参考资料:
《Python数据分析基础》,作者[美]Clinton W. Brownley,译者陈光欣,中国工信出版集团,人民邮电出版社
CSV文件简述
CSV(comma-separated value,逗号分隔值)文件格式是一种非常简单的数据存储与分享方式。CSV文件将数据表格存储为纯文本,表格(或电子表格)中的每个单元格都是一个数值或字符串。与Excel文件相比,CSV文件的一个主要优点是有很多程序可以存储、转换和处理纯文本文件;相比之下,能够处理Excel文件的程序却不多。
当我们使用CSV文件时,确实会失去某些Excel功能:在Excel电子表格中,每个单元格都有一个定义好的“类型”,CSV文件中的单元格则只是原始数据。使用CSV文件的另一个问题是它只能保存数据而不能保存公式。
CSV文件初体验
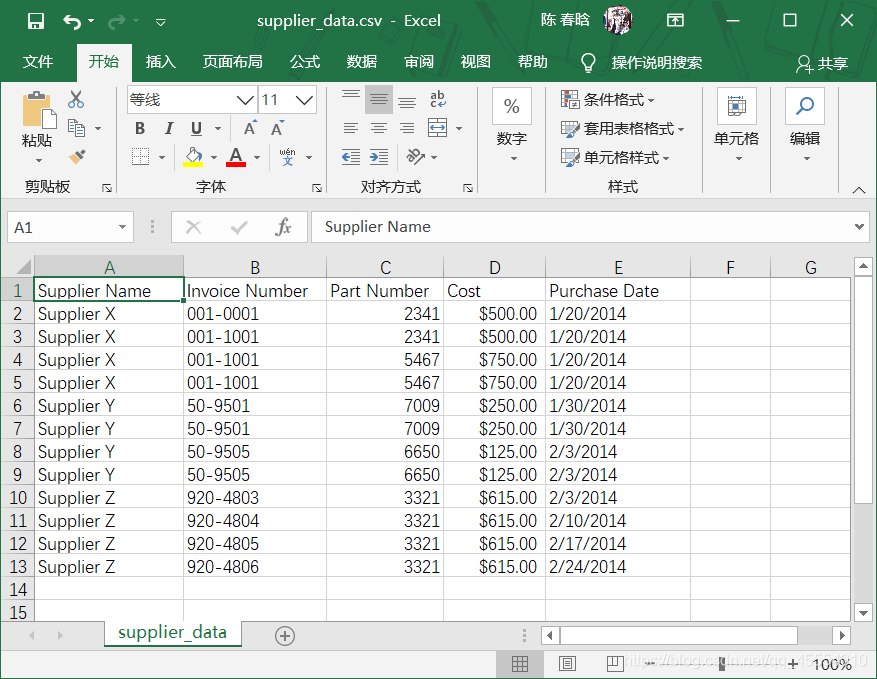
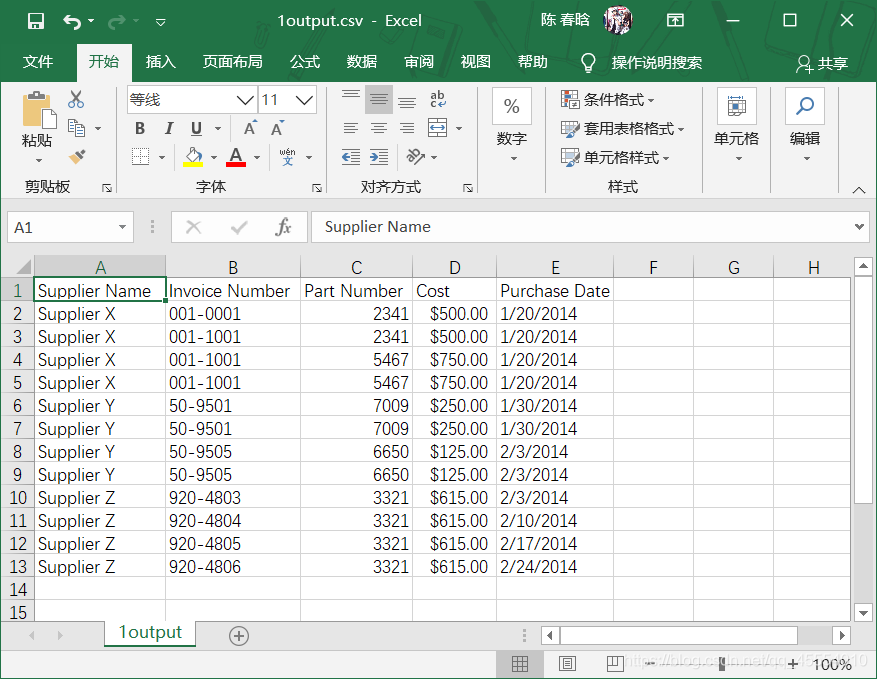
我们打开一个电子表格,向其中加入数据,如下图所示。
 把文件保存在合适的位置。我们用记事本来打开这个文件,如下图所示。
把文件保存在合适的位置。我们用记事本来打开这个文件,如下图所示。
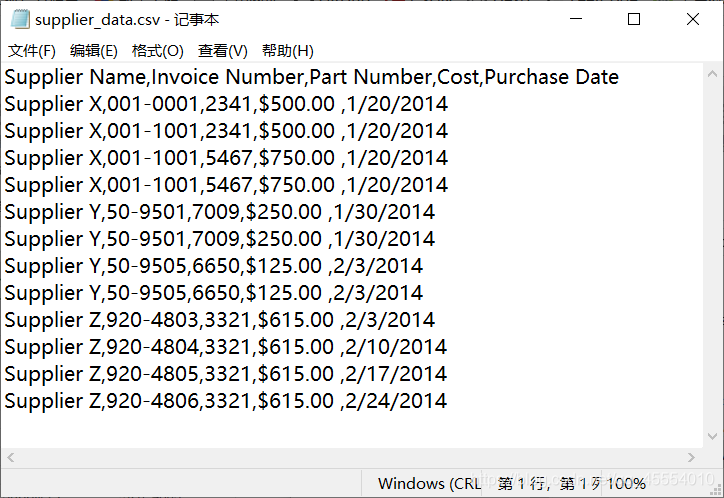 可以看到,supplier_data.csv确实是纯文本文件。
可以看到,supplier_data.csv确实是纯文本文件。
用Python读写CSV文件
1.基础Python,不使用csv模块
我们新建一个Python脚本,命名为1csv_read_with_simple_parsing_and_write.py。输入以下代码:
#!/usr/bin/env python3
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
