算法设计与分析课程复习笔记9——图的算法(含BFS、DFS)
图的算法
图:物体与物体之间的连接关系
图的背景知识
- 图:节点+边
- 表示方法:图G=(V,E)
- 节点V,|V|=n,节点数目
- 边E,|E|=m,边数目
图的其他类型:连通图(如果任何两个顶点之间存在一个通路,则称图是连接的),
二分图(无向图,由
和
组成,只在
和
之间的顶点存在边)
图的表示方法
邻接表
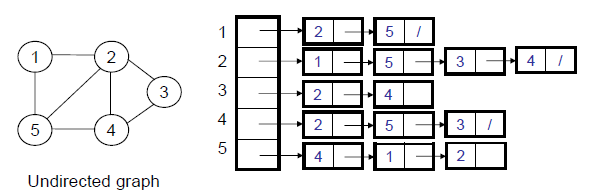
- 特性:有向图:邻接表长度的和等于边的数目
无向图:邻接表长度的和等于两倍的边的数目 - 空间需求:Θ(V+E)
- 适合:|E|<<|V|2
- 缺陷:不容易判断顶点u和v之间是否存在边
- 罗列与u邻接顶点的时间开销:Θ(degree(u))
- 判断(u, v) ∈ E的时间:O(degree(u))
相邻矩阵
- 无向图的相邻矩阵具有对称性
- 空间需求:Θ(V2),与边无关
- 适合情况:|E|接近|V|2,需要快速确定两个顶点之间是否存在边
- 罗列与u邻接顶点的时间开销:Θ(V)
- 判断(u, v) ∈ E的时间:Θ(1))
有权图
图的边被赋予了权值
权的存储:邻接表:存储在边表表目中。相邻矩阵:存储在元素中。
图的遍历
两种基本搜索算法
- 广度优先搜索
- 深度优先搜索
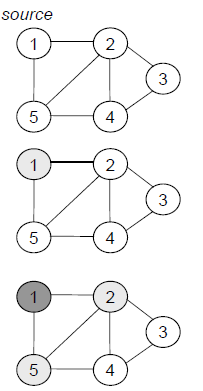
广度优先搜索BFS
- 输入:图G = (V, E),有向或无向。源顶点s ∈ V
- 目的:从临近源顶点s最近的顶点开始,通过对图G的边的探索发现从源顶点s能够抵达的每个顶点
- 输出:从s到v的距离d[v]。广度优先树:以s为根,包含所有可以抵达的顶点
广度优先:距离源顶点的距离逐渐增加来搜索相连通的其它顶点
过程追踪:
- 用白、灰和黑来标记顶点
- 最初为白
- 刚搜索到,灰
- 所有邻接顶点被搜索完,黑
- 先进先出队列来保存灰色顶点
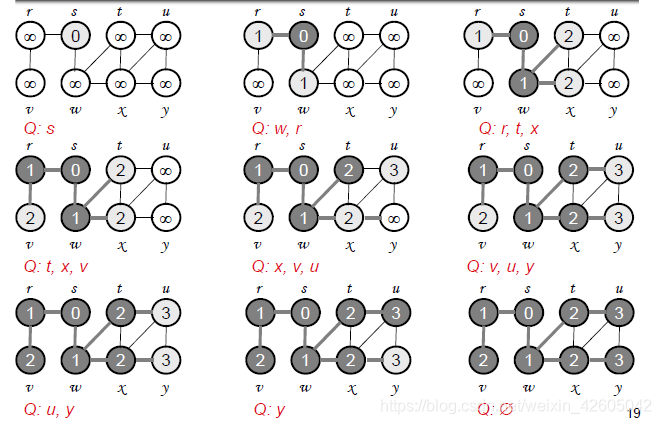
广度优先树BFT - 源节点为树根
- 在搜索顶点u的临接顶点时一旦发现了顶点v,便将顶点v和边(u,v)加入到树中
- 在BFT中,u是v的父节点
- 一个顶点只被发现一次,因此只有一个父节点
BFS附加数据结构
- 邻接表法表示图G=(V,E)
- 顶点颜色color[u]
- 顶点u的父顶点π[u]
- 如果顶点是根顶点或没有被发现,父顶点为空。π[u] = NIL
- 从s到u的距离d[u]
- 应用FIFO队列Q存储灰色顶点
BFS算法
for each u ∈ V-{s}
do color[u] ← WHITE
d[u] ←
π[u] ← NIL
