摘要
语义分割既需要丰富的空间信息,又需要大量的感受野。然而,现代方法通常会牺牲空间分辨率来实现实时推理速度,导致性能较差。在本文中,我们用一种新的双边分割网络BiSeNet来解决这个问题。首先设计了一个小步幅的空间路径,以保留空间信息并生成高分辨率的特征。同时,采用快速下采样策略的上下文路径获得足够的感受野。在这两条路径上,我们引入了一个新的特征融合模块来有效的组合特征。
引言
实时语义分割算法主要的三种方法:
1.尝试限制输入大小以通过裁剪或调整大小来降低计算复杂性。虽然该方法简单有效,但空间细节的损失损坏了调整围绕边界的预测
2.修剪网络的通道促进推理速度,但是削弱了空间能力
3.ENet删除模型的最后阶段,在最后阶段放弃了下采样操作,所以模型的感受野不足以覆盖大物体,导致辨别能力差。
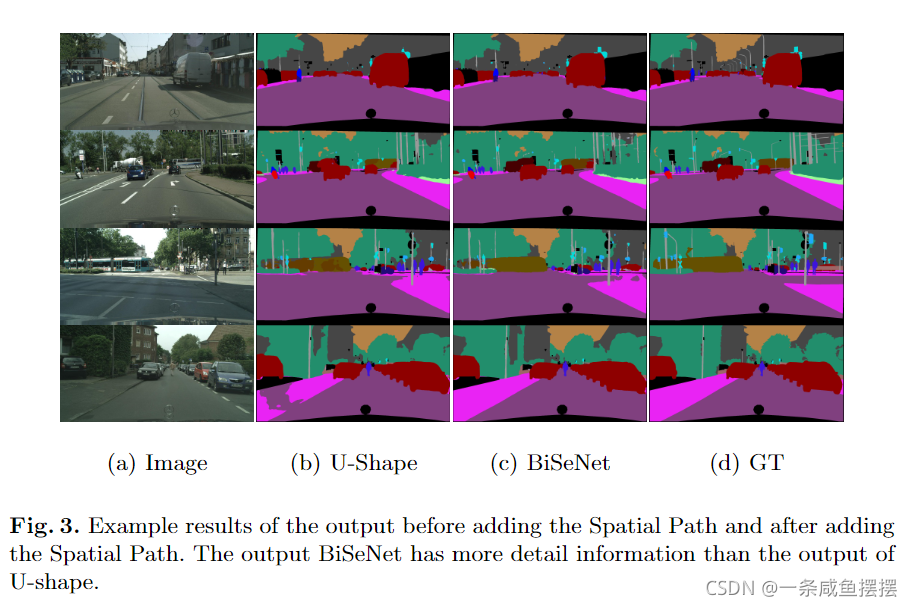
为了弥补上述空间细节的损失,开始广泛使用U型结构。通过融合主干网络的浅层特征,U型结构逐渐提高了空间分辨率,并填补了一些细节的缺失。然而,这种方法有两个缺点。1.完整的U型结构会增加高分辨率特征图的计算量,降低模型的速度.2.在剪枝或裁剪的过程中丢失大部分的空间信息,无法通过图1(b)的浅层特征恢复。换句话说,把u型技术看成是一种缓解,而不是一种根本的解决方案更好。
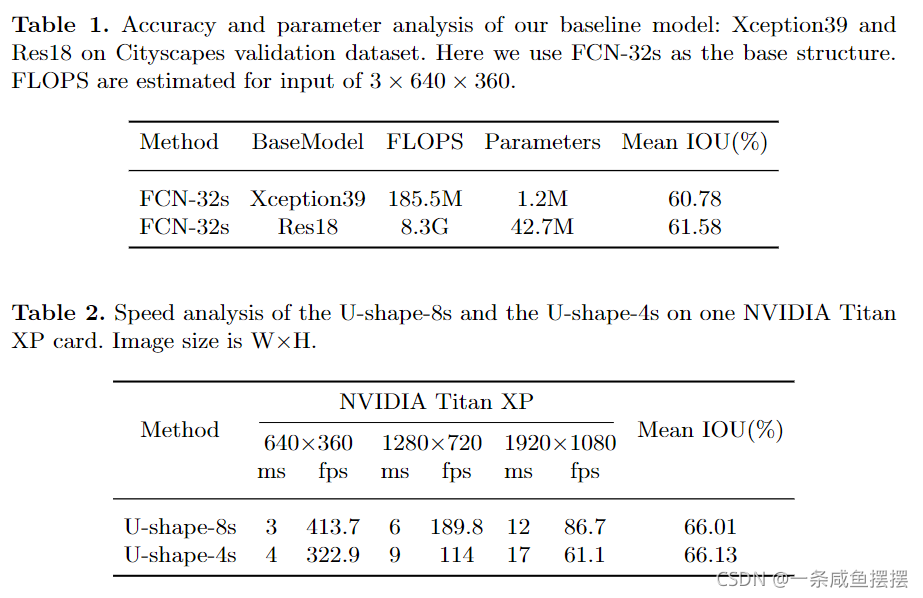
基于上述结果,我们提出了双边分割网络BiSeNet,其中包括两个部分:空间路径SP和上下文路径CP。顾名思义,这两个组成部分分别面对空间信息的丢失和感受野的收缩。对于Spatial Path,我们只叠加三个卷积层,得到1/8 feature map,它保留了丰富的空间细节。对于Context Path,我们在Xception的尾部添加了一个全局平均池层,其中感受野是骨干网络的最大值。图1©显示了这两个组件的结构。
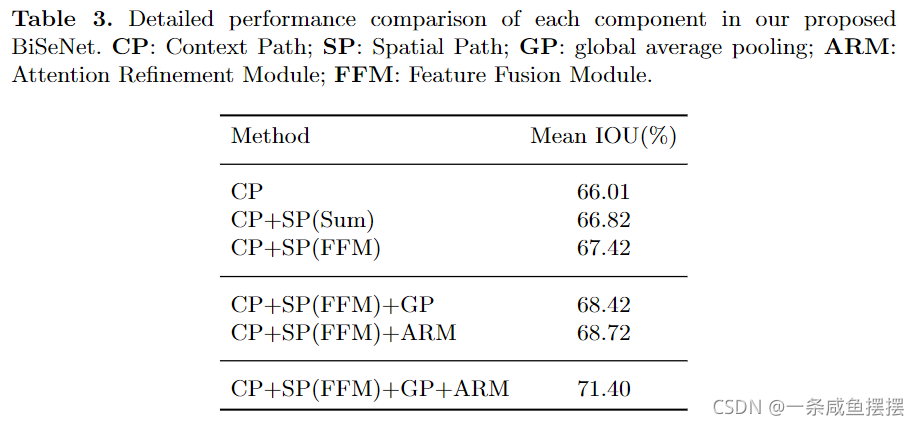