with open(input_file, 'r', newline='') as filereader:
with open(output_file, 'w', newline='') as filewriter:
header = filereader.readline()
header = header.strip()
header_list = header.split(',')
print(header_list)
filewriter.write(','.join(map(str, header_list)) + '\n')
for row in filereader:
row = row.strip()
row_list = row.split(',')
print(row_list)
filewriter.write(','.join(map(str, row_list)) + '\n')
下面我们来解释一下上面的代码。
#!/usr/bin/env python3
这一行称为shebang行。在Python脚本中,我们应该一直把它作为第一行。以#开头的行为单行注释,在Windows系统中,计算机不读取也不执行这一行代码。但是,安装了Unix系统的计算机使用这一行来找到执行文件中代码的Python版本。加入这一行可以使脚本在不同操作系统的计算机之间具有可移植性。
input_file = sys.argv[1]
output_file = sys.argv[2]
这两行代码使用sys模块的argv参数,它是一个传递给Python脚本的命令行参数列表,也就是当你运行脚本时在命令行输入的内容。在argv这个特殊的列表中,第一个元素argv[0]用做脚本名称,argv[1]则用作CSV输入文件的路径和文件名,argv[2]用作CSV输出文件的路径和文件名。在上面的代码中,argv[1]和argv[2]被分别赋值给变量input_file和output_file。