color[s] ← GRAY
d[s] ← 0
π[s] ← NIL
Q ← 空集
Q ← Enqueue(Q,s)
while Q ≠ 空集
do u ← Dequeue(Q)
for each v ∈ Adj[u]
do if color[v] = WHITE
then color[v] = GRAY
d[v] = d[u]+1
π[v] = u
Enqueue(Q,v)
color[u] ← BLACK
算法分析:


最短路径
BFS确定了从源节点到其他顶点的最短路径
深度优先搜索DFS
输入:图,没有源顶点G(V,E)
目的:从当前访问顶点开始,探索图的边以发现图中的每个顶点
搜索从多个源重复
输出:每个顶点有两个时间标记:发现时间d[v],结束时间(检查v所有的邻接表)f[v]
深度优先森林DFF

深度优先搜索
- 尽可能往深度搜索
- 最近发现的顶点v仍然有没有被搜索的边
- 顶点v的所有边搜索完后,回朔到v的父顶点搜索
- 这个过程不断继续,直到从源顶点可以抵达的所有顶点都被发现
- 如果图中存在还没有发现的顶点,选择其中之一作为新的源顶点重复上述搜索过程
- 深度优先搜索DFS产生的是深度优先森林
DFS附加数据结构
- 全局变量:时间步骤。在顶点发现和搜索完成时增加
- 颜色变量color[u],和BFS类似。白:发现前,灰:发现处理中,黑:处理完成
- 顶点u的父顶点π[u]
- 发现、完成时间d[u]、f[u]
DFS算法:
DFS(V,E)
for each u ∈ V
do color[u] ←WHITE
π[u] ← NIL
time ← 0
for each u ∈ V
do if color[u] = WHITE
then DFS-VISIT(u)
DFS-VISIT(u)每次被调用时, u就成为深度优先森林中一棵新树的根节点
DFS-VISIT(u)
color[u] = GRAY
time ← time + 1
d[u] ← time
for each v ∈ Adj[u]
do if color[v] = WHITE
then π[v] = u
DFS-VISIT(v)
color[u] = BLACK
time ← time + 1
f[u] = time
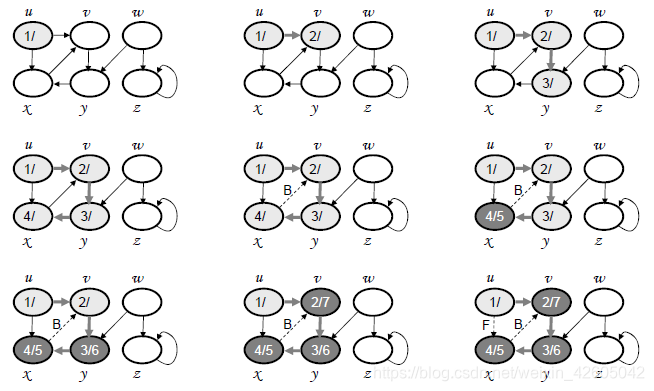
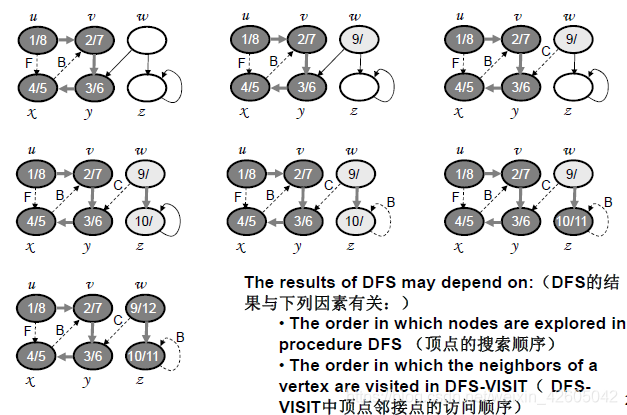
边的类型
- 树边:抵达白色顶点。
边(u, v) 是一树边,如果v是在探索边(u, v)时首次被发现 - 回边:抵达灰色顶点。
边(u,v)连接顶点u至其一个深度优先树的先辈顶点v
有向图中的自回路也是回边 - 前向边:抵达黑色顶点,且d[u]<d[v]