为了在不损失速度的前提下获得更好的精度,我们还研究了两种路径的融合和最终预测的精细化,并分别提出了特征融合模块(Feature fusion Module, FFM)和注意力优化模块(Attention refinement Module, ARM)。下面的实验表明,这两个额外的组件可以进一步提高Cityscapes, CamVid和COCO-Stuff的总体语义分割精度。
主要贡献如下:
1.我们提出了一种新的方法,将空间信息保存和感受野提供功能解耦为两条路径。具体地说,我们提出了一个双边分割网络(BiSeNet)与空间路径(SP)和上下文路径(CP)。
2.我们设计了特征融合模块(FFM)和注意力优化模块(ARM)两个具体模块,以在可接受的成本下进一步提高精度。
3.我们在cityscapes、CamVid和COCO-Stuff的基准测试中取得了令人印象深刻的结果。更具体地说,我们获得了68.4%的结果在城市景观测试数据集以105 FPS的速度。
双边分割网络
在本节中,我们首先用空间路径和上下文路径详细说明我们提出的双边分割网络BiSeNet。并对这两种路径的有效性进行了相应的阐述。最后,我们演示如何结合这两条路径的特性与特征融合模型和我们的双边网络。
空间路径
在语义分割任务中,已有的一些方法试图通过扩张卷积来保持输入图像的分辨率以编码足够的空间细腻些,而一些方法试图通过金字塔池化模块、空洞空间金字塔池化或“大的卷积核”来捕获足够的感受野。这些方法表明空间信息和感受野是获得高准确率的关键。然而,很难同时满足这两种需求。特别是在实时语义分割的情况下,现有的现代方法利用小的输入图像或轻量级的基础模型来加速。输入图像的尺寸较小,丢失了原始图像的大部分空间信息,而轻量化模型通过通道剪枝破坏了空间信息。
基于此,我们提出了一种空间路径,以保持原始输入图像的空间大小,并编码丰富的空间信息。空间路径包含三层,每一层包含一个s=2的卷积,BN、ReLu。一昵称,该路径提取的输出特征映射为原始图像的1/8.由于特征图的空间尺寸大,它编码了丰富的空间信息,图2(a)给出了结构的细节。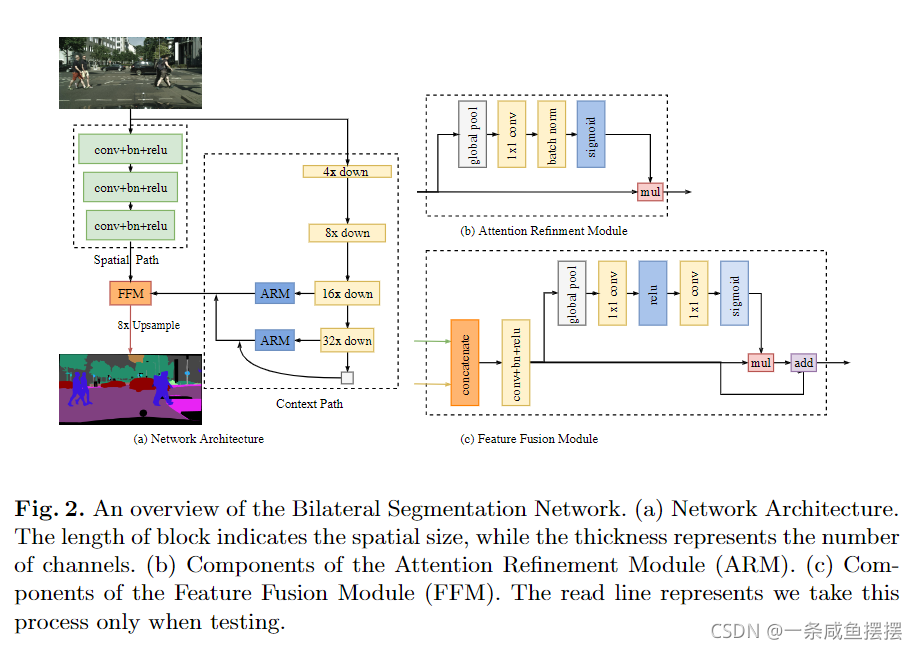
