1. 深度优先遍历
深度优先遍历(Depth First Search)的主要思想是:
1、首先以一个未被访问过的顶点作为起始顶点,沿当前顶点的边走到未访问过的顶点;
2、当没有未访问过的顶点时,则回到上一个顶点,继续试探别的顶点,直至所有的顶点都被访问过。
在此我想用一句话来形容 “不到南墙不回头”。
1.1 无向图的深度优先遍历图解
以下"无向图"为例:
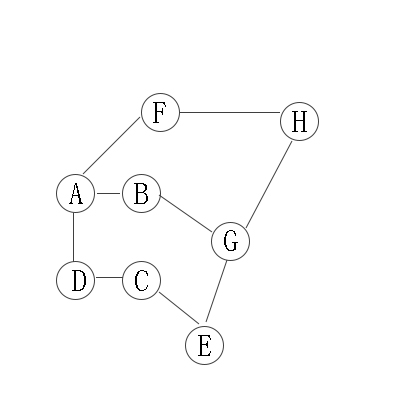
对上无向图进行深度优先遍历,从A开始:
第1步:访问A。
第2步:访问B(A的邻接点)。 在第1步访问A之后,接下来应该访问的是A的邻接点,即"B,D,F"中的一个。但在本文的实现中,顶点ABCDEFGH是按照顺序存储,B在"D和F"的前面,因此,先访问B。
第3步:访问G(B的邻接点)。 和B相连只有"G"(A已经访问过了)
第4步:访问E(G的邻接点)。 在第3步访问了B的邻接点G之后,接下来应该访问G的邻接点,即"E和H"中一个(B已经被访问过,就不算在内)。而由于E在H之前,先访问E。
第5步:访问C(E的邻接点)。 和E相连只有"C"(G已经访问过了)。
第6步:访问D(C的邻接点)。
第7步:访问H。因为D没有未被访问的邻接点;因此,一直回溯到访问G的另一个邻接点H。
第8步:访问(H的邻接点)F。
因此访问顺序是:A -> B -> G -> E -> C -> D -> H -> F
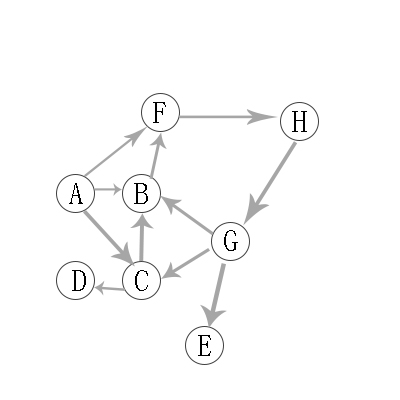
1.2 有向图的深度优先遍历
有向图的深度优先遍历图解:
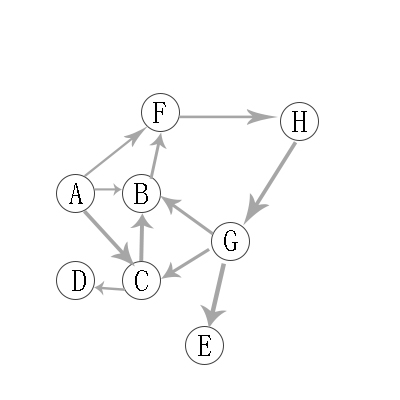
对上有向图进行深度优先遍历,从A开始:
第1步:访问A。
第2步:访问(A的出度对应的字母)B。 在第1步访问A之后,接下来应该访问的是A的出度对应字母,即"B,C,F"中的一个。但在本文的实现中,顶点ABCDEFGH是按照顺序存储,B在"C和F"的前面,因此,先访问B。
第3步:访问(B的出度对应的字母)F。 B的出度对应字母只有F。
第4步:访问H(F的出度对应的字母)。 F的出度对应字母只有H。
第5步:访问(H的出度对应的字母)G。
第6步:访问(G的出度对应字母)E。 在第5步访问G之后,接下来应该访问的是G的出度对应字母,即"B,C,E"中的一个。但在本文的实现中,顶点B已经访问了,由于C在E前面,所以先访问C。
第7步:访问(C的出度对应的字母)D。
第8步:访问(C的出度对应字母)D。 在第7步访问C之后,接下来应该访问的是C的出度对应字母,即"B,D"中的一个。但在本文的实现中,顶点B已经访问了,所以访问D。
第9步:访问E。D无出度,所以一直回溯到G对应的另一个出度E。
因此访问顺序是:A -> B -> F -> H -> G -> C -> D -> E
2.广度优先遍历
广度优先遍历(Depth First Search)的主要思想是:类似于树的层序遍历。
2.1 无向图的广度优先遍历图解:
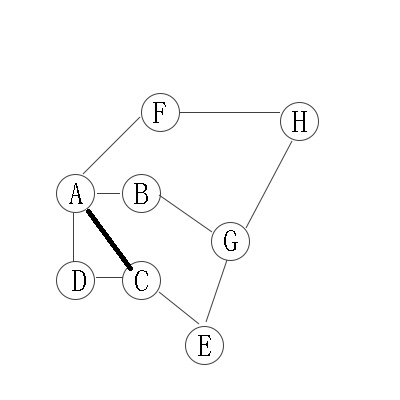
从A开始,有4个邻接点,“B,C,D,F”,这是第二层;
在分别从B,C,D,F开始找他们的邻接点,为第三层。以此类推。
因此访问顺序是:A -> B -> C -> D -> F -> G -> E -> H
2.2 有向图的广度优先遍历图解:
与无向图类似 。可以参考。
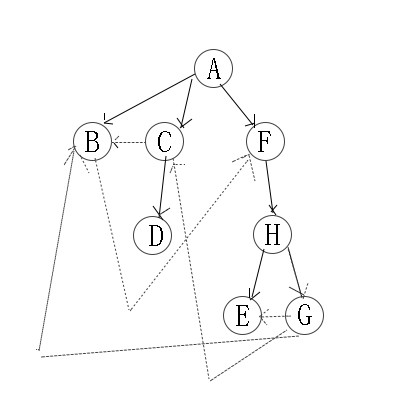
因此访问顺序是:A -> B -> C -> F -> D -> H -> E -> G
没有贴代码,需要可以给博主私哦。
PS:打字不易,转载请说明出处。