文章目录
课堂问答
- A0: 下面关于优化算法的比较应该都是以凸优化问题举例的。
- Q1: 带有动量的SGD怎么处理不好的梯度方向?
- Q2: Dropout层在哪里使用?
- A2: 一般在全连接层后面添加DP使得某些神经元失活,当然也可以在卷积层后面添加,但是具体的做法使使得部分卷积核得到的激活图(activation map)置0.
- Q3: Dropout 对于梯度的回传有什么影响?
- A3: Dropout 使得梯度回传仅发生在部分神经元,使得我们的训练更加缓慢,但是最后的鲁棒性更佳。
- Q4: 一般,我们采用几种正则化方法?
- A4: 通常,我们会使用BN,因为其确实会起到正则化的作用。但是,我们一般不交叉验证需要使用哪些正则化方法,而是有的放矢的,当我们发现模型过拟合了,适当的添加正则手段。
1. 更好的优化 (Fancier optimization)
1.1 SGD 优化
之前,我们介绍了一个简单的梯度更新算法 SGD,它是固定步长,沿着负梯度方向的更新:

但是,它也会有一些问题。
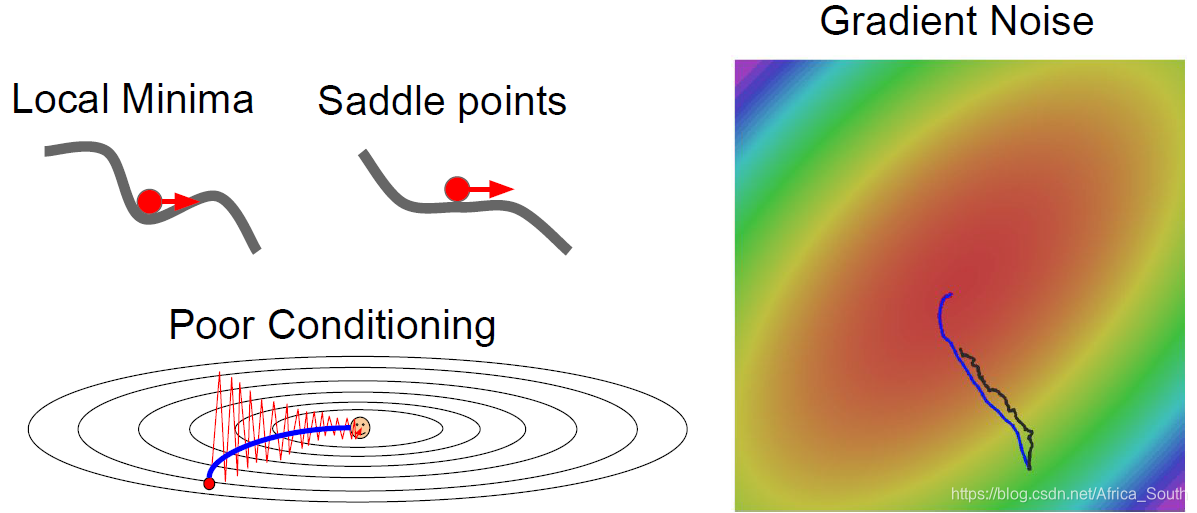
- 假设我们有损失函数L和二维的权重W,且损失L对于W的一个方向(维度)上变化不敏感(比如水平),对于另一个方向(例如竖直)变化则比较敏感,则按道理来说,如果沿着竖直方向更新,则我们的损失会下降的比较快。
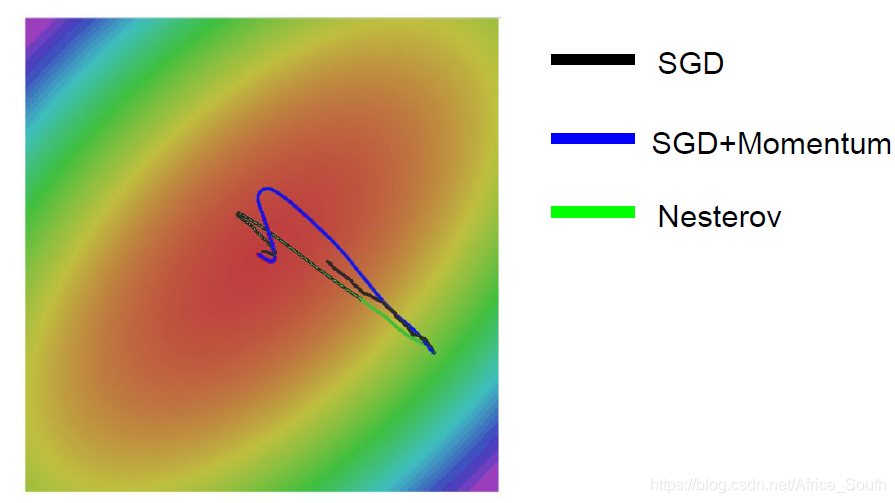
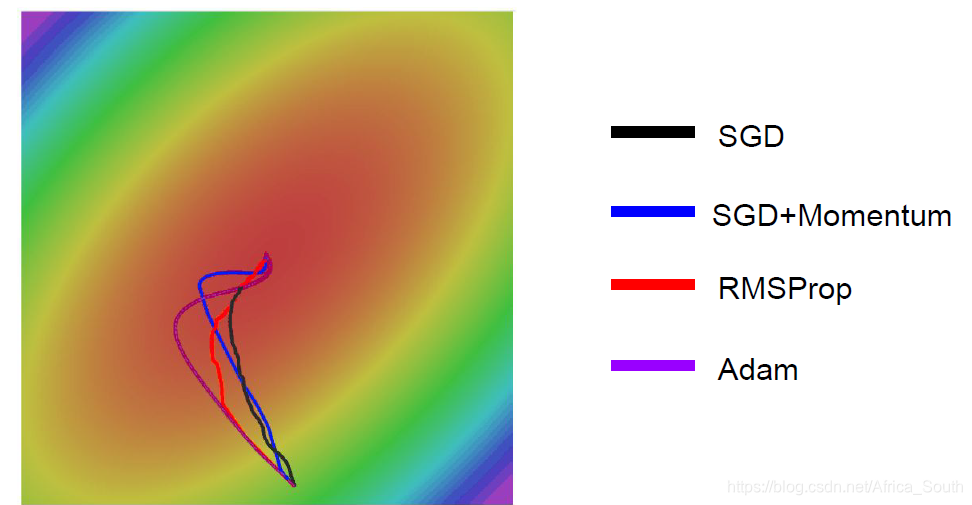
但是 SGD 算法,使得我们沿着两个方向的合方向进行更新,整体上来讲就会呈现之字形(抖动),如下图,等高线表示沿着水平方向损失变化很小。

- 上述情况在一个高维矩阵上表现得更加明显,因为梯度的方向更加的复杂。
- 比较容易陷入 局部最小值 和 鞍点
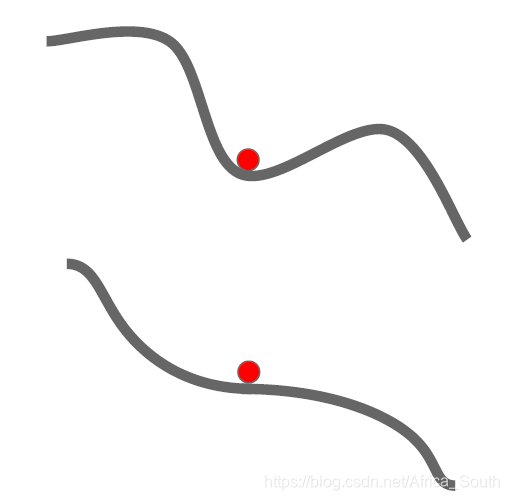
- 局部最小值梯度等于0,使得权重几乎无法更新;鞍点附近梯度很小,使得权重更新的很慢(特别是在高维的情况,鞍点特别多)。
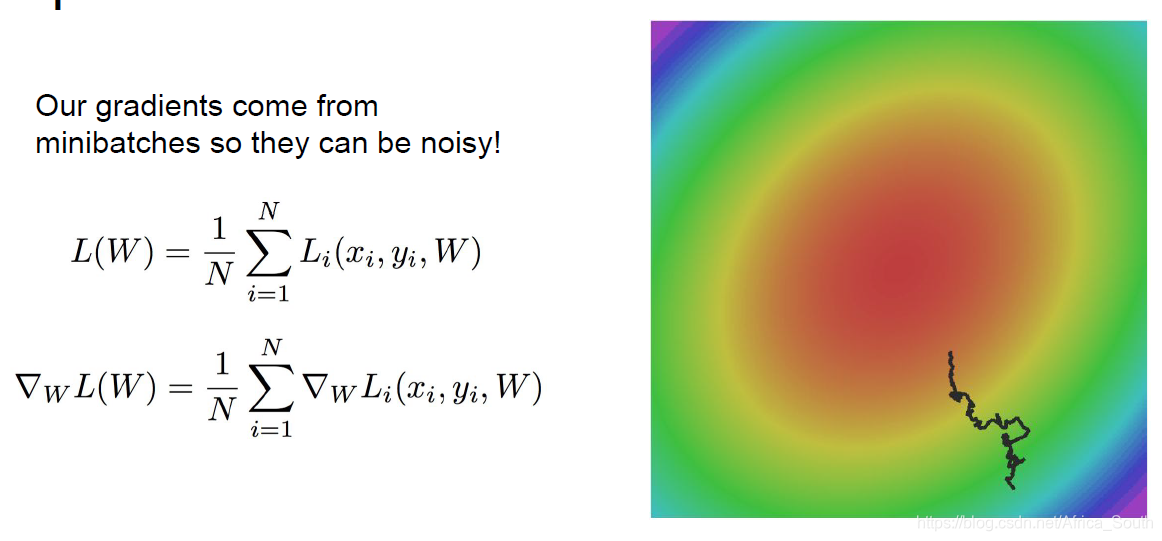
- SGD 是在一个样本上计算梯度,但是这样当样本数很多的时候,我们的计算量太大。所以,我们经常采用的是小批量(Mini-batch)SGD,但是这样的梯度是一个批量的估计值,可能会引入噪声,使得参数更新比较曲折。
1.2 基于动量的(Momentum)SGD
SGD+Momentum
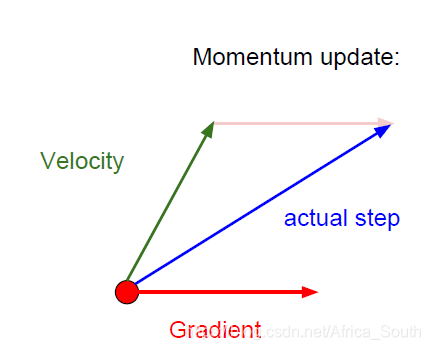
- 即在我们的梯度项上加上一个动量项:

- 它使得我们在局部最小点和鞍点依然有一定的速度。而对于之前的之字形下降,它会在敏感的方向上更快的积累速度,而在不那么敏感的方向上放缓速度,从而容易抵消这些抖动:
- 同时,动量的更新方向是之前的速度+当前的梯度,它能在一定程度上避免噪声误差。
Nesterov Momentum + SGD

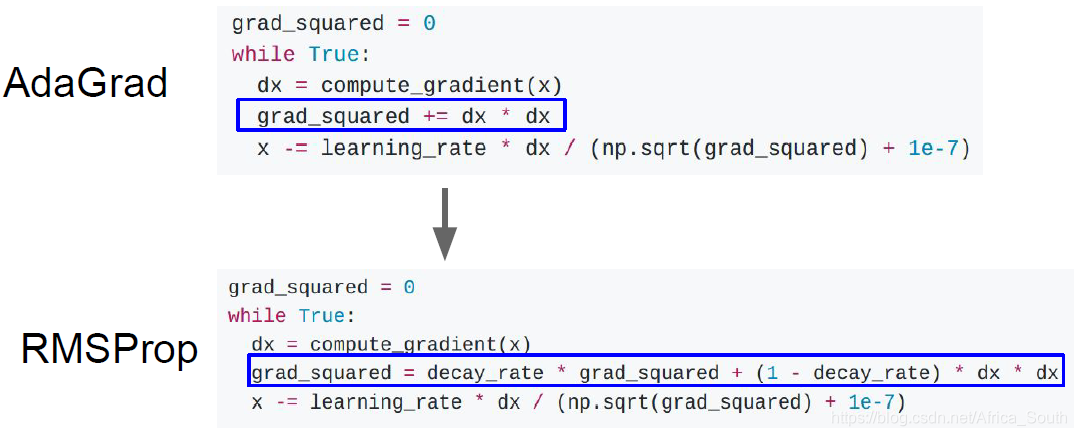
1.3 AdaGrad
- 核心是维持一个在训练过程中的 梯度平方 的估计

- 这种梯度的累加会减缓梯度大的维度方向上的更新步长,相反会增加梯度小的维度方向上的更新步长。即它会在每一个维度上进行差不多的优化。
- 当我们训练持续进行时,随着梯度的累积,学习步长会越来越小。当目标函数是一个凸函数的时候,当接近极值点的时,我们走的越来越慢。但是对于非凸函数,或许会陷入局部最优点。
变体-RMSProp
- 像之前的动量一样,我们在加的 梯度平方 上添加一个 历史衰减。
1.4 Adam
- 这个优化方法是前两个方法思想的结合。