上下文路径
当空间路径编码丰富的空间信息时,上下文路径被设计来提供足够的感受野。在语义分割任务中,感受野对语义分割的表现有重要的影响。为了扩大感受野,一些方法利用了金字塔池化模块、ASPP或“大的卷积核”。然而,这些操作需要大量的计算核内存消耗,导致速度较慢。
考虑到大的感受野和高效率的计算,我们提出了上下文路径。CP利用轻量级模型和全局平均池化提供大的感受野。在这项工作中,轻量级模型,如Xception,可以快速的向下采样特征映射,以获得大的感受野,编码高级语义上下文信息。然后我们在轻量级模型的尾部添加一个全局平均池化,该池化可以提供具有全局上下文信息的最大感受野。最后,结合全局池化的上采用输出特征和轻量级模型的特征。在轻量化模型中,我们采用U型结构,融合了后两个阶段的特点,是一种不完整的U型结构。
注意力优化模块
在CP中,我们提出了一个具体的ARM来优化每个阶段的特征。如图2(b)所示。ARM采用全局平均池化来捕获全局上下文你信息,计算注意力向量来指导特征学习。这种设计可以优化上下文路径中每个阶段的输出特性。它不需要任何上采样操作就能轻松集成全局上下文信息。因此,计算成本可以忽略不计。
网络结构
利用空间路径和上下文路径,我们提出了实时语义分割网路BiSeNet,如图2(a)所示。
我们使用预训练的Xception模型作为上下文路径的骨干网络,并使用带有stride的三个卷积层作为空间路径,然后我们融合着两条路径的输出特征来做出最终的预测。它可以同时实现实时性和高精度。首先,我们着重于实际计算方面。虽然空间路径具有较大的空间尺寸,但它只有三个卷积层。因此,它不是计算密集型的。对于上下文路径,我们使用一个轻量型模型来快速下采样。此外,这两条路径并行计算,大大提高了效率。其次,我们讨论了该网络的准确性方面。在本文中,空间路径编码丰富的空间信息,而上下文路径提供大的感受野。它们相互补充,以获得更高的性能。
特征融合模块
