有些时候,我们也并不需要文件中所有的列。有两种方法可以在CSV文件中选取特定的列:
1.使用列索引值;
2.使用列标题。
使用列索引值
1.基础Python
举个例子,在之前的CSV文件中,我们只想保留供应商姓名和成本这两列,使用Python编辑代码如下:
#!/usr/bin/env python3
import csv
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
my_columns = [0, 3]
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'w', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
for row_list in filereader:
row_list_output = []
for index_value in my_columns:
row_list_output.append(row_list[index_value])
filewriter.writerow(row_list_output)
我们来解释一下上面的代码。
my_columns = [0, 3]
这行代码创建了一个列表变量my_columns,其中包含了想要保留的两列的索引值,分别对应供应商姓名和成本两列。
for row_list in filereader:
row_list_output = []
for index_value in my_columns:
row_list_output.append(row_list[index_value])
filewriter.writerow(row_list_output)
在这个for循环中,首先创建了一个空列表变量row_list_output,保存每行中想要保留的值。在内层的for循环语句中,在my_columns中的各个索引值之间进行迭代,通过append()函数使用每行中my_columns索引位置的值为row_list_output填充元素。这几行代码生成了一个列表,其中包含了每行中要写入输出文件的值。filewriter的writerow()方法需要一个字符串序列或数值序列,而列表row_list_out正是一个字符串序列。
第一次循环时,index_value等于0,append()函数将row[0]加入row_list_output。此后,代码回到for index_value ...行,此时index_value等于3,append()函数将row[3]加入row_list_output。这时,内层for循环结束,代码前进到最后一行,writerow()将row_list_output中的列表值写入输出文件。然后,代码回到外层for循环,开始处理输入文件中的下一行。
我们在命令行窗口中运行这个脚本,并打开输出文件查看结果。
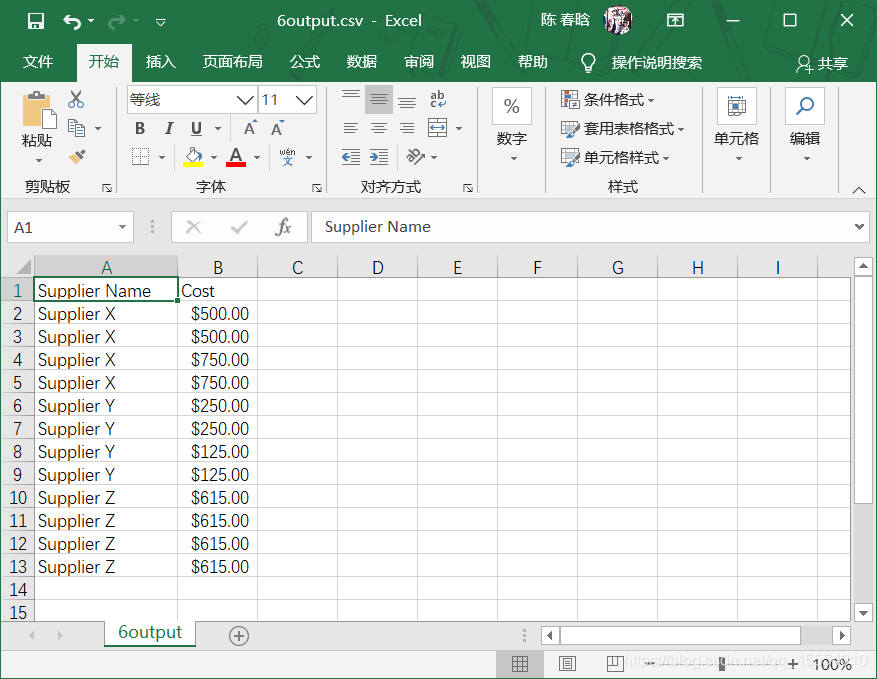
2.pandas
使用pandas模块的代码如下:
#!/usr/bin/env python3
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_csv(input_file)
data_frame_column_by_index = data_frame.iloc[:, [0, 3]]
data_frame_column_by_index.to_csv(output_file, index=False)
在上述代码中,iloc函数根据索引位置选取列。
此处省略输出结果。
使用列标题
当想保留的列的标题非常容易识别,或者在处理多个输入文件时,各个输入文件中列的位置会发生改变,但标题不变的时候,使用列标题来选取特定的列的方法非常有效。
