参考资料:
《Python数据分析基础》,作者[美]Clinton W. Brownley,译者陈光欣,中国工信出版集团,人民邮电出版社
SQL(Structured Query Language),表示结构化查询语言,是一组应用广泛的与数据库交互的命令。要学习如何使用Python同数据库交互,首先我们要有一个数据库,并且数据库中要有一张充满数据的表。有两种资源可供我们选择:一是Python的内置模块sqlite3,它可以创建内存数据库,我们不用下载安装专门的数据库软件;二是MySQL、PostgreSQL或Oracle这样的常用数据库系统。
使用sqlite3模块创建数据库
首先,我们使用sqlite3模块直接在Python代码中创建一个内存数据库以及充满了数据的表。
#!/usr/bin/env python3
import sqlite3
# 创建SQLite3内存数据库
# 创建带有4个属性的sales表
con = sqlite3.connect(':memory:')
query = """CREATE TABLE sales
(customer VARCHAR(20),
product VARCHAR(40),
amount FLOAT,
date DATE);"""
con.execute(query)
con.commit()
# 在表中插入几行数据
data = [('Richard Lucas', 'Notepad', 2.50, '2014-01-02'),
('Jenny Kim', 'Binder', 4.15, '2014-01-15'),
('Svetlana Crow', 'Printer', 155.75, '2014-02-03'),
('Stephen Randolph', 'Computer', 679.40, '2014-02-20')]
statement = "INSERT INTO sales VALUES(?, ?, ?, ?)"
con.executemany(statement, data)
con.commit()
# 查询sales表
cursor = con.execute("SELECT * FROM sales")
rows = cursor.fetchall()
# 计算查询结果中行的数量
row_counter = 0
for row in rows:
print(row)
row_counter += 1
print('Number of rows: %d' % (row_counter))
第3行代码导入了sqlite3模块。为了使用这个模块,首先必须创建一个代表数据库的连接对象。第7行代码创建了连接对象con来代表数据库。专用名称':memory:'在内存中创建了一个数据库。如果想要数据库持久化,就需要提供另外的字符串。
第8-12行代码使用三重双引号创建了一个多行字符串,并将这个字符串赋给变量query。这个字符串是一个SQL命令,可以在数据库中创建一个名为sales的表。sales表有4个属性:customer, product, amount和date。customer和product都是变长字符型字段,最大字符数分别为20和40。amount是一个浮点数型字段。date是一个日期型字段。
第13行代码使用连接对象的execute()方法执行包含在变量query中的SQL命令,在内存数据库中创建sales表。第14行代码使用连接对象的commit()方法将修改提交(也就是保存)到数据库。对数据库做出修改时必须使用commit()方法保存修改。
第21行代码与第8行代码类似,创建了一个字符串并赋给变量statement。这行代码中的字符串是另一个SQL命令,INSERT语句可以将data中的数据行插入sales表。?在这里用作占位符,表示想在SQL命令中使用的值。然后,在连接对象的execute()或executemany()方法中,需要提供一个包含4个值的元组,元组中的值会按位置替换到SQL命令中。
第26行代码使用连接对象的execute()方法运行一条SQL命令,并将命令结果赋给一个光标变量cursor。第27行代码执行了fetchall()方法,返回第26行代码中的SQL命令的数据行的列表。每行数据都是一个元组,所以rows是一个元组列表。在这种情况下,sales表中包含4行数据,SQL命令从sales表中选择所有的行,所以rows是一个含有4个元组的列表。
运行结果如下:
('Richard Lucas', 'Notepad', 2.5, '2014-01-02')
('Jenny Kim', 'Binder', 4.15, '2014-01-15')
('Svetlana Crow', 'Printer', 155.75, '2014-02-03')
('Stephen Randolph', 'Computer', 679.4, '2014-02-20')
Number of rows: 4
向表中插入新记录
下面的这个脚本将创建一个数据表,向表中插入CSV文件中的数据,然后展示表中的数据。这里使用的CSV文件是前面用到过的supplier_data.csv文件。
#!/usr/bin/env python3
import csv
import sqlite3
import sys
# CSV输入文件的路径和文件名
input_file = sys.argv[1]
# 创建SQLite3内存数据库
# 创建带有5个属性的Suppliers表
con = sqlite3.connect('E:\\python_pycharm\\Python数据分析基础\\第4章 数据库\\Suppliers.db')
c = con.cursor()
create_table = """CREATE TABLE IF NOT EXISTS Suppliers
(Supplier_Name VARCHAR(20),
