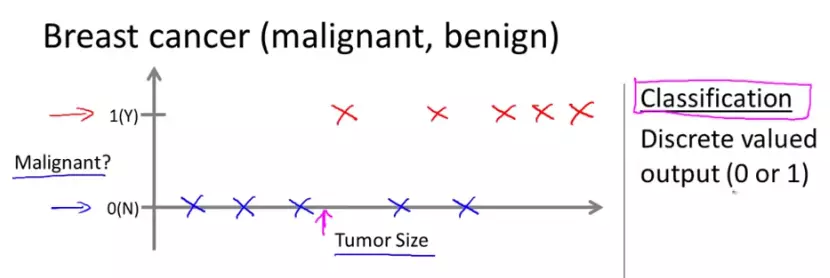
下图是一个简单的癌症情况的坐标系。
X轴是肿瘤块的大小,Y轴是阴性和阳性(1表示阴性,0是阳性)
算法通过学习,根据肿瘤块大小将分类成两类
当然这里正常情况下需要考虑多种特征
无监督学习(Unsupervised Learning)
定义:我们不知道数据集中数据、特征之间的关系,而是要根据聚类或一定的模型得到数据之间的关系。
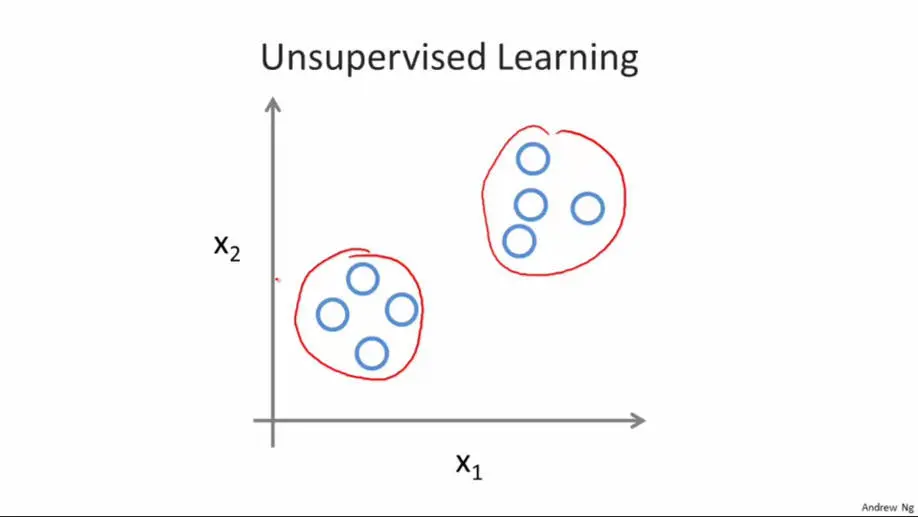
例子(一)
(声明两个例子均来自吴恩达老师上课举例)
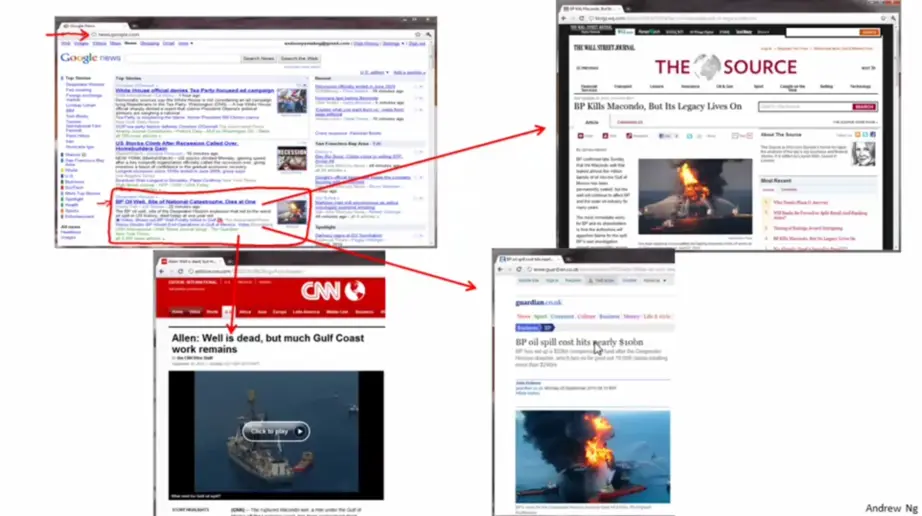
Google News搜集网上的新闻,并且根据新闻的主题将新闻分成许多簇, 然后将在同一个簇的新闻放在一起。如图中红圈部分都是关于BP Oil Well各种新闻的链接,当打开各个新闻链接的时候,展现的都是关于BP Oil Well的新闻。
例子(二)
如图是DNA数据,对于一组不同的人我们测量他们DNA中对于一个特定基因的表达程度。然后根据测量结果可以用聚类算法将他们分成不同的类型。这就是一种无监督学习, 因为我们只是给定了一些数据,而并不知道哪些是第一种类型的人,哪些是第二种类型的人等等。

监督学习与无监督学习的不同
- 监督学习方法必须有训练集,训练集会给我们什么是“正确答案"。
- 无监督学习没有训练集,只有一堆数据,在数据中寻找规律
- 如何选取方法:简单的方法就是从定义入手,有训练样本则考虑采用监督学习方法;无训练样本,则一定不能用监督学习方法。但是,现实问题中,即使没有训练样本,可以人工地给数据集标注一些样本,并把它们作为训练样本,这样的话,可以把条件改善,用监督学习方法来做。