1.基础Python
举个例子,在前面的CSV文件中,我们只想保留发票号码和购买日期两列,代码如下:
#!/usr/bin/env python3
import csv
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
my_columns = ['Invoice Number', 'Purchase Date']
my_columns_index = []
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'w', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
header = next(filereader, None)
for index_value in range(len(header)):
if header[index_value] in my_columns:
my_columns_index.append(index_value)
filewriter.writerow(my_columns)
for row_list in filereader:
row_list_output = []
for index_value in my_columns_index:
row_list_output.append(row_list[index_value])
filewriter.writerow(row_list_output)
我们来解释一下上面的代码。
my_columns = ['Invoice Number', 'Purchase Date']
my_columns_index = []
这里创建了一个列表变量my_columns,其中包含的两个字符串即要保留的两列的名字。下面创建的空列表变量my_columns_index要使用两个保留列的索引值来填充。
header = next(filereader, None)
这行代码使用next()函数从输入文件中读取第一行,并保存在列表变量header中。
for index_value in range(len(header)):
if header[index_value] in my_columns:
my_columns_index.append(index_value)
filewriter.writerow(my_columns)
for row_list in filereader:
row_list_output = []
for index_value in my_columns_index:
row_list_output.append(row_list[index_value])
filewriter.writerow(row_list_output)
这几行代码与上一种方法的代码思路类似,在此不再赘述。
在命令行窗口中运行这个脚本,并打开输出文件查看结果。
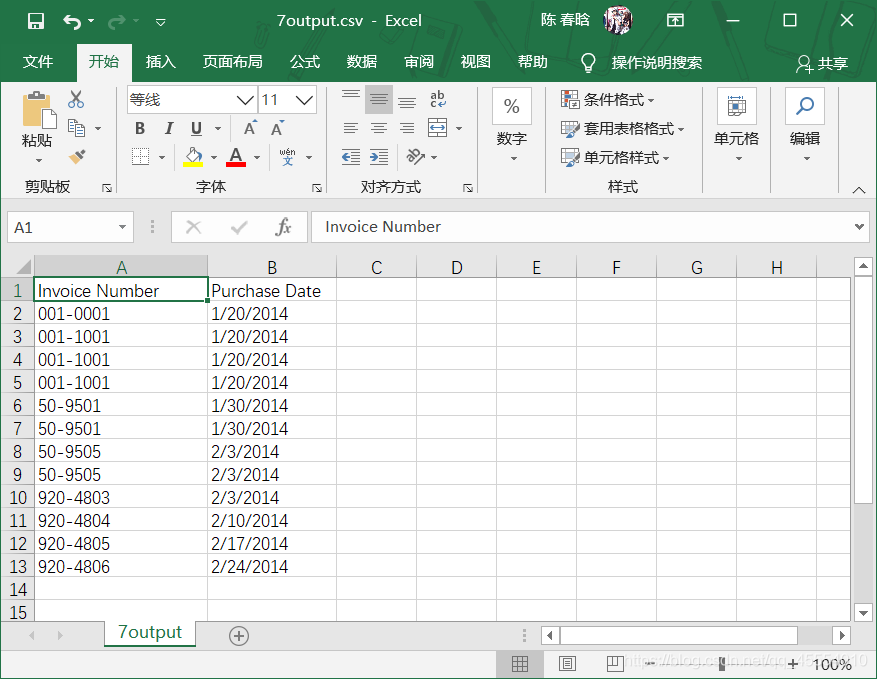
2.pandas
使用pandas模块的代码如下:
#!/usr/bin/env python3
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_csv(input_file)
data_frame_column_by_name = data_frame.loc[:, ['Invoice Number', 'Purchase Date']]
data_frame_column_by_name.to_csv(output_file, index=False)
在上面的代码中,使用loc函数来选取列。
此处省略输出结果。
