论文笔记-PSPNet-Semantic Segmentation–Pyramid Scene Parsing Network
PSPNet
Pyramid Scene Parsing Network
文章地址:paper
项目地址:
https://github.com/hszhao/PSPNet
keras
tensorflow
部分内容转载于https://blog.csdn.net/u011974639/article/details/78985130
Abstract
Scene parsing is challenging for unrestricted open vocabulary and diverse scenes. In this paper, we exploit the capability of global context information by different-region based context aggregation through our pyramid pooling module together with the proposed pyramid scene parsing network (PSPNet). Our global prior representation is effective to produce good quality results on the scene parsing task, while PSPNet provides a superior framework for pixellevel prediction. The proposed approach achieves state-ofthe-art performance on various datasets. It came first in ImageNet scene parsing challenge 2016, PASCAL VOC 2012 benchmark and Cityscapes benchmark. A single PSPNet yields the new record of mIoU accuracy 85.4% on PASCAL VOC 2012 and accuracy 80.2% on Cityscapes.
提出金字塔池化模块,聚合不同区域的上下文信息。即多尺度融合的思想,类比于GCN、BiSeNet的large kernel size和context path。
Introduction
基于语义分割的场景解析(Scene parsing)任务,当前state-of-the-arts大多基于FCN实现,但是研究发现当前主要的基于FCN的模型缺乏全局场景信息的使用:
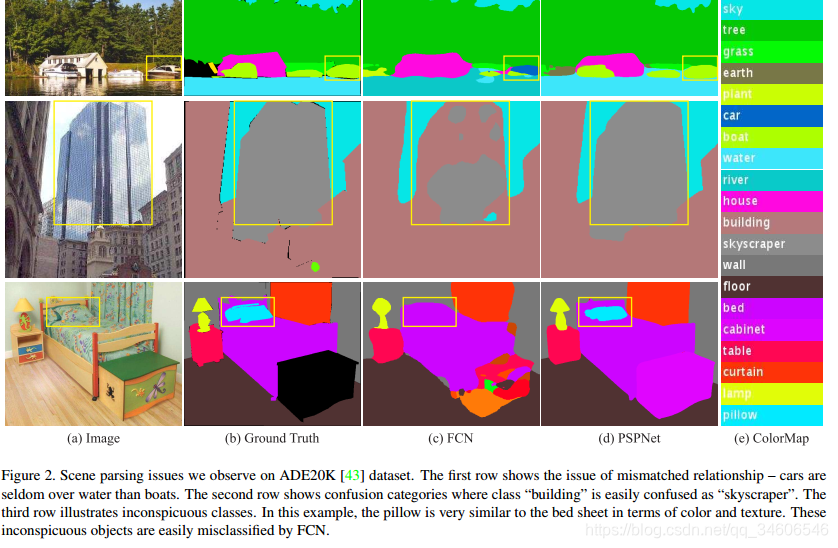 Mismatched Relationship:上下文关系匹配对理解复杂场景很重要,例如在上图第一行,在水面上的大很可能是“boat”,而不是“car”。虽然“boat和“car”很像。FCN缺乏依据上下文推断的能力。
Mismatched Relationship:上下文关系匹配对理解复杂场景很重要,例如在上图第一行,在水面上的大很可能是“boat”,而不是“car”。虽然“boat和“car”很像。FCN缺乏依据上下文推断的能力。
Confusion Categories: 许多标签之间存在关联,可以通过标签之间的关系弥补。上图第二行,把摩天大厦的一部分识别为建筑物,这应该只是其中一个,而不是二者。这可以通过类别之间的关系弥补。
Inconspicuous Classes:模型可能会忽略小的东西,而大的东西可能会超过FCN接收范围,从而导致不连续的预测。如上图第三行,枕头与被子材质一致,被识别成到一起了。为了提高不显眼东西的分割效果,应该注重小面积物体。
总结这些情况,许多问题出在FCN不能有效的处理场景之间的关系和全局信息。本论文提出了能够获取全局场景的深度网络PSPNet,能够融合合适的全局特征,将局部和全局信息融合到一起。并提出了一个适度监督损失的优化策略,在多个数据集上表现优异。
本文的主要贡献如下:
1、We propose a pyramid scene parsing network to embed difficult scenery context features in an FCN based pixel prediction framework.
提出了一个金字塔场景解析网络,能够将难解析的场景信息特征嵌入基于FCN预测框架中
2、We develop an effective optimization strategy for deep ResNet [13] based on deeply supervised loss.
在基于深度监督损失的ResNet上制定有效的优化策略
3、We build a practical system for state-of-the-art scene parsing and semantic segmentation where all crucial implementation details are included.
