
本节课主要讲了依存句法分析
文章目录
- 语言结构的两种观点
- Dependency Grammar and Dependency Structure
- Dependency Grammar/Parsing History
- Dependency Grammar and Dependency Structure
- The rise of annotated data: Universal Dependencies treebanks
- Dependency Conditioning Preferences
- Dependency Parsing
- Methods of Dependency Parsing
- A neural dependency parser
- 参考
语言结构的两种观点
Constituency Parsing
Constituency = phrase structure grammar = context-free grammars (CFGs)
短语结构将单词组织成嵌套的成分–》可以使用CFG规则来表示
- 单词被分了类(POS:词性标注)

- 单词根据类别组合成短语

- 短语可以递归的组合成更大的短语


本文中介词短语在名词之后
Dependency structure
依赖结构显示了哪些单词依赖于(修饰或是其参数)哪些其他单词
下图例子中:

箭头表示依赖于
"look"依赖于crate:看到的是crate
“crate"依赖于"in,the,large”
之后的同理
Why do we need sentence structure?
- 为了能够正确解释句子,我们需要正确理解句子结构
- 人类通过将词组合成更大的单元来传达复杂的含义,从而交流更加复杂的想法
- 我们需要知道什么连接的什么。(哪些词修饰哪些词)
一些歧义
- 介词短语依附歧义

San Jose cops kill man with knife- 解释一:警察用刀杀了那个人
with knife修饰kill - 解释二:警察杀了那个拿着刀的人
with knife 修饰man

这句话也有歧义:from space分别修饰count和whales会得到两种不同的解释
一个关键的解析决定是我们如何正确将各种成分(介词短语、状语或分词短语、不定式、协调等)与其所修饰的名词结合起来

这句话一共有四个介词短语,每个介词短语都有可能修饰在其之前的某个名词。正确的解释如图中绿色箭头所示。
因此总共的可能组合个数为Catalan数: ,指数级的增长
- 解释一:警察用刀杀了那个人
- 协调范围模糊(Coordination scope ambiguity)

这句话有两种解释:- 第一种:只有一个人:航天飞机老兵、长期担任美国宇航局执行官的弗雷德·格雷戈里被任命为董事会成员
- 第二种:两个人:航天飞机老兵和长期担任美国宇航局执行官的弗雷德·格雷戈里被任命为董事会成员

- 形容词修饰歧义(Adjectival Modifier Ambiguity)

第一种解释:红色箭头所示,first hand 和job都修饰experience,表示学生获得第一手的工作经验
第二种解释:绿色箭头,first和hand job修饰experience(这里上课时学生都哈哈大笑,so自己想想含义:)) - 动词短语依附歧义(Verb Phrase (VP) attachment ambiguity)

to be used for Olympic beach volleyball 是 动词短语 (VP)
但修饰的是body韩式beach,这里有歧义
依赖路径识别语义关系
Dependency paths identify semantic relations –e.g., for protein interaction

Dependency Grammar and Dependency Structure
依赖句法假设句法结构由词汇项之间的关系组成,通常是称为依赖关系的二进制非对称关系(“箭头”)。
箭头通常与语法关系(主语、介词宾语、同位语等)的名称一起键入,如下图所示

Dependency Grammar/Parsing History
- 依赖结构的概念由来已久
- 到Pāṇini的语法(约公元前5世纪)
- 一千年阿拉伯语语法学家的基本方法
- 无选区/上下文文法是一项新发明
- 20世纪的发明(R.S.Wells,1947;然后是乔姆斯基)
- 现代依赖性工作通常来源于L.Tesnière(1959)
- 是20世纪“东方”的主导方法(俄罗斯,中国,…)
- 有利于更自由的语序语言
- 是20世纪“东方”的主导方法(俄罗斯,中国,…)
- 在NLP最早的解析器中,甚至在美国:
- 大卫·海斯,美国计算语言学的奠基人之一,很早就建立了(第一个?)依赖分析器(Hays 1962)
Dependency Grammar and Dependency Structure
Dependency Parsing有两种做法
一种是直接在句子上标出依存关系箭头及语法关系

另一种是将其做成树状机构(Dependency Tree Graph)

- 人们对箭头指向的方式不一致:有些人把箭头朝一个方向画;有人是反过来的
- Tesnière 从头开始指向依赖,本课使用此种方式
- 通常加一个伪根(fake ROOT),这样每个单词都精确地依赖于另一个节点
The rise of annotated data: Universal Dependencies treebanks
[Universal Dependencies: http://universaldependencies.org/ ; cf. Marcus et al. 1993, The Penn Treebank, Computational Linguistics]

- 首先,构建树库比构建语法要慢得多,也没那么有用
- 但是treebank给了我们很多东西
- 劳动的可重用性
- 许多分析器、词性标记器等都可以建立在它之上
- 语言学的宝贵资源
- 广泛的覆盖,不仅仅是一些直觉
- 频率和分布信息
- 评价系统的一种方法
- 劳动的可重用性
Dependency Conditioning Preferences
依赖关系解析的信息来源是什么?
- Bilexical affinities (两个单词间的密切关系)
- Dependency distance 依赖距离
- Intervening material 介于中间的物质
- Valency of heads
Dependency Parsing

一个句子通过为每个单词选择它所依赖的其他单词(包括词根)来进行分析
- 通常有一些限制:
- 只有一个单词是依赖于根的
- 不存在循环
- 这使得依赖关系成为一棵树
- 最后一个问题是箭头是否可以交叉(非投射的)
Projectivity
- Defn:当单词以线性顺序排列时,没有交叉的依赖弧,所有的弧都在单词上方
- 与CFG树并行的依赖项必须是投影的
- 以每一类的一个子类为头,形成依赖关系
- 但是依赖理论通常允许非投射结构来解释位移成分
- 如果没有这些非投射依赖,就不可能很容易获得正确的某些构造的语义
Methods of Dependency Parsing
- Dynamic programming
艾斯纳(1996)给出了一个复杂的O(N3)的聪明算法,通过在端部而不是在中间产生头部的解析项。 - Graph algorithms
为句子创建最小生成树
McDonald等人(2005)的MSTParser使用ML分类器独立地对依赖项进行评分(他使用MIRA进行在线学习,但它可能是其他的东西) - Constraint Satisfaction
不满足硬约束的边将被删除。卡尔森(1990)等。 - “Transition-based parsing” or “deterministic dependency parsing”
由好的机器学习分类器MaltParser(Nivreet al。2008年)。已经证明是非常有效的
本文介绍此种算法
Greedy transition-based parsing
[Nivre2003]
- 解析器执行一系列自下而上的操作
- 大致类似于shift-reduce解析器(规约法)中的“shift”或“reduce”,但是“reduce”操作专门用于创建头部位于左侧或右侧的依赖项
Transition-based Dependency Parsing可以看做是state machine,对于 ,state由三部分组成
- 是S中若干 构成的stack
- 是S中若干 构成的buffer
- A是dependency arc构成的集合,每一条边的形式是 ,其中r描述了节点的依存关系,如动宾关系等。
- 一组操作
最终的目标是 ,A包含了所有的依存弧
Basic transition-based dependency parser

SHIFT:将buffer中的第一个词移出并放到stack上。
LEFT-ARC:将
加入边的集合
,其中
是stack上的次顶层的词,
是stack上的最顶层的词。即最顶层指向次顶层。
RIGHT-ARC:将
加入边的集合
,其中
是stack上的次顶层的词,
是stack上的最顶层的词。即次顶层指向最顶层。
我们不断的进行上述三类操作,直到从初始态达到最终态。在每个状态下如何选择哪种操作呢?当我们考虑到LEFT-ARC与RIGHT-ARC各有|R|(|R|为r的类的个数)种class,我们可以将其看做是class数为2|R|+1的分类问题,可以用SVM等传统机器学习方法解决。
一个例子
Arc-standardtransition-based parser
Analysis of “I ate fish”
下图给出了一个正确的转移策略,当然还有其他的转移策略


