一、算法简介
回归最简单的定义是,给出一个点集D,用一个函数去拟合这个点集,并且使得点集拟合函数间的误差最小。如果这个函数曲线是一条直线,就被称为线性回归。
- 优点:结果易于理解,计算上不复杂
- 缺点:对非线性的数据拟合不好
- 适用数据类型:数据型和标称型数据
二、具体介绍
回归的目的就是建立一个回归方程用来预测目标值,回归的求解就是求这个方程的回归系数,预测方法就是用回归系数乘以输入数据再全部相加就得到了预测结果。假定输入数据存放在矩阵X中,而回归系数存放在向量w中,那么对于给定的数据X1,预测结果将会通过给出。
现在的问题是,如果有一些x和对应的y,怎么才能找到w呢?
一个最简单的方法就是找出使误差最小的w。这里的误差是指预测y值与真实y值之间的差值,使用该误差的简单累加将使得正差值和负差值相互抵消,所以我们采用平方误差(最小二乘法)。平方误差可以写作:
三、最小二乘法在线性回归中的使用
1、基本介绍:通过在直角坐标系中作散点图的方式我们会发现很多统计数据近似一条直线,虽然这些数据不是连续的,但我们可以通过画直线的方式得到一个近似的描述这种关系的直线方程,这样的直线可以画出很多条,而我们希望找出能够最好地反映变量之间的关系的一条直线。换言之,我们要找出一条直线,使这条直线“最贴近”已知的数据点。直线表达式为
“最小二乘法”的核心就是保证所有数据偏差的平方和最小。
此时a,b需满足
2、特点:给定输入矩阵X,如果的逆存在并且可以求得,就可以直接采用该方法求解。
3、公式:
其中矩阵X为(m,n+1),m为样本数,n表示一个样本的特征数,Y为(m,1)列向量。
关于最小二乘法的证明会在下一篇文章中给出。
四、源代码
from numpy import *
def loadDataSet(fileName): #从文件中读取数据
numFeat = len(open(fileName).readline().split('\t')) - 1 #获取字段数
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr =[]
curLine = line.strip().split('\t')
for i in range(numFeat):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat,labelMat #返回一个属性列表和一个标签列表
def standRegres(xArr,yArr): #求解回归系数
xMat = mat(xArr); yMat = mat(yArr).T #将输入参数转换成矩阵,输入参数分别为属性列表和标签列表
xTx = xMat.T*xMat #将属性矩阵与属性矩阵的转置矩阵相乘
if linalg.det(xTx) == 0.0: #判断乘积的出的矩阵是否可逆
print "This matrix is singular, cannot do inverse"
return
ws = xTx.I * (xMat.T*yMat) #如果可逆的话就将求逆后的矩阵与标签矩阵和属性矩阵的转置矩阵相乘得出回归系数
return ws在命令行输入如下代码:
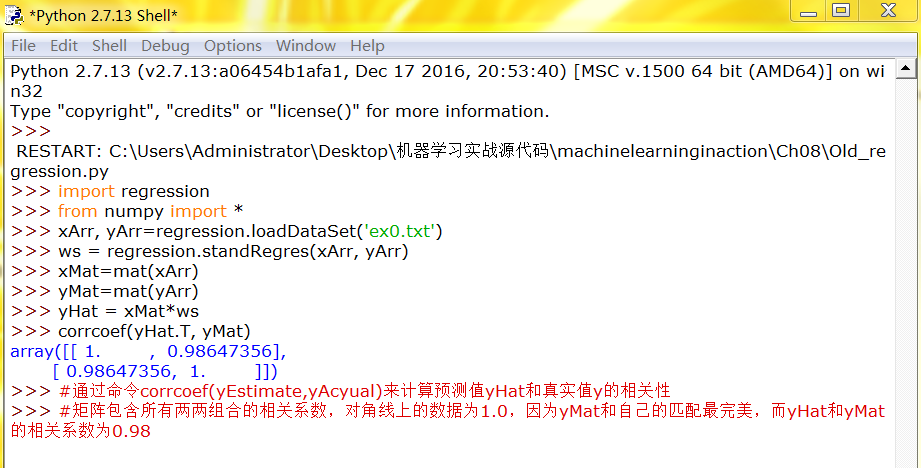
>>>import regression
>>>from numpy import
>>>xArr,yArr=regression.loadDataSet('ex0.txt')
>>>ws=regression.standRegres(xArr,yArr)
>>>xMat=mat(xArr)
>>>yMat=mat(yArr)
>>>yHat=xMat*ws
>>>import matplotlib.pyplot as plt
>>>fig=plt.figure()
>>>ax=flg.add_subplot(111)
>>>ax.scatter(xMat[:,1].flatten().A[0],yMat.T[:,0].flatten().A[0]
<matplotlib.collections.PathCollection object at 0x000000000527AF28>
>>>xCopy=xMat.copy()
>>>xCopy.sort(0)
>>>yHat=xCopy*ws
>>>ax.plot(xCopy[:,1],yHat)
[<matplotlib.lines.Line2D object at 0x000000000528E748>]
>>>plt.show()五、输出结果
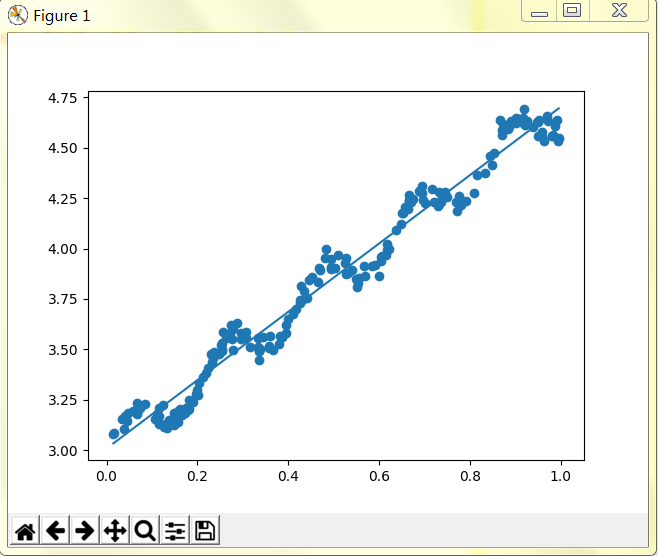
注意:数据需要自己输入。
六、算法小结
与分类一样,回归也是预测目标值的过程。回归与分类的不同点在于,前者预测连续性变量,而后者预测离散型变量。在回归方程里,求得特征对应的最佳回归系数的方法是最小化误差的平方和。给定输入矩阵X,如果的逆存在并可以求得的话,回归法都可以直接使用。数据集上计算出的回归方程并不一定意味着它是最佳的,可以使用预测值yHat和原始值y的相关程度来度量回归方程的好坏。