- 横跨边:抵达黑色顶点,且d[u]>d[v]
算法分析:


DFS特性
- u = π[v] DFS-VISIT(v) 在搜索u的邻接表时被调用
- 深度优先树上顶点v是顶点u的后裔 顶点v在顶点u处于灰色状态时被发现
- 顶点v是顶点u的后裔 d[u] < d[v] < f[v] < f[u]
- 在图G的任何深度优先森林中,顶点v是顶点u的后裔,当且仅当在时刻d[u],存在一条u → v的路径只包含有白色顶点
括号定理
对于一个图的任何DFS,对于任何u,v,下列情况之一成立:
- [d[u], f[u]]和[d[v], f[v]]不邻接, u和v 互不为后裔
- [d[u], f[u]] 包含[d[v], f[v]], v是u的后裔
- [d[v], f[v]] 包含[d[u], f[u]] , u是v的后裔
拓扑排序
拓扑排序:找出有向无回路图G = (V, E)中顶点的一个线性序,使得(u, v)如果是图中的一条边,那么在这个线性序中u在v前出现
顶点水平排列,有向边从左到右。
TOPOLOGICAL-SORT(V, E)
- 调用DFS(V, E) ,对每个顶点v计算其完成时间f[v]
- 顶点完成,将之插入到连接表前端
- 返回顶点的连接表
运行开销:
引理:有向图是无回路的 深度优先搜索DFS不产生回边
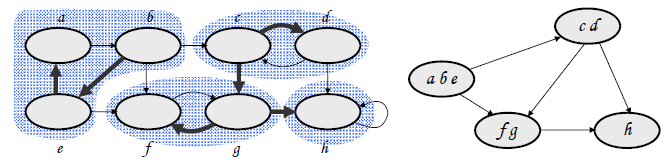
强连通分支SCC
有向图G = (V, E)中的强连通分支是它的顶点的极大集C(V的子集) ,在该集中,每一对顶点u, v ∈ C有u → v 和v → u
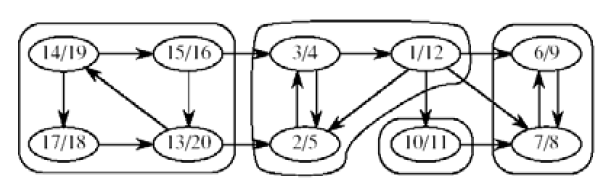
图的转置
GT是G的所有边转向
应用邻接表,我们可以在
时间创造GT
GT和G有相同的SCC
有向无回路图的SCC确定方法:在G和GT做深度搜索
强连通分支的求解
- 在图上执行深度优先搜索,计算每个顶点u的完成时刻f[u]
- 构成转置图GT
- 从具有最大f[u]的顶点开始,在GT上执行深度优先搜索,如果深度优先搜索不能到达所有的顶点,则在余下的顶点中找一个f[u]最大的顶点,开始下一次深度优先搜索
- 在最终得到的森林中的每一棵树对应一个强连通分支
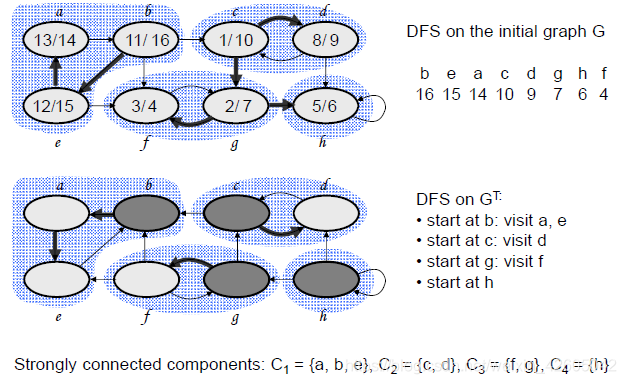
分支图
两个引理
- C和C’是图G的SCC,u, v ∈ C,u’,v’∈ C,假设图G中存在通路u → u’,则不可能存在v’→ v
- C和C’是有向图G = (V, E)的SCC,如果存在边(u, v) ∈ E ,u ∈ C, v ∈ C’,则有f(C) > f(C’)
参考:任课教师邱德红教授的课件