构建了一个实用的系统,用于场景解析和语义分割,并包含了实施细节
related work
受到深度神经网络的驱动,场景解析和语义分割获得了极大的进展。例如FCN、ENet等工作。许多深度卷积神经网络为了扩大高层feature的感受野,常用dilated convolution(空洞卷积)、coarse-to-fine structure等方法。本文基于先前的工作,选择的baseline是带dilated network的FCN。
大多数语义分割模型工作基于两个方面:
1)多尺度特征融合,高层特征具有更多的语义和全局上下文信息,底层特征包含细节信息;
2)CRF后处理优化边界
网络结构

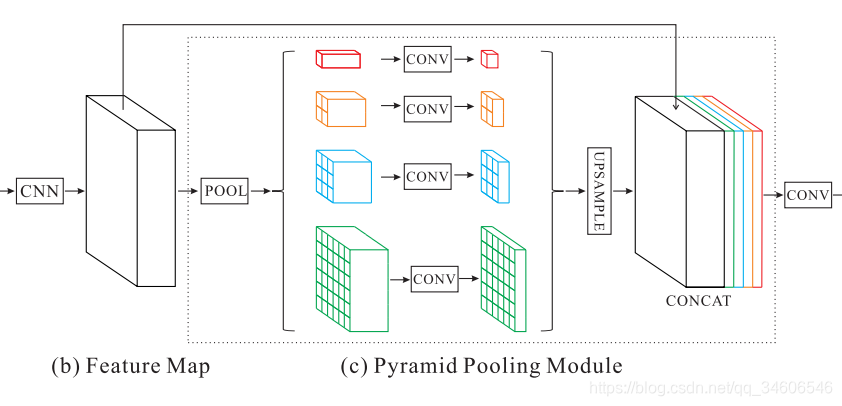 该模块融合了4种不同金字塔尺度的特征,第一行红色是最粗糙的特征–全局池化生成单个bin输出,后面三行是不同尺度的池化特征。为了保证全局特征的权重,如果金字塔共有N个级别,则在每个级别后使用1×1的卷积将对于级别通道降为原本的1/N(特征图通道数2048 x 1/4 = 512)。再通过双线性插值获得未池化前的大小,最终concat到一起。
该模块融合了4种不同金字塔尺度的特征,第一行红色是最粗糙的特征–全局池化生成单个bin输出,后面三行是不同尺度的池化特征。为了保证全局特征的权重,如果金字塔共有N个级别,则在每个级别后使用1×1的卷积将对于级别通道降为原本的1/N(特征图通道数2048 x 1/4 = 512)。再通过双线性插值获得未池化前的大小,最终concat到一起。
金字塔等级的池化核大小是可以设定的,这与送到金字塔的输入有关。论文中使用的4个等级,核大小分别为1×1,2×2,3×3,6×6
完整pipeline:
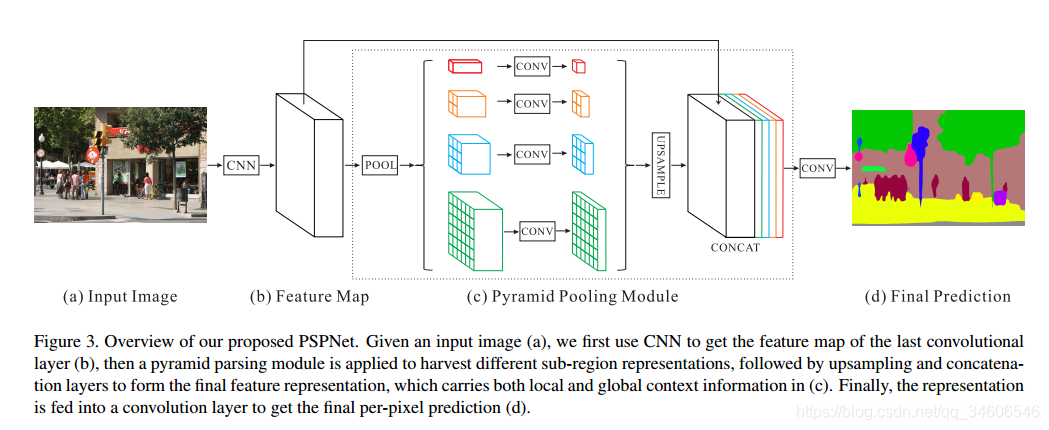 基础层经过预训练的模型(ResNet101)和空洞卷积策略提取feature map,提取后的feature map是输入的1/8大小
基础层经过预训练的模型(ResNet101)和空洞卷积策略提取feature map,提取后的feature map是输入的1/8大小
feature map经过Pyramid Pooling Module得到融合的带有整体信息的feature,在上采样与池化前的feature map相concat
最后过一个卷积层得到最终输出
基于ResNet的深度监督网络
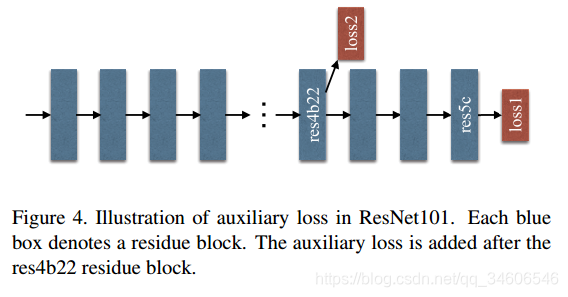 在ResNet101的基础上做了改进,除了使用后面的softmax分类做loss,额外的在第四阶段添加了一个辅助的loss,两个loss一起传播,使用不同的权重,共同优化参数。后续的实验证明这样做有利于快速收敛。
在ResNet101的基础上做了改进,除了使用后面的softmax分类做loss,额外的在第四阶段添加了一个辅助的loss,两个loss一起传播,使用不同的权重,共同优化参数。后续的实验证明这样做有利于快速收敛。
实验部分(该部分参考https://blog.csdn.net/u011974639/article/details/78985130)