直接给复习的笔记O(∩_∩)O~~~~



代码实例:
#线性回归
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
if __name__ == "__main__":
path = 'E:/训练数据/8.Advertising.csv'
# pandas读入
data = pd.read_csv(path, index_col = 0) # TV、Radio、Newspaper、Sales
x = data[['TV', 'Radio', 'Newspaper']]
y = data['Sales']
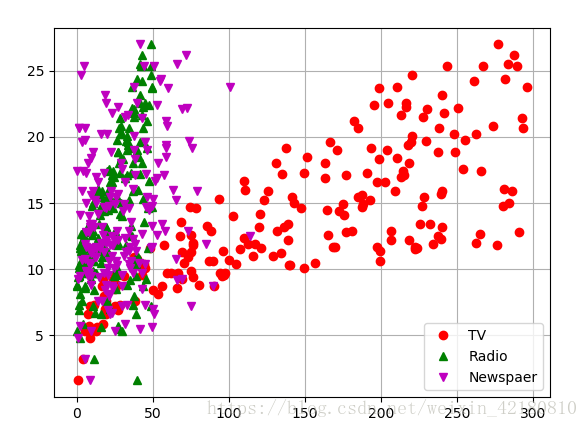
# # 绘制数据散点图
plt.plot(data['TV'], y, 'ro', label='TV')
plt.plot(data['Radio'], y, 'g^', label='Radio')
plt.plot(data['Newspaper'], y, 'mv', label='Newspaer')
plt.legend(loc='lower right') #显示图例,以及位置,在图内部
plt.grid() #显示网格
plt.show()
#建模
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1) #随机的取分割训练集和测试集
linreg = LinearRegression() #实例化
model = linreg.fit(x_train, y_train)
print(model)
print('截距项为:', linreg.coef_) #输出截距项,即我们熟悉的ax+b的b值
print('权重项为:', linreg.intercept_) #输出权重项,即我们熟悉的ax+b的a值,此处是向量!
#进行预测
y_hat = model.predict(x_test)
#评价
mse = np.average((y_hat - np.array(y_test)) ** 2) # Mean Squared Error均方误差
print('得分为:', mse)
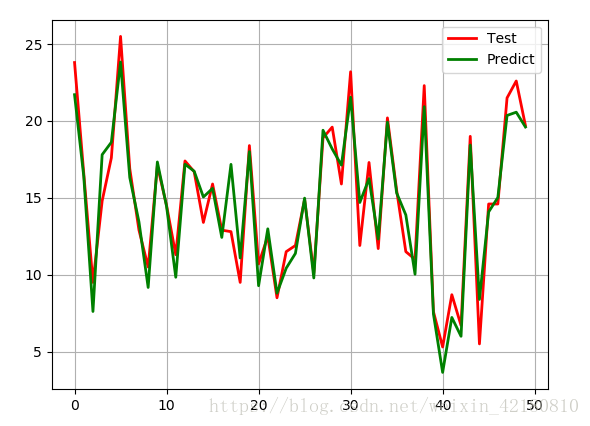
#绘制预测对比图
t = np.arange(len(x_test))
plt.plot(t, y_test, 'r-', linewidth=2, label='Test')
plt.plot(t, y_hat, 'g-', linewidth=2, label='Predict')
plt.legend(loc='upper right')
plt.grid()
plt.show()输出结果分别有:
散点图:
对比图结果: