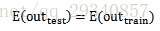CS231n系列课程笔记:作为本人的笔记记录,并无商用用途
CS231n:http://cs231n.stanford.edu/
参数更新(Parameter Update)
本文参数更新主要针对神经网络中反向传播过程中weights和biases的更新方式做的笔记。
SGD
缺点:水平方向平缓,垂直方向陡峭时,SGD容易发生抖动,找到最优解的时间最长
参数更新公式:
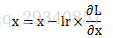
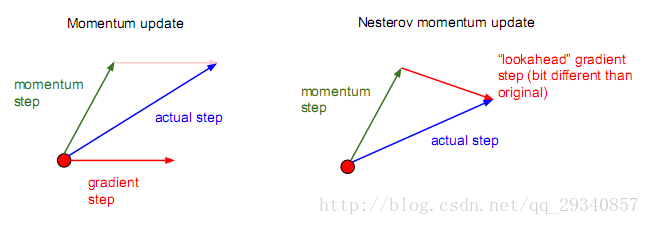
Momentum
解释:梯度更新方向不再是只考虑梯度下降最快的方向,还考虑原来梯度下降的方向
参数更新公式:
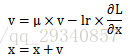
SGD vs. Momentum:相同条件下,Momentum相较于SGD收敛的更快
Nesterov Momentum
解释:考虑原来梯度更新的方向和当前梯度下降的方向
公式表示: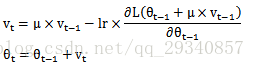
第一项公式的第一个乘积项相当于原来梯度更新方向,第一项公式的偏导项相当于假想的当前梯度更新方向
为了方便理解,此处借用原始课件上的示意图:
AdaGrad
利用水平方向的梯度累积减缓更新梯度,但是更新次数累积越多,更新梯度接近零
公式表达:
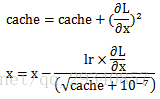
RMSProp,Tieleman&&Hinton(2012)
加入衰减系数,解决更新次数累积导致更新梯度接近零的问题
公式表达:
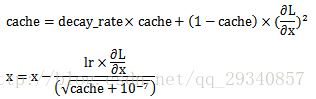
Hinton大神的课件截图:

Adam
结合了Momentum和RMSProp的特点
公式表达: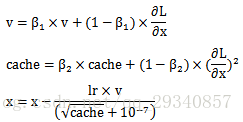
第一行公式结合了Momentum的特点。第二行公式结合了RMSProp的特点
总结:参数更新推荐默认选择Adam更新参数,收敛更快
学习率衰减(Learning Rate Decay)
在反向传播进行参数更新的过程中,需要对学习率设置衰减条件,否则在接近极值点时会发生抖动现象而找不到极值点。以下是学习率衰减的三种常见方式总结:
- step decay
e.g. 学习率每五步减半 - 指数衰减(exponential decay)
公式表达: - 1/t衰减(1/t decay)
公示表达:
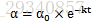
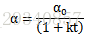
模型集成(Model Ensemble)
步骤:
1. 分开训练几个独立的模型
2. 测试时,对这几个模型取均值
优势:提升模型准确率
正则化(Regularization)之Dropout
Dropout首次提出是在2012年ImageNet大赛中,由Hinton等人提出来的正则化方法,和ReLU一起被应用到AlexNet中,并取得当年的冠军,由此深度神经网络被广泛运用在图像识别项目中。
实施过程:在一次批量训练过程中,在一定的dropout概率下,随机将隐藏层的节点置为非激活状态(利用ReLU作为激活函数,该节点永远不会被激活)
理解:每一次的批量训练的随机dropout网络节点可以视为每次批量训练都训练了一个独立的网络模型。最终,多次批量训练后的网络模型ensemble在一起,形成一个新的网络模型。
课件中关于dropout的示意图:
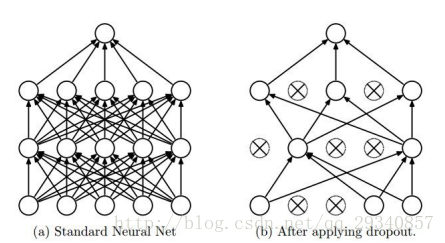
测试时,所有网络节点都是激活状态,但是实施了dropout的隐藏层都要乘以dropout的概率,这样做是为了保持