文章目录
1.线性回归的一般步骤

2第一个机器学习算法 - 单变量线性回归
线性回归实际上要做的事情就是: 选择合适的参数(θ0, θ1),使得hθ(x)方程,很好的拟合训练集
pip install sklearn # 首先安装sklearn包
# 使用sklearn实现线性回归
import numpy as np
from sklearn.linear_model import LinearRegression
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
lin_reg = LinearRegression()
# fit方法就是训练模型的方法
lin_reg.fit(X, y)
# intercept 是截距:浮点数 coef是参数numpy数组
print(lin_reg.intercept_, lin_reg.coef_)
输出:
[3.96724622] [[2.99092045]]
[[3.96724622]
[9.94908711]]
3损失函数(代价函数)
这里损失函数采用小均方误差,目标:MSE最小均方误差

为了使均方误差最小采用梯度下降法
4梯度下降法


即使学习率α是固定不变的,梯度下降也会熟练到一个最低点
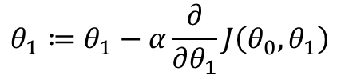

5线性回归的梯度下降


“Batch” Gradient Descent 批梯度下降
批梯度下降:指的是每下降一步,使用所有的训练集来计算梯度值
“Stochastic” Gradient Descent 随机梯度下降
随机梯度下降:指的是每下降一步,使用一条训练集来计算梯度值
“Mini-Batch” Gradient Descent “Mini-Batch”梯度下降
“Mini-Batch”梯度下降:指的是每下降一步,使用一部分的训练集来计算梯度值
"""
线性回归实现梯度下降的批处理(batch_gradient_descent )
"""
import numpy as np
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
X_b = np.c_[np.ones((100, 1)), X]
# print(X_b)补一列1与theta0相乘,X与theta1相乘
learning_rate = 0.1 # 学习率
# 通常在做机器学习的时候,一般不会等到他收敛,因为太浪费时间,所以会设置一个收敛次数
n_iterations = 1000
m = 100 # 一百个样本 均值需要除以100
# 1.初始化theta, w0...wn
theta = np.random.randn(2, 1)
count = 0
# 4. 不会设置阈值,之间设置超参数,迭代次数,迭代次数到了,我们就认为收敛了
for iteration in range(n_iterations):
count += 1
# 2. 接着求梯度gradient
gradients = 1/m * X_b.T.dot(X_b.dot(theta)-y)
# 3. 应用公式调整theta值, theta_t + 1 = theta_t - grad * learning_rate
theta = theta - learning_rate * gradients
print(count)
print(theta)
输出
1000
[[3.83531075]
[3.12545786]]
6多变量线性回归
模型:
之前: hθ(x) = θ0 + θ1x
现在: hθ(x) = θ0 + θ1x1 + θ2x2 + … + θnxn
为了保证模型的统一性,我们给模型加上x0 ,并使 x0 = 1
hθ(x) = θT x

"""
线性回归实现梯度下降的批处理(batch_gradient_descent )
"""
import numpy as np
X1 = 2 * np.random.rand(100, 1)
X2 = 4 * np.random.rand(100, 1)
X3 = 6 * np.random.rand(100, 1)
y = 4 + 3 * X1 + 4 * X2 + 5 * X3 + np.random.randn(100, 1)
X_b = np.c_[np.ones((100, 1)), X1, X2, X3]
# print(X_b)
learning_rate = 0.1
# 通常在做机器学习的时候,一般不会等到他收敛,因为太浪费时间,所以会设置一个收敛次数
n_iterations = 1000
m = 100
# 1.初始化theta, w0...wn
theta = np.random.randn(4, 1)
count = 0
# 4. 不会设置阈值,之间设置超参数,迭代次数,迭代次数到了,我们就认为收敛了
for iteration in range(n_iterations):
count += 1
# 2. 接着求梯度gradient
gradients = 1/m * X_b.T.dot(X_b.dot(theta)-y)
# 3. 应用公式调整theta值, theta_t + 1 = theta_t - grad * learning_rate
theta = theta - learning_rate * gradients
print(count)
print(theta)
输出:
1000
[[3.92259225]
[3.01393388]
[3.97901354]
[5.00789683]]
7过拟合
由于变量过多,所以会导致过拟合
那如何解决过拟合的问题呢?
1.减少特征的数量
(1)手动选择特征数
(2)模型选择
2.正则化
保留所有特征,但是减少量级或者参数θ_j的大小
使用正则化





1.Lasso 回归代码
Lasso用的是l1的正则化
import numpy as np
from sklearn.linear_model import Lasso
from sklearn.linear_model import SGDRegressor
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
lasso_reg = Lasso(alpha=0.15)
lasso_reg.fit(X, y)
print(lasso_reg.predict([[1.5]]))
print(lasso_reg.coef_)
sgd_reg = SGDRegressor(penalty='l1', n_iter=1000)
sgd_reg.fit(X, y.ravel())
print(sgd_reg.predict([[1.5]]))
print(sgd_reg.coef_)
输出:
[8.43787987]
[2.80448956]
[8.68219682]
[3.29590815]
2. 岭回归代码
岭回归运用了L2正则化
import numpy as np
from sklearn.linear_model import Ridge
from sklearn.linear_model import SGDRegressor
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# alpha是惩罚项里的alpha, solver处理数据的方法,auto是根据数据自动选择,svd是解析解,sag就是随机梯度下降
ridge_reg = Ridge(alpha=1, solver='auto')
# 学习过程
ridge_reg.fit(X, y)
# 预测
print(ridge_reg.predict([[1.5], [2], [2.5]]))
# 打印截距
print(ridge_reg.intercept_)
# 打印系数
print(ridge_reg.coef_)
"""
岭回归和sgd & penalty=l2是等价的
"""
sgd_reg = SGDRegressor(penalty='l2')
sgd_reg.fit(X, y.ravel())
print(sgd_reg.predict([[1.5], [2], [2.5]]))
# 打印截距
print("W0=", sgd_reg.intercept_)
# 打印系数
print("W1=", sgd_reg.coef_)
输出:
[[ 8.67643004]
[10.14983062]
[11.62323119]]
[4.25622831]
[[2.94680115]]
[ 8.43153272 10.12362222 11.81571172]
W0= [3.35526423]
W1= [3.384179]
总结:

