2015年arXiv预印本文章
作者单位中科大,清华,港科技
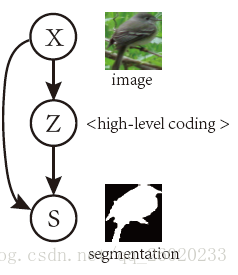
文章的主要贡献在于利用CNN将high-level prior融入了语义分割中。受人类视觉识别系统的启发,文章借鉴了三层生成结构:高层编码,中层分割,低层图像。作者提出利用CVAE(条件变分自编码器)来建立这三层结构之间的联系,从而为语义分割引入全局先验。
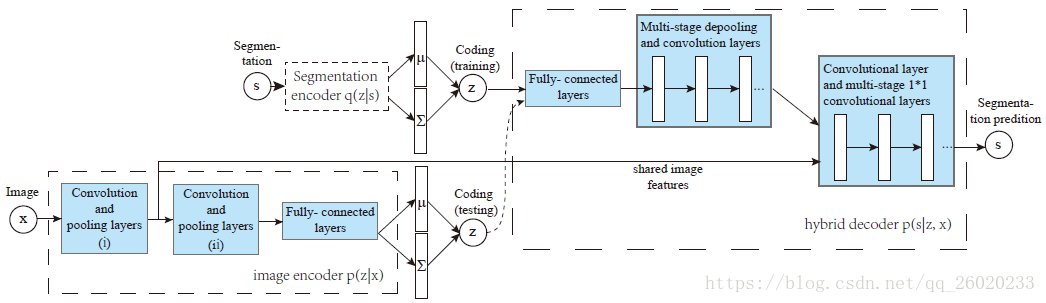
具体而言,网络的实现包含3个部分,图像编码部分(image encoder)从图像中提取高维信息,分割编码部分(segmentation encoder)从分割标签中提取高维信息(只在训练阶段用到),混合解码部分(hybrid decoder)根据输入图像与提取的高维信息输出语义分割结果。整体网络结构如下图所示,其中hybrid decoder 与 image encoder 共享前两层特征提取层。
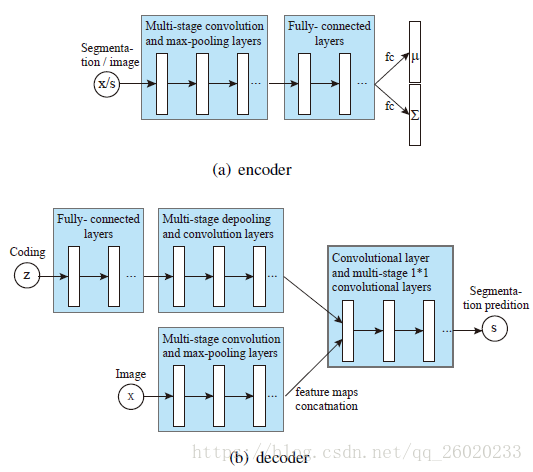
从编码器与解码器的角度来看,整个网络也可看成以下两个部分:
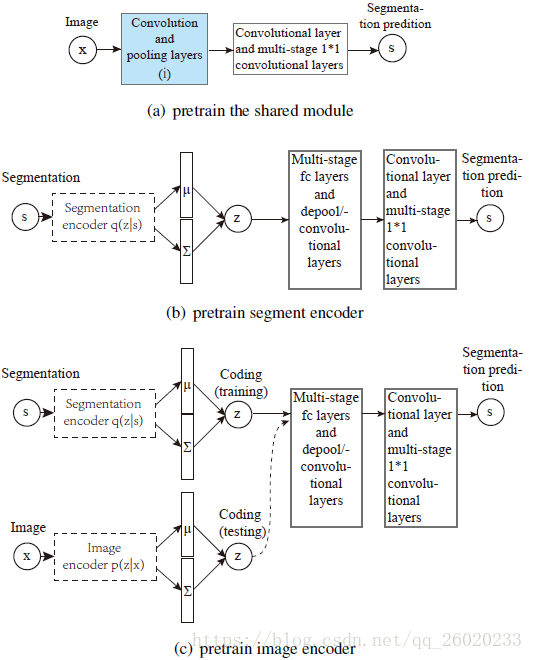
为了提高网络的训练效率,首先将各个模块分别进行预训练,之后再进行联合训练。
各模块预训练如下图所示:图(a)为对共享层(i)的预训练,采用ImageNet预训练的VGG的FCN层参数;图(b)为对分割编码部分的预训练,这是一个VAE网络,通过重建分割图的过程,一方面训练分割编码部分,另一方面也训练了对潜在变量z进行解码的混合解码部分;图©为对图像编码部分的预训练,利用图(b)已训练的VAE来对图像编码部分进行训练,以约束图像编码部分与分割图编码部分能够产生相似的编码。
在联合训练阶段,整个网络的目标函数为:
Loss=−DKL(q(z∣s)∣∣p(z∣x))+∑zlogp(s∣z,x).
推导过程如下:
令输入图像为x,潜在变量为z,分割图编码器为
q(z∣s),图像编码器为
p(z∣x),混合解码器为
p(s∣z,x),整个网络为
p(s∣x),训练的最终目标是提高分割精度,即最大化
logp(s∣x).
logp(s∣x)=z∑q(z∣s)logp(s∣x)=z∑q(z∣s)logp(z∣s,x)p(s,z∣x)=z∑q(z∣s)logp(z∣s)p(s,z∣x)=z∑q(z∣s)(logp(z∣s)p(z∣s)+logp(z∣s)p(s,z∣x))=z∑q(z∣s)(logp(s,z∣x)−logq(z∣s)+logp(z∣s)q(z∣s))≥z∑q(z∣s)(logp(s,z∣x)−logq(z∣s))=z∑q(z∣s)(logp(z∣x)+logp(s∣z,x)−logq(z∣s))=z∑q(z∣s)(−logp(z∣x)q(z∣s)+logp(s∣z,x))=−DKL(q(z∣s)∣∣p(z∣x))+z∑logp(s∣z,x)
(注:
p(z∣s) is intractable)
由上述推导,最大化
logp(s∣z,x)可转化为最大化其下界,即最大化
−DKL(q(z∣s)∣∣p(z∣x))+∑zlogp(s∣z,x).