MaltParser
[Nivreand Hall 2005]
- 每个动作都由一个区分性分类器(例如,softmax分类器)对每个合法动作进行预测
- 最多三种无类型的选择,当带有类型时,最多
- Features:栈顶单词,POS;buffer中的第一个单词,POS;等等
- 在最简单的形式中是没有搜索的
- 但是,如果你愿意,你可以有效地执行一个 Beam search 束搜索(虽然速度较慢,但效果更好):你可以在每个时间步骤中保留 k个好的解析前缀
- 该模型的精度略低于依赖解析的最高水平,但它提供了非常快的线性时间解析,性能非常好
Conventional Feature Representation

- 传统的特征表示使用二元的稀疏向量
- 特征模板:通常由配置中的1 ~ 3个元素组成
- Indicator features
Evaluation of Dependency Parsing: (labeled) dependency accuracy

其中,UAS (unlabeled attachment score) 指 无标记依存正确率 ,即只要arc的箭头方向正确即可。LAS (labeled attachment score) 指 有标记依存正确率,即只有arc的箭头方向以及语法关系均正确时才算正确.
A neural dependency parser
[Chen and Manning 2014]
- Unlabeled attachment score (UAS) = head
- Labeled attachment score (LAS) = head and label

传统的Transition-based Dependency Parsing对feature engineering要求较高,我们可以用神经网络来减少human labor。
Distributed Representations
- 我们将每个单词表示成一个d维向量(词嵌入)
- 相似的单词词向量应该相近
- 同时,POS和依赖标签也用d维向量表示
- 较小的离散集也表现出许多语义上的相似性
- NNS(复数名词)和NN单数名词应该相近
- num(数词修饰词)应该和amod(形容词修饰词)相近
对于Neural Dependency Parser,其输入特征通常包含三种:
- stack和buffer中的单词及其dependent word。
- 单词的Part-of-Speech tag。
- 描述语法关系的arc label。

我们将其转换为embedding vector并将它们联结起来作为输入层,再经过若干非线性的隐藏层,最后加入softmax layer得到每个class的概率。
模型架构如下

Dependency parsing for sentence structure
- 神经网络能准确地确定句子的结构,支持解释

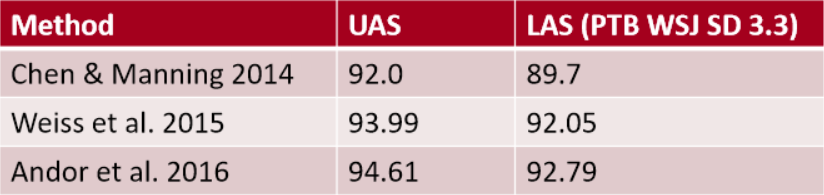
- Chen and Manning(2014)是第一个简单、成功的神经依赖分析器
- 密集表示使它在准确性和速度上都优于其他贪婪的解析器
Further developments in transition-based neural dependency parsing
-
这项工作得到了其他人的进一步发展和改进,特别是在谷歌
- 更大、更深的网络,具有更好的调优超参数
- Beam Search 更多的探索动作序列的可能性,而不是只考虑当前的最优
- 全局、条件随机场(CRF)的推理出决策序列
-
引出了SyntaxNet和Parsey McParseFace模型
https://research.googleblog.com/2016/05/announcing-syntaxnet-worlds-most.html
Graph-based dependency parsers
为每条边的每个可能的依赖项计算分数
例如,选择big为head

- 然后将每个单词的边缘添加到得分最高的候选单词头上
- 并对每个单词重复相同的操作

A Neural graph-based dependency parser
[Dozat and Manning 2017; Dozat, Qi, and Manning 2017]
- 在神经模型中为基于图的依赖分析注入活力
- 为神经依赖分析设计一个双仿射评分模型
- 也使用神经序列模型,我们将在下周讨论
- 为神经依赖分析设计一个双仿射评分模型
- 非常棒的结果
- 但是比简单的基于神经传递的解析器要慢
- 在一个长度为 n 的句子中可能有
个依赖项

- 在一个长度为 n 的句子中可能有
个依赖项
- 但是比简单的基于神经传递的解析器要慢
参考
- 官方讲义:https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/slides/
- 其他人博客:
https://zhuanlan.zhihu.com/p/66268929
https://looperxx.github.io/CS224n-2019-05-Linguistic
此博客中含有神经网络解析器有更加详尽的介绍,不太懂了可以看这里