- Q: 前几次更新的时候是什么情况?
- A: 我们的加权因子一般取0.9或者0.99,刚开始的时候,第二动量比较小,如果这是第一动量不是很小的情况下,就会产生一个很大的更新步长。
- 所以,我们实际使用的Adam是下面的形式:
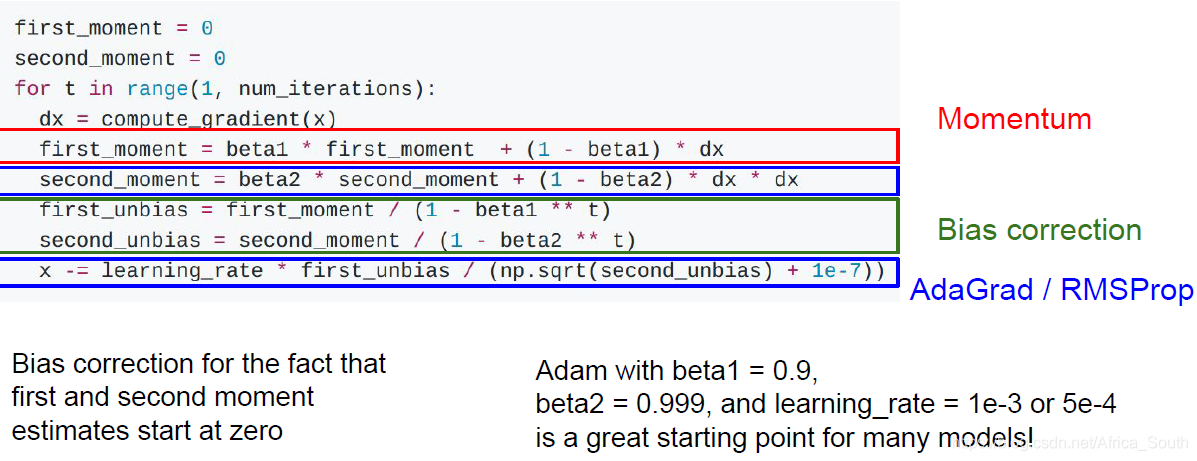
- 其引入一个纠正偏差(bias correction),当我们刚开始的动量比较小的时候,会进行修正。
1.5 学习率的选择
- 在我们的所有优化算法中,我们都需要制定初始的学习率,通常有下面几种做法:
迭代周期衰减、指数衰减和分数衰减

- 一般在带动量的SGD时使用学习率衰减,但是Adam可以不用。而且不是一上来就采用步长衰减,而是先调试其它参数,当观察损失函数平坦的时候可以尝试进行学习率衰减。
1.6 二阶优化(Second-Order Optimization)
- 之前的优化方式都是一阶优化,即在一阶偏导数上操作的。
-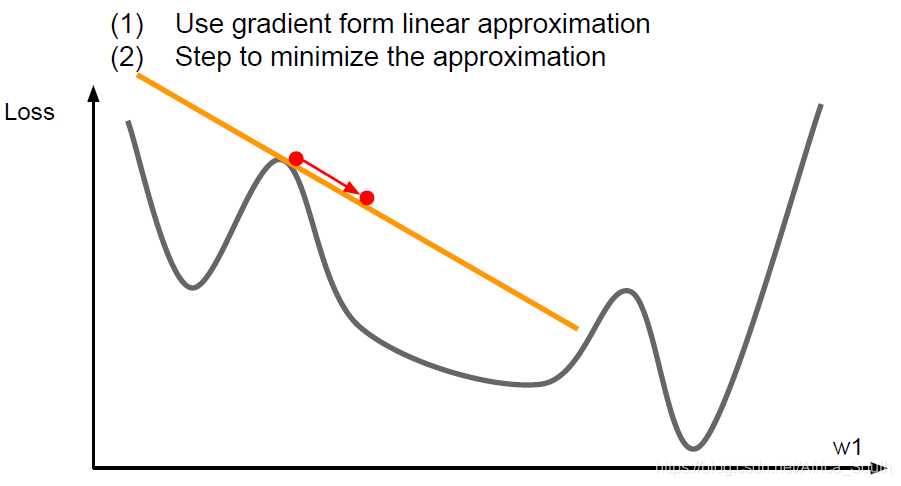
- 它相当于在当前点使用 一阶泰勒展开 来进行逼近。
- 所以,我们还可以使用当前点的 二阶泰勒展开 来进行逼近,同时使用一阶偏导和二阶偏导来进行优化:
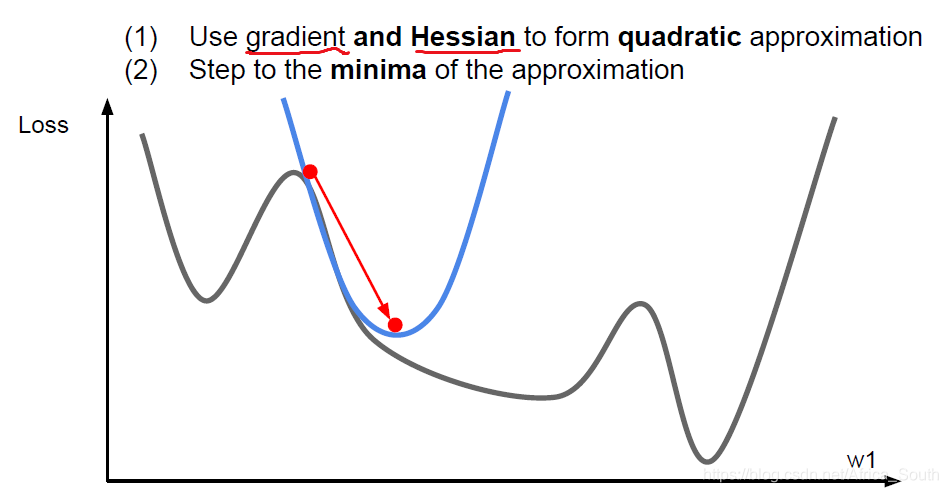
- 二阶优化之一就得到了我们的 牛顿步长(Newton Step)

