简单来说,回归分析就是利用样本(已知数据),产生拟合方程,从而(对未知数据)进行预测。主要包括线性回归和非线性回归。
线性回归中又包括:一元线性、多元线性以及广义线性(代表为逻辑回归,下一节讲)
在应用中,我们往往不知道是否能用线性回归。因此我们可以使用相关系数去衡量线性相关性的强弱。
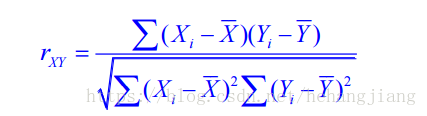
使用平方误差和衡量预测值不真实值的差距:
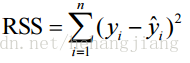
我们希望平方误差越小越好,这代表拟合程度越高。
求取最小值,可以使用两种方法。分别是最小二乘法和梯度下降法(包括其改进算法)。
最小二乘法一步到位,但是矩阵不可逆的情况下无效。
梯度下降法则不会。关于梯度下降法的讲解网上很多,简单来说就是根据学习率不断更新参数,使得平方误差达到极小点。但容易出现局部最小点,而非全局最小点的情况。因此需要选择合适的α(学习率)。学习率太小,则下降慢;学习率过大,容易越过最小值点,无法收敛。
我们可以使用特征缩放(Feature Scaling)来加快梯度下降的速度。
特征选取
在多元线性回归时,特征选取是一个关键。通常有以下几种选取特征的方法:
- 逐步回归
- 向前引入法:从一元回归开始,逐步增加变量,使指标值达到最优为止
- 向后剔除法:从全变量回归方程开始,逐步删去某个变量,使指标值达到最优为止
- 逐步筛选法:综合上述两种方法
缺陷
比如我们根据训练集的身高体重预测新数据点的体重。我们可能会得到身高为0时也有体重或者为负数的情况。因此,可以看出:回归问题擅长于内推插值,而丌擅长于外推归纳。在使用回归模型做预测时要注意x适用的取值范围。
示例
import numpy as np
import pandas as pd
from sklearn.datasets import load_boston #波士顿数据集
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
#shape为(506, 13),506个样本,14个特征,[‘CRIM' ‘ZN' ‘INDUS' ‘CHAS' ‘NOX' ‘RM' ‘AGE' ‘DIS' ‘RAD' ‘TAX' ‘PTRATIO''B' ‘LSTAT']
boston = load_boston()
# print(boston['data'])
#给数据添加列名以及价格(输出)
bos = pd.DataFrame(boston.data) #
bos.columns = boston.feature_names
# print(bos.head())
bos['PRICE'] = boston.target
# print(bos.head())
#线性回归
X = bos.drop('PRICE', axis=1)
Y = bos.PRICE
# print(Y)
liner = LinearRegression()
liner.fit(X,Y)
print('线性回归算法w值:', liner.coef_)
print('线性回归算法b值: ', liner.intercept_)
#展示房间数量和价格的关系
plt.scatter(bos.RM, bos.PRICE)
plt.xlabel(u'room_num')
plt.ylabel(u'price')
plt.title(u'RM&PRICE')
plt.show()