算法设计与分析课程复习笔记5——随机化算法
随机化算法
雇佣问题
问题描述:
- 通过中介招聘新职员
- 一天面试一个中介介绍的候选人
- 优胜劣汰
Hire-Assistant(A)
current ← an infinitely useless dummy assistant(初值)
for i = 1…n
do if A[i] is better qualified than current
then current ← A[i]
return current
代价模型
面试代价:中介费用
,候选人路费
等等
雇用代价:因雇佣付给中介的额外费用
,雇佣导致的内部管理费用
总费用:面试n个人的费用+面试中m个人获得雇佣的费用
即:
最好情况:第一个人最优
最坏情况:面试者越来越好
我们期望的m是什么?
概率分析
假设两两候选人互异
于是我们可以进行排序:1,2,……,n
假设每种排列的可能性相等
(即一致性随机排列)
指示变量
指示变量用于概率和期望值之间的转换
Lemma: For an event E and its indicator variable
= I(E), Pr(E) = E(
).
雇佣问题平均情况分析
事件:
、
、……、
即第i个受聘用
指示变量:
、
、……、
=

期望雇佣代价:Θ( )
平均情况分析的缺陷
- 算法已确定
- 每一个确定的算法都有其最坏的输入
- 不良中介可能一直提供最坏的输入
解决方法:随机化
改进的雇佣算法:
- 从中介获得所有候选人名单
- 产生输入的一致性随机排列
- 再面试
期望代价:Θ( )
不同之处:
- 没有争议性假设
- 不存在明确的导致最坏情况的输入
- 削弱了对手的操控能力
一致随机排列生成
如何得到n个元素的一致性随机排列?
方法1:排序法排列
Permute-By-Sorting(A)
Allocate an array B of size n (数组)
for i = 1…n
do B[i] ← random(1,
)
Sort arrays A, using B as sort keys(排序,以B为参考)

方法2:换位法排列
Permute-In-Place(A)
for i = 1…n – 1
do j ← random(i, n)
swap A[i] ↔ A[j] (交换)
Lemma: Procedure Permute-In-Place takes linear time O(n).
开销O(n).
Lemma: Procedure Permute-In-Place produces a uniformly
random permutation.(一致性随机排列)
快速排序
为了排序A[p……r]
- 分割,根据选定的某个中心,将A分成两个部分
- 治理,每一部分用QuickSort嵌套处理
- 组合
算法如下:
QuickSort(A,p,r)
if p<r
then q
Partition(A,p,r)
QuickSort(A,p,q-1)
QuickSort(A,q+1,r)
其中Partition(A,p,r)分割,返回分离点的位置q
Partition(A,p,r)
x
A[r]
i
p-1
for j
p to r-1
do if A[j]≤x
then i
i+1
exchange A[i]
A[j]
exchange A[i+1]
A[r]
return i+1
解释:选择最后一个元素作为分割中心
分割过程中出现4个区域:
- All entries in A[p … i ] ≤ pivot.
- All entries in A[i+1 … j-1] > pivot.
- A[ j . . r-1]
- A[r] = pivot.
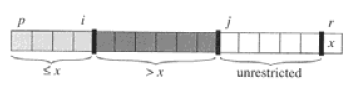
快速排序分析:
最坏情况:分割中心选择了最大或最小
最好情况:分割中心每次都选择在中值
平均情况接近最好情况
随机化快速排序
QuickSort(A,p,r)
if p<r
then swap A[r]
A[random(p,r)]
q
Partition(A,p,r)
QuickSort(A,p,q-1)
QuickSort(A,q+1,r)
快速排序运行时间
如果X为QuickSort作比较的总次数,则时间开销为
E(X)=O(nlgn)
指示变量
则
E(X)
=E(
)
=
E(
)
=
Pr(
and
are compared)
=
(
)
=
=
随机快速排序期望的时间开销:
随机算法的分类
- Las Vegas算法:随机算法总是或者给出正确的解,或者无解。
- Monte Carlo算法:居多能够给出正确的解,偶尔产生错误的解。可以采取措施使产生错误解的概率降低到任意的程度。
测试串的相等性
A:长串x
B:长串y
x=y?
A将x发送给B,或B将y发送给A,然后判断x=y?
缺点:浪费资源
A从x中取出一个短得多的串作为x的“指纹”发送给B,B用同样的方法获得y的“指纹”,如果两者的“指纹”相同,则认为x=y,否则x=y 不成立。
特点:节约了资源,但理论上不能100%正确。
“指纹”生成
对于一个串w,设I(w)是比特串w表示的一个整数,一种产生“指纹”的方法是选择一个素数p,通过“指纹”函数产生。
≠
则 x ≠ y
算法:
1、A从小于M的素数集中随机选择p;
2、A将p和
发送给B;
3、B检查是否
,确定x和y是否相等。
失败概率分析

n 是x的二进制的表示形式的位数
π(n)是小于n 的不同素数的个数
π(n)
参考:任课教师邱德红教授的课件