- 这里我们没有学习率,因为是在该点进行了 二阶泰勒展开, 然后直接更新到该二次函数的最小点处。(但是后续 牛顿下降法 的版本可能添加了学习率)。
- 但是,这里求海瑟阵的逆在深度学习中是不切实际的,所以有时候也可以使用一个二阶逼近,即 拟牛顿法。

- 所以,我们也有二阶优化器——L-BFGS。但是对于深度神经网络或许并不适用。

1.7 模型集成
之前我们讲的优化算法,更多的时候关系的是如何在训练的时候得到足够好的性能,但是往往我们 更关注模型在测试集合上的表现。
可以使用的方案之一就是 模型集成(Model Ensembles),可以适当减缓过拟合,而且多个模型的超参数可以不一样

2. 正则化 (Regularization)
提升模型的泛化能力,减轻过拟合还有一种方案就是——正则化,其在某种意义上为不要让模型过于复杂。
2.1 权重约束
一种正则化方式就是给学习权重添加范数约束:
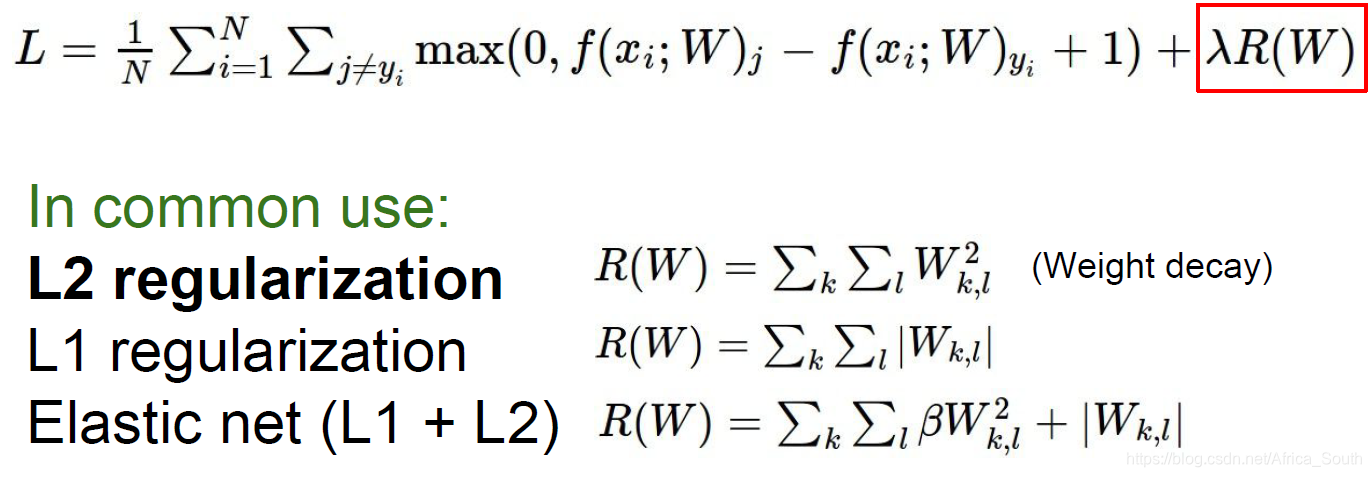
2.2 随机失活(Dropout)
即我们在前向传播的时候,随机以概率P使得某些层的某些神经元的激活值为0,使其失活。
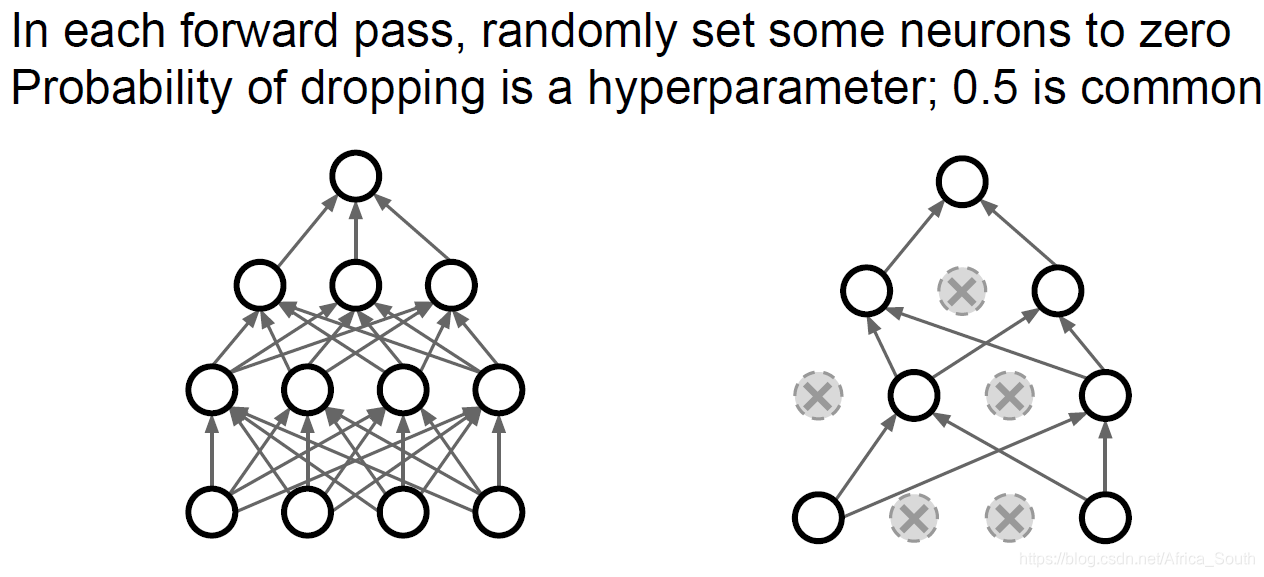
例如一个两层的神经网络的DP:

