Python数据分析:csv文件数据的提取案例
文件网址:https://www.kaggle.com/osmi/mental-health-in-tech-survey
目标:提取csv文件中的国家和所对应的性别统计数据
import csv
# 数据集路径
path = 'survey.csv'
def run_main():
# 男性取值列表
male_set = {'male', 'm'}
# 女性取值列表
female_set = {'female', 'f'}
# 创建存储结果的空字典,键为国家,值为女性和男性数据的列表
result_dict = {}
# 加载数据
with open(path, 'r', newline='') as csvfile:
rows = csv.reader(csvfile)
for i, row in enumerate(rows):
# 跳过标题
if i == 0:
continue
# 每50行打印
if i % 50 == 0:
print('正在处理第{}行数据...'.format(i))
# 取出原始csv文件中的性别数据
gender_val = row[2]
country_val = row[3]
# 去除空格
gender_val = gender_val.replace(' ', '')
# 转换为小写
gender_val = gender_val.lower()
# 判断国家是否已经存在,若不存在则初始化
if country_val not in result_dict:
result_dict[country_val] = [0, 0]
# 判断性别
if gender_val in female_set:
result_dict[country_val][0] += 1
elif gender_val in male_set:
result_dict[country_val][1] += 1
else:
pass
# 将提取数据写入文件
with open('country_gender.csv', 'w', newline='', encoding='utf-16') as csvfile:
csvwriter = csv.writer(csvfile, delimiter=',')
# 写入表头
csvwriter.writerow(['国家', '男性', '女性'])
# 写入统计结果,k为国家,v为性别数据
for k, v in list(result_dict.items()):
csvwriter.writerow([k, v[0], v[1]])
if __name__ == '__main__':
run_main()
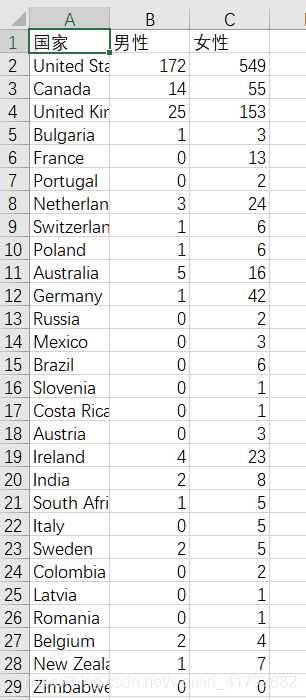
运行得到的country_gender.csv文件在Excel中的打开显示:
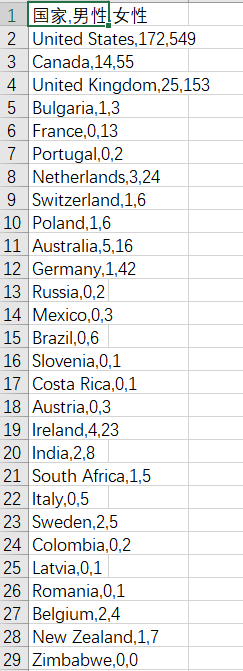
这里发现在Excel中的显示并不是按列显示,解决方法是先用记事本打开csv文件,然后另存为选择UTF-8的编码方式,保存后再用Excel打开csv文件即可正确显示如下: