Fast-SCNN: Fast Semantic Segmentation Network
论文地址:https://arxiv.org/pdf/1902.04502.pdf
Abstract
就目前来说,Encoder-decoder 仍是 state of art 的线下语义分割方式。随着自动化系统的出现,计算的实时性变得越来越迫切。在这篇论文,作者提出了一个快速卷积神经网络(Fast-SCNN),该语义分割模型在高分辨率图像上( )上也能达到实时效果,很适合在嵌入式设备上运行,并且内存消耗很低。基于现有的快速语义分割的 two-branch 方法,我们引入了“学习下采样”(learn to downsample)模块,它能同时针对多个分辨率分支计算低层次的特征。此网络将高分辨率的空间细节信息和低分辨率的深度特征结合起来使用,在Cityscapes数据集上,它的速度有123.5帧每秒,mean intersection over union 为68%。我们同样证明大规模预训练是非必要的。我们用ImageNet和Cityscapes数据集上进行了详尽的预训练试验,验证了我们的想法。
1. Introduction
快速语义分割在实时应用中特别重要,输入的图像需要被快速解析,辅助系统与环境进行及时的交互。我们认为超过实时的性能事实上是非常必要的,因为语义标签通常是作为其它任务的先决条件。而且,嵌入式设备(没有强大的GPU)上实时的语义分割也有助于其它应用的实现,比如可穿戴设备的增强现实功能。
我们观察到,在学术领域语义分割通常是用深度卷积网络和 encoder-decoder 框架实现的,而且许多效率高的实现方法采用了 multi-branch 的结构。
- 较大的感受野对学习物体类别的复杂关系很重要;
- 图像上的空间细节信息对保留物体的边界很必要;
- 为了平衡速度和精度,需要一些特别的设计;
尤其是 two-branch 网络,它在低分辨率位置使用一个较深的 branch 来捕捉环境信息,在高分辨率位置使用一个较浅的 branch 来学习细节信息。然后,将这二者融合起来,形成最终的语义分割结果。较深的网络虽然计算成本高,但是它的输入也较小,全分辨率输入也只存在于少数几个层,这样我们在目前的GPU上达到实时性就是可能的。与 encoder-decoder 不同,分辨率不同的前几个卷积层在 two-branch 方法上是不共享的。值得注意的是,在 Guided Upsampling Network 和 Image Cascade Network 只在起初的几个新层上共享了权值,而没共享计算过程。
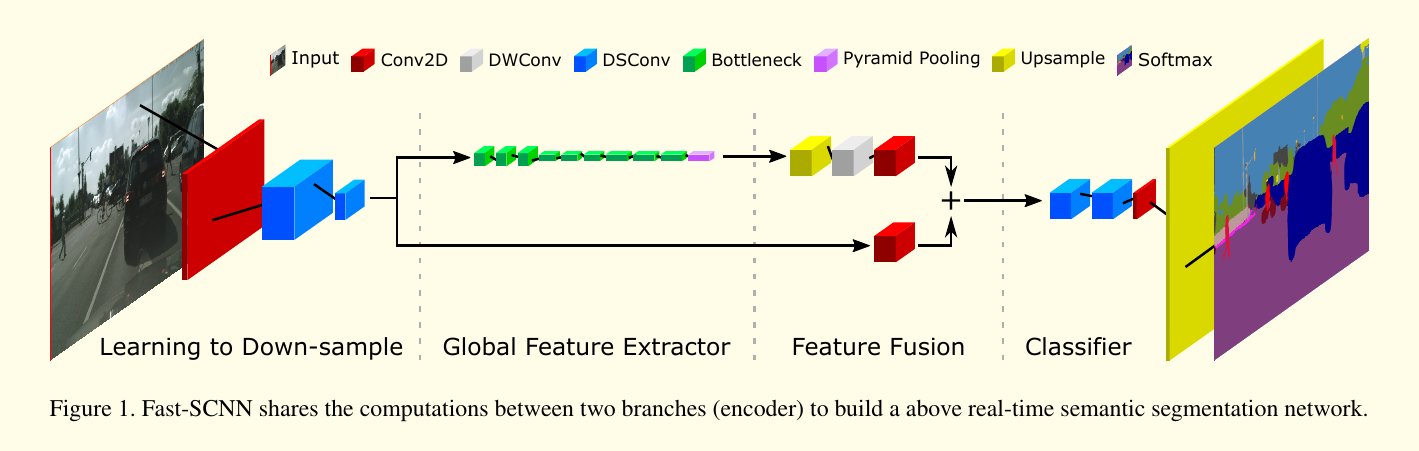
在这篇论文中,我们提出了快速分割卷积神经网络—Fast SCNN,该算法通过融合 two-branch 方法和经典的 encoder-decoder 方法,从而达到了实时效果(图1)。根据观察发现,深度卷积网络中的前几个层提取的是低阶段特征,我们借鉴了 two-branch 的方法,将前几个层的计算进行共享。我们将此称为“学习下采样”(learn to downsample)。它的作用和 encoder-decoder 中的 skip connection差不多,但是 skip 只用了一次,目的是维持运行时效率,而且那个模块很浅用于保证特征的共享。最后,我们的 Fast-SCNN 使用了高效的 depthwise separable 卷积和 inverse Residual blocks。
Fast-SCNN 在Cityscapes 上试验了下,输入图像分辨率为 ,使用Nvidia Titan Xp(Pascal),它的mIoU准确率为68%,速度为123.5帧每秒。这比BiSeNet(71.4%的mIoU) 快了两倍。