with open(input_file, 'r', newline='') as filereader:
with open(output_file, 'w', newline='') as filewriter:
这里的with语句可以在语句结束时自动关闭文件对象。
header = filereader.readline()
header = header.strip()
header_list = header.split(',')
这里使用了文件对象的readline方法读取输入文件中的第一行数据。第一行是标题行,读入后将其作为字符串赋给变量header。strip()去掉了header字符串两端的空格、制表符和换行符。接下来使用split(',')将字符串用逗号拆分成列表并赋给变量header_list,列表中的每个值都是一个列标题。
filewriter.write(','.join(map(str, header_list)) + '\n')
这行代码使用filewriter对象的write()方法将header_list中的每个值写入输出文件。map()函数将str()函数应用于header_list中的每个元素,确保每个元素都是字符串。join()函数在header_list中的每个值之间插入一个逗号,将这个列表转换为一个字符串。在此之后,在这个字符串最后添加一个换行符\n。filewriter对象将这个字符串写入输出文件,作为输出文件的第一行。
for row in filereader:
row = row.strip()
row_list = row.split(',')
print(row_list)
filewriter.write(','.join(map(str, row_list)) + '\n')
这里创建了一个for循环,在输入文件剩余的各行中迭代。strip()除去每行字符串两端的空格、换行符和制表符。split(',')用逗号将字符串拆分成一个列表并赋给变量row_list,列表中的每个值都是这行中某一列的值。最后,将这些值打印到屏幕上并写入输出文件。
我们在命令行窗口运行这个脚本,如下图所示。
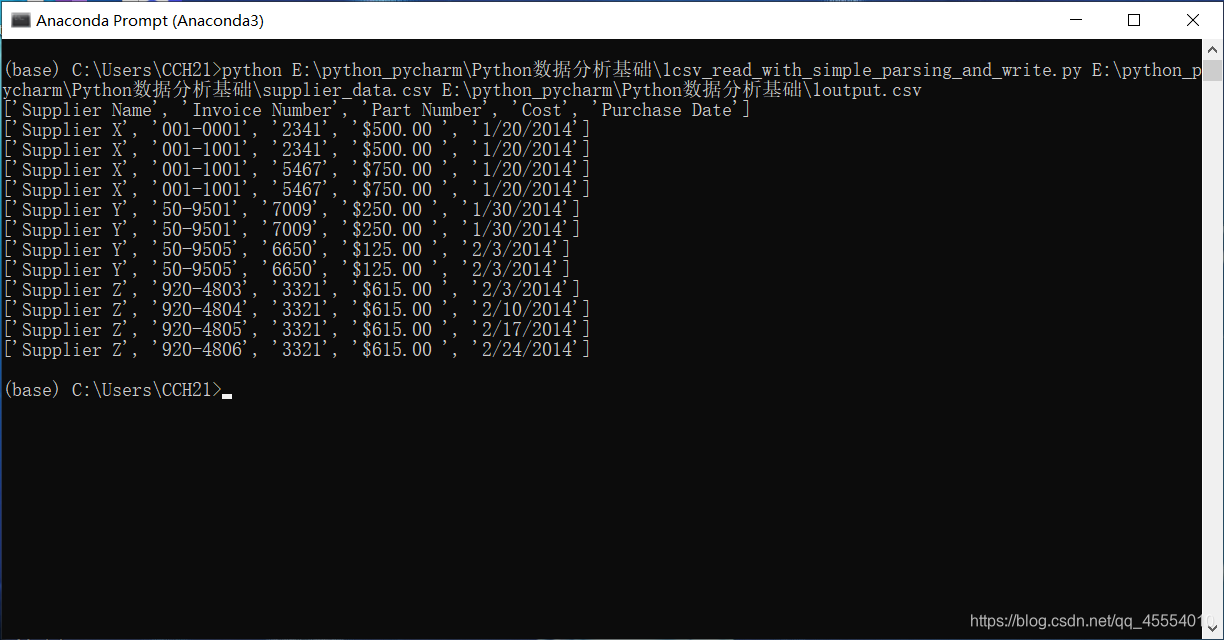 输入文件的所有行都被打印到了屏幕上,也被写入了输出文件。
输入文件的所有行都被打印到了屏幕上,也被写入了输出文件。

2.使用pandas模块
使用pandas模块处理CSV文件的代码如下所示:
#!/usr/bin/env python3
import sys
import pandas as pd
input_file = sys.argv[1]
output_file = sys.argv[2]
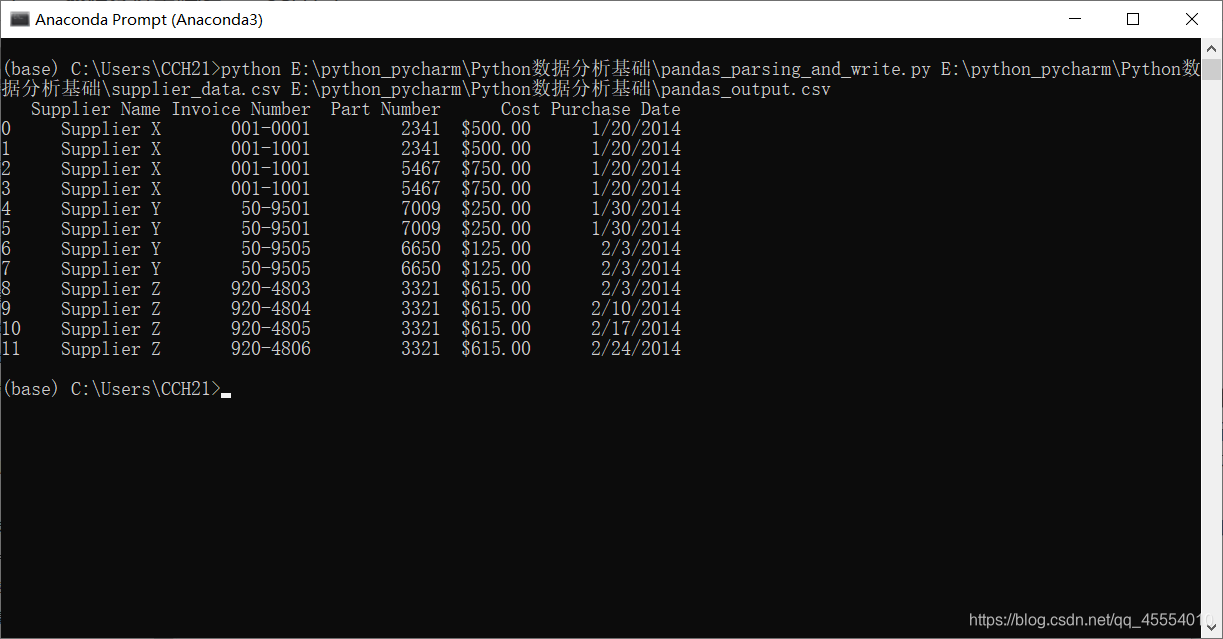
data_frame = pd.read_csv(input_file)
print(data_frame)
data_frame.to_csv(output_file, index=False)
这里我们创建了一个变量data_frame,这种数据方式叫做数据框。数据框中保留了“表格”这种组织方式,不需要使用列表套列表的方式来分析数据。数据框包含在pandas中,如果我们没有在脚本中导入pandas模块,就不能使用数据框。
在学习阶段,将这个变量命名为data_frame是可以的,但是以后,我们应该使用更有描述性的变量名。
我们在命令行窗口运行这个脚本,如下图所示。