两个路径的特征在特征表示级别上不同,因此,我们不能简单地总结这些功能。空间路径捕获的空间信息编码大多数丰富的详细信息。此外,上下文路径的输出特征主要是编码上下文信息。换句话说,空间路径的输出特征是低级的,而上下文路径的输出特征是高级的。因此,我们提出了一个特定的特征融合模块来融合这些特征。
考虑到特征的不同层次,我们首先将空间路径和上下文路径的输出特征连接起来。然后利用BN层来平衡特征的尺度。接下来,我们将连接的特征集合到一个特征向量中,并九三一个权值向量,如SENet。该权值向量可以对特征进行重新加权,即特征的选择和组合。图2( c )显示了该设计的细节。
损失函数
在本文中,我们还利用辅助损失函数来监督我们所提出的方法的训练。我们使用的主损失函数来监督整个双边网络的输出。此外,我们还增加了两个特定的辅助损失函数来监督CP的输出,如深度监督。损失函数均为Softmax loss,如式1所示。此外,我们使用参数a来平衡主损失和辅助损失的权重,如式2所示。我们的论文中的a等于1。联合损失使得优化器更容易对模型进行优化。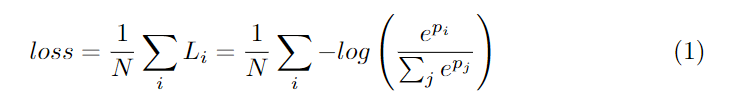
其中p为网络的输出预测
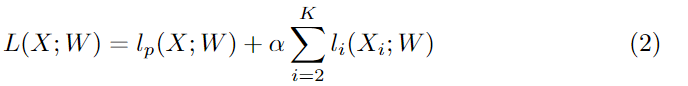
其中lp是级联输出的主损失。Xi是exception模型的第i阶段的输出特征。li为第i阶段的辅助损失,本文中K = 3。L是联合损失函数。这里,我们只在训练阶段使用辅助损失。
实验结果
实现细节
网络:我们使用三个卷积作为空间路径和Xception39模型作为上下文路径。然后我们使用Feature Fusion Module将这两种路径的特征结合起来预测最终结果。空间路径输出分辨率和最终预测分辨率为原始图像的1/8。
训练细节:
数据扩增:在训练过程中,我们对输入图像采用均值减法、随机水平翻转法和随机尺度法来增强数据集。刻度包含{0.75,1.0,1.5,1.75,2.0}。最后,我们将图像随机裁剪成固定大小进行训练。
相关实验