我们使用了111万个参数,绝大多数的分割方法(DeepLab 和 PSPNet),以及一些实时算法(GUN和ICNet)的参数个数远比这个多。Fast-SCNN的 capacity 被限制的很低,主要有2个原因:
- 低内存消耗可以运行在嵌入式设备上;
- 通用型更强;
人们常说,在ImageNet上进行预训练可以提升准确率和通用型。在这篇论文中,我们研究了在low capacity Fast-SCNN 上的预训练效果。与 high capacity 模型不同,我们发现预训练或者额外的 coarsely 标注的数据,它们所带来的提升不明显(在Cityscape上约 mIoU)。
此论文的贡献主要为:
- 提出了一个实时语义分割算法 - Fast-SCNN,在高清图像上准确率为68%,速度为123.5帧每秒;
- 调整了 skip connection,提出了一个浅层的 learning to downsample 模块,可以快速而高效地通过 multi-branch 来提取低层次特征;
- 我们特别设计了low capacity Fast-SCNN,我们验证了对于small capacity网络而言,多训练几个 epoch的效果和在ImageNet上进行预训练是一样的。
2. Related Work
我们讨论和比较了语义分割框架,主要关注在实时性上,低能耗,低内存要求。
2.1 Foundation of Semantic Segmentation
State of art 语义分割方法都将两个可分离模块结合起来:encoder 和 decoder。Encoder 利用卷积和池化操作提取深度卷积网络特征。Decoder 模块从低分辨率特征上恢复空间信息,然后预测物体标签。通常,encoder 是从一个简单的深度卷积网络变形过来的,如VGG或ResNet。在语义分割中不使用全连接层。
全卷积网络 - FCN 是目前语义分割框架的基石。FCN将VGG作为 encoder,然后将双线性上采样和连接较低层的 skip connection 结合起来恢复空间细节信息。
随后,受全局图像信息启发,PSPNet 中的金字塔池化模块和DeepLab中的 atrous 空间金字塔池化(ASPP)用于 encode 和利用全局信息。
与目标检测类似,速度是语义分割系统设计中的一个重要因素。基于FCN,SegNet 引入了一个联合 encoder-decoder 模型,是最早的高效率分割模型之一。延续SegNet,ENet 也设计了 encoder-decoder ,层数较少,降低计算成本。
然后,two-branch 和 multi-branch 系统出现了。ICNet, ContextNet, BiSeNet, GUN 通过一个较深的 branch 在低分辨率输入上学习全局信息,通过一个较浅的 branch 在高分辨率图像上学习细节信息。
但是,state of art 的语义分割仍具挑战,通常需要高性能GPU。受 two-branch 启发,Fast-SCNN 加入了一个共享的浅层网络来编码细节信息,在低分辨率输入上高效地学习全局信息。
2.2 Efficiency in DCNNs
深度神经网络的常用技术主要有以下4类:
- Depthwise Separable 卷积:MobileNet 将一个标准卷积分为 depthwise 卷积和 的 pointwise 卷积,称作 depthwise separable卷积。这种拆分降低了浮点数计算和卷积参数个数,因此降低了计算成本和内存消耗。
- 深度神经网络高效的重新设计:Chollet 设计了Xception 网络,使用高效的 depthwise separable 卷积。MobileNet-V2提出了 inverted bottleneck residual block 来构建一个高效率的深度网络,用于分类任务。ContextNet 使用 inverted bottleneck residual block 设计了一个 two-branch 网络,用于实时语义分割。