解释
- 可以避免特征之间的强相关,使得网络仅得到部分特征也能正常工作。
- 或者当作多个子网络的 集成学习。
测试操作
在测试的时候我们进行了随机失活,但是测试的时候应该怎么做了?
肯定不能是随机失活,因为这可能造成模型对相同的输入给出不同的输出。
理想情况下,我们的输入是原始输入X和一个掩码Z,所以,我们想要计算出关于这个随机的Z的平均值:

但是这相当的困难,所以,我们可以做一个局部近似,假设我们的失活概率为0.5:

所以,我们只需要将输出值乘以我们的 失活概率 即可。

但是,有时候我们不希望在测试的时候多引入一个矩阵的数乘操作,而是将其放在训练阶段,因为训练阶段通常在GPU上进行,所以,我们可以使用 “Inverted Dropout”。
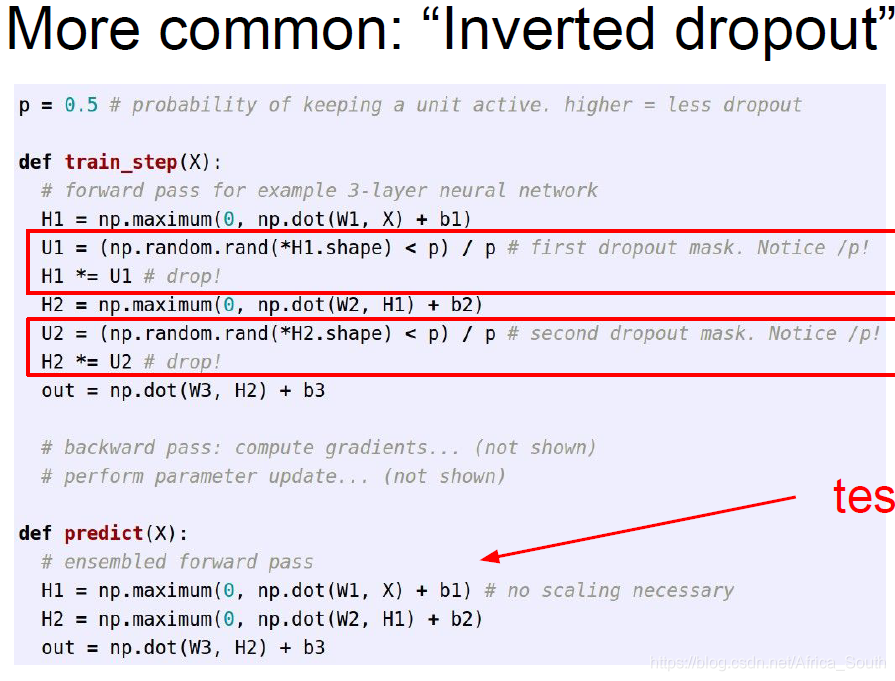
推广
类似于Dropout,我们在训练的时候引入一些随机性以防止它过拟合训练数据,并在测试的时候平均抵消掉其影响。
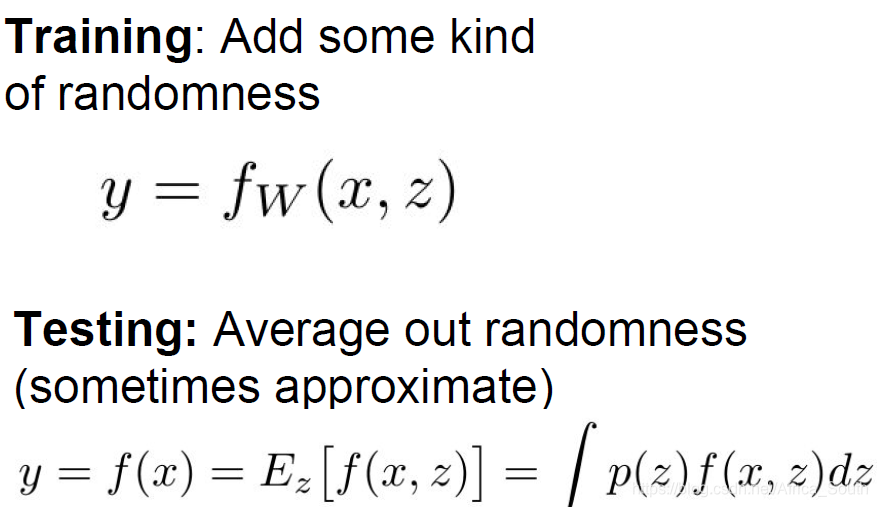
而我们之前讲的 批量归一化BN 也符合这种策略:
即在训练的时候在一个小批量上计算经验值,但是单个数据出现的批次具有随机性:

当然,还有一种类似的策略就是在训练的时候进行 随机数据增强:


2.3 局部最大池化
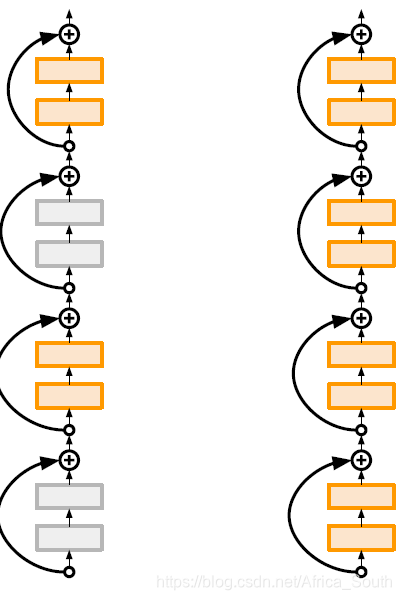
2.4 随机深度
就是在训练的时候随机丢掉一些网络层,而在测试的时候使用全部网络层:
3. 迁移学习 (Transfer Learning)
迁移学习能够在训练数据不够的情况下,减少过拟合的程度。 其在大型的数据集上先训练一个模型,然后将其权重运用在小数据集上,并进行适当调整(即冻结某些层的权重不变,更新其它层的权重)
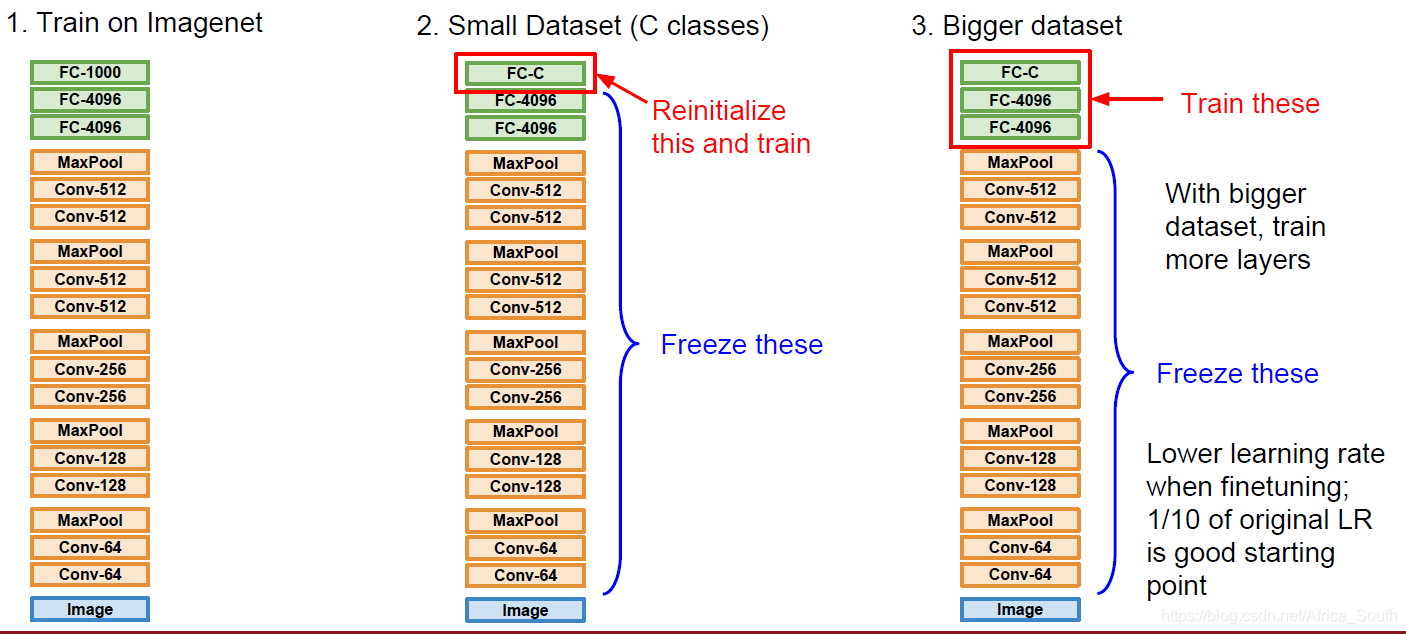
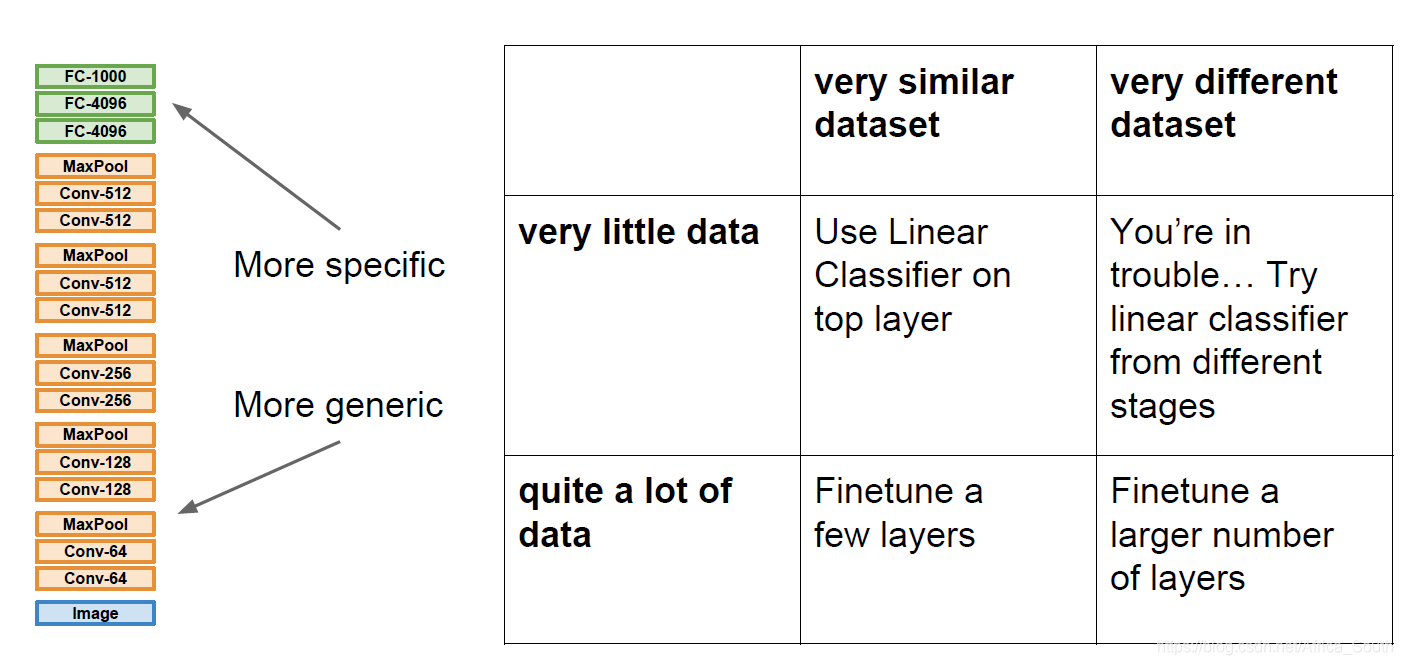
通常,CNN底层的特征是更通用的低级、中级特征,所以,可以进行迁移,然后对头部进行微调。对于不同的情况,我们以如下不同的策略:
现有的一些神经网络框架也会公开自己的预训练模型:

总结