Invoice_Number VARCHAR(20),
Part_Number VARCHAR(20),
Cost FLOAT,
Purchase_Date DATE);"""
c.execute(create_table)
con.commit()
# 读取CSV文件
# 向Suppliers表中插入数据
file_reader = csv.reader(open(input_file, 'r'), delimiter=',')
header = next(file_reader, None)
for row in file_reader:
data = []
for column_index in range(len(header)):
data.append(row[column_index])
print(data)
c.execute("INSERT INTO Suppliers VALUES (?, ?, ?, ?, ?);", data)
con.commit()
print('')
# 查询Suppliers表
output = c.execute("SELECT * FROM Suppliers")
rows = output.fetchall()
for row in rows:
output = []
for column_index in range(len(row)):
output.append(str(row[column_index]))
print(output)
第12行代码为本地数据库Suppliers.db创建连接。这是一个持久化数据库,即使重启计算机,这个数据库也不会被删除。
第25-33行代码从CSV输入文件中读取要加载到数据库中的数据,并对输入文件中的每行数据执行一条SQL语句,将数据插入到数据库的表中。第32行代码将每行数据加载到数据表中。第33行代码使用commit()方法将修改提交到数据库。
第37-43行代码从数据表Suppliers中选择所有数据,并将输出打印到命令行窗口。第37-38行代码执行一条SQL语句,从Suppliers表中选择所有数据,并将output中的所有行读入变量rows。
在命令行窗口中运行这个脚本,得到输出结果如下:
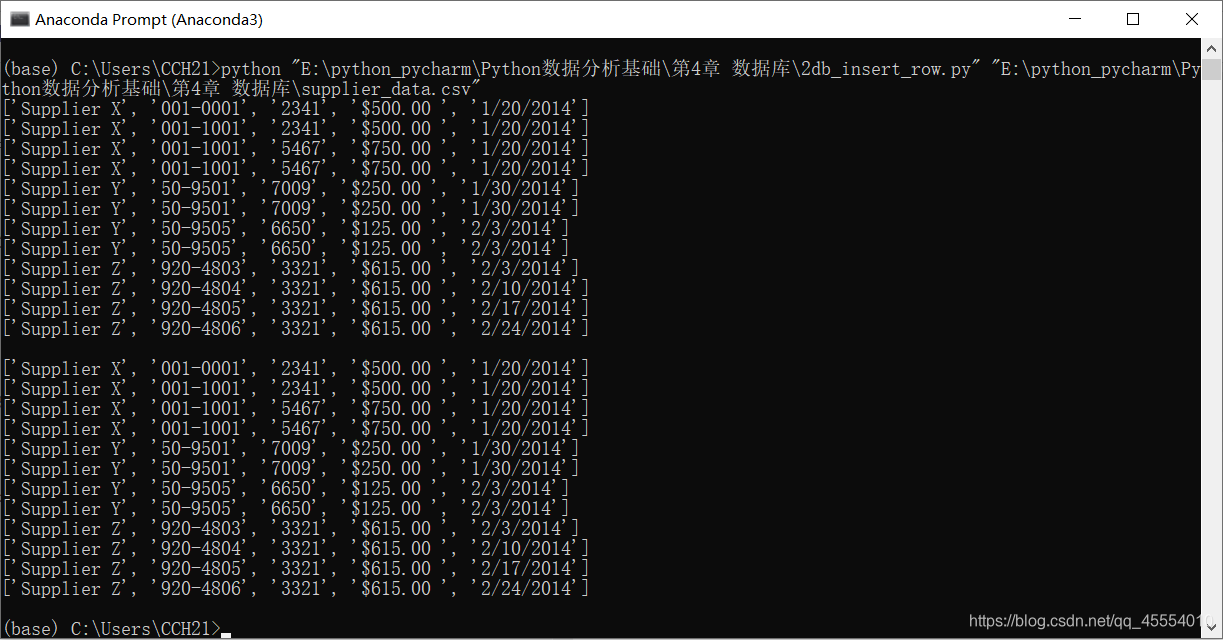
输出的第一部分是从CSV文件中解析出的数据行,输出的第二部分是同样的行,但它是从sqlite数据表中提取出来的。
更新表中记录
我们可以使用CSV输入文件向数据表中添加新行,也可以使用从CSV输入文件中读取数据的技术来更新表中已有的行。在这种情况下,SQL语句有所改变,从INSERT语句变成了UPDATE语句。代码如下:
#!/usr/bin/env python3
import csv
import sqlite3
import sys
# CSV输入文件的路径和文件名
input_file = sys.argv[1]
# 创建SQLite3内存数据库
# 创建带有4个属性的sales表
con = sqlite3.connect(':memory:')
query = """CREATE TABLE IF NOT EXISTS sales
(customer VARCHAR(20),
product VARCHAR(40),
amount FLOAT,
date DATE);"""
con.execute(query)
con.commit()
# 向表中插入几行数据
data = [('Richard Lucas', 'Notepad', 2.50, '2014-01-02'),
('Jenny Kim', 'Binder', 4.15, '2014-01-15'),
('Svetlana Crow', 'Printer', 155.75, '2014-02-03'),
('Stephen Randolph', 'Computer', 679.40, '2014-02-20')]
for tuple in data:
print(tuple)
statement = "INSERT INTO sales VALUES(?, ?, ?, ?)"
con.executemany(statement, data)
con.commit()
# 读取CSV文件并更新特定的行
file_reader = csv.reader(open(input_file, 'r'), delimiter=',')
header = next(file_reader, None)
for row in file_reader:
data = []
for column_index in range(len(header)):
data.append(row[column_index])
print(data)
con.execute("UPDATE sales SET amount=?, date=? WHERE customer=?;", data)
con.commit()
# 查询sales表
cursor = con.execute("SELECT * FROM sales")
rows = cursor.fetchall()
for row in rows:
output = []
for column_index in range(len(row)):
output.append(str(row[column_index]))
print(output)
第40行代码,UPDATE语句代替了原来的INSERT语句。在UPDATE语句中,我们必须指定想更新哪一条记录和哪一个列属性。在这里,我们想为一组特定的customer更新amount值和date值。像前面的示例一样,UPDATE语句也需要占位符表示查询中的值的位置,CSV输入文件中数据的顺序也要同查询中属性的顺序一样。