- 网络量化:浮点计算相较于整型和二进制操作要昂贵的多,模型运行时间可以进一步通过量化技巧来缩短。
- 网络压缩:Pruning 可以用于减小预训练网络的 size,使得运行速度更快,参数个数更少,内存消耗也更少。
Fast SCNN 依赖 depthwise separable convolution 和 residual bottleneck block。此外,我们引入了一个 two-branch 模型,融合了我们的"learn to downsample" 模块,使我们可以在不同的分辨率输入上进行特征提取(图2)。尽管 multi-branch 的前几个层提取的特征很相似,但是 two-branch 方法没有用到这个。网络量化和网络压缩留作未来研究。
2.3 在辅助任务上预训练
通常人们认为,在辅助任务上进行预训练可以提升系统的精度。之前的目标检测和语义分割工作在 ImageNet 上证明了这点。所以,其它的实时语义分割方法也在 ImageNet 上进行预训练。但是,在 low-capacity 网络上是否需要预训练是不确定的。Fast-SCNN 是按照 low-capacity 设计的。在我们的实验中,我们证明小网络并不能通过预训练得到多少提升。相反,更激进的数据增强和多跑几个 epochs 也能带来不错的提升。
3. Fast-SCNN
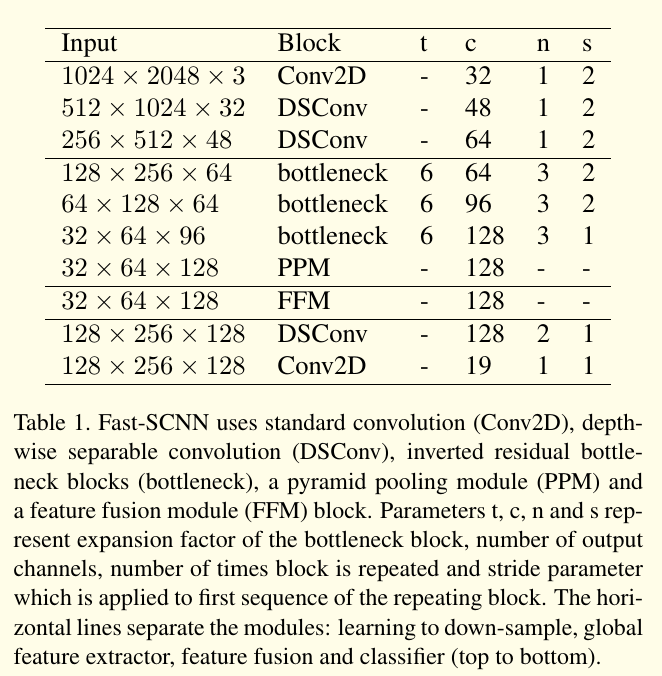
Fast SCNN 受 two-branch 结构和 encoder-decoder 网络启发。模型前面几个层提取的是低层次的特征。我们将 skip connections 重新改为一个 learning to downsample 的模块,使我们能够将上述两个框架的核心 idea 结合起来,从而构建一个快速的语义分割模型。图1 和表1就是 Fast SCNN的结构。
3.1 Motivation
当前的 state of art 实时的语义分割方法都是基于 two-branch 的网络,每一个 branch 操作在不同的分辨率上。它们从图像的低分辨率输入上学习全局信息,用浅层网络在全分辨率的输入上优化语义分割的准确率。因为图像分辨率和网络深度是影响运行速度的主要因素,two-branch 方法可以进行实时的计算。
深度神经网络的前几个层提取低层次的特征,如边缘和拐角信息。因此,我们没有像 two-branch 方法一样去使用单独的计算,我们提出了 learning to downsample 模块,它在一个较浅的网络内,在低层次和高层次的 branch 间共享特征计算。
3.2 网络结构
Fast-SCNN 使用了 learn to downsample 模块,一个粗糙的全局特征提取器,一个特征融合模块,以及一个标准分类器。所有的模块都用 depthwise separable 卷积构建(它已成为许多高效率的神经网络结构的核心构件)。

3.2.1 Learning to downsample
在 learn to downsample 模块中,我们用了3个层。这3个层确保了低层次特征能被有效地共享和使用。第一层是一个标准的卷积层(Conv2D),其它两个层则为 depthwise separable 卷积层(DSConv)。尽管 DSConv 计算上很高效,但是由于输入图像只有3个通道,我们也用了 Conv2D 层,这使得在这个阶段, DSConv 算力上的优势并没有得到体现。
Learn to downsample 中的这三个层使用的步长为2,后面跟着一个 batch normalization 层和ReLU层。卷积核和 depthwise 层的核大小为 。我们没有用 depthwise 和 pointwise 卷积之间的非线性函数。
3.2.2 全局特征提取器
全局特征提取器目的在于捕捉图像分割的全局环境信息。和常用的 two-branch 方法不同,它是操作在图像的低分辨率输入上,我们的模块则直接将 learn to downsample 模块的输出作为输入(约为原始输入的 大小),模块的详细结构如表1所述。我们使用了 MobileNet-V2 中高效的 bottleneck residual 模块(表2)。当输入和输出的大小一样时,我们在 bottleneck residual blocks 上使用 residual connection。Bottleneck block 使用了一个高效的 depthwise separable 卷积,使得参数个数和浮点数计算更少。在末端增加了一个金字塔池化模块来聚合不同区域的环境信息。
3.2.3 特征融合模块
与ICNet 和 ContextNet 类似,我们更倾向于将特征加起来使用,以确保效率。也有其它更复杂的特征融合模块可供使用,但是要牺牲掉时间效率。特征融合模块在表3中展示。

3.2.4 分类器
我们使用了两个 depthwise separable 卷积和一个 pointwise 卷积。我们发现在特征融合模块后增加几个层可以提升精度。分类器模块结构如表1所示。
Softmax 在训练中使用,因为有用到梯度下降。在前向推理时,我们可以将昂贵的 softmax 替换为 argmax,因为它们都是单调递增的。我们将这个方案称作 Fast-SCNN cls(classification)。另一方面,如果需要一个基于概率模型的标准深度卷积网络,则使用 softmax,表示为 Fast-SCNN prob(probability)。
3.3 Comparison with Prior Art
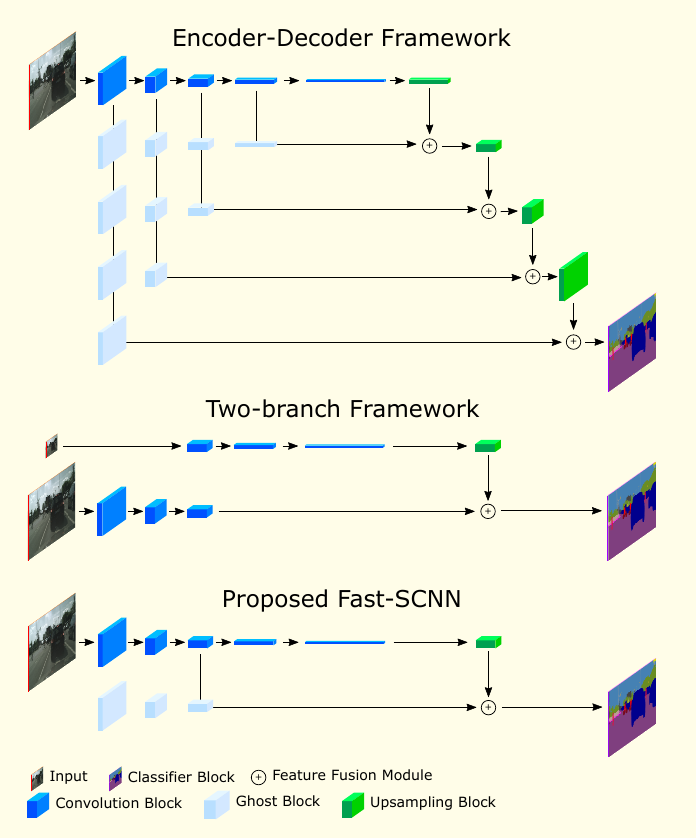
我们的模型是受 two-branch 模型启发,添加了 encoder-decoder 方法(图2)。
3.3.1 与 Two-branch 方法的关系
State of art 的方法如 BiSeNet, GUN等都使用了 two-branch 网络。我们的 learn to downsample 模块和它们的 spatial path 等价,因为它们都很浅,从全分辨率输入上学习,用在特征融合模块中(图1)。
我们的全局特征提取模块和这些方法中的较深的低分辨率 branch 等价。但是,我们的全局特征提取器将它前几个层的计算与 learn to downsample 模块进行了共享。通过共享这几个层,我们不仅将第了特征提取的计算复杂度,也将第了输入的大小,Fast-SCNN 使用 的分辨率,而不是全局特征提取阶段的 分辨率。
3.3.2 与 Encoder-Decoder 方法的关系
Fast-SCNN 可被看作 encoder-decoder 方法的特例,如 FCN 或 U-Net。但是,不像FCN中的 multiple skip connections 或者 U-Net 中的 dense skip connections,Fast-SCNN 只使用了单个 skip connections 来降低计算量和内存消耗。
和 Visualizing and Understanding Convolutional Networks 论文中一致,特征只在深度卷积网络的前几个层中共享,我们也将 skip connection 放在网络的前几个层。但是,更早的文献通常在 skip connection 之前,在每个分辨率上都应用更深的模块。
4. 实验
Pls read paper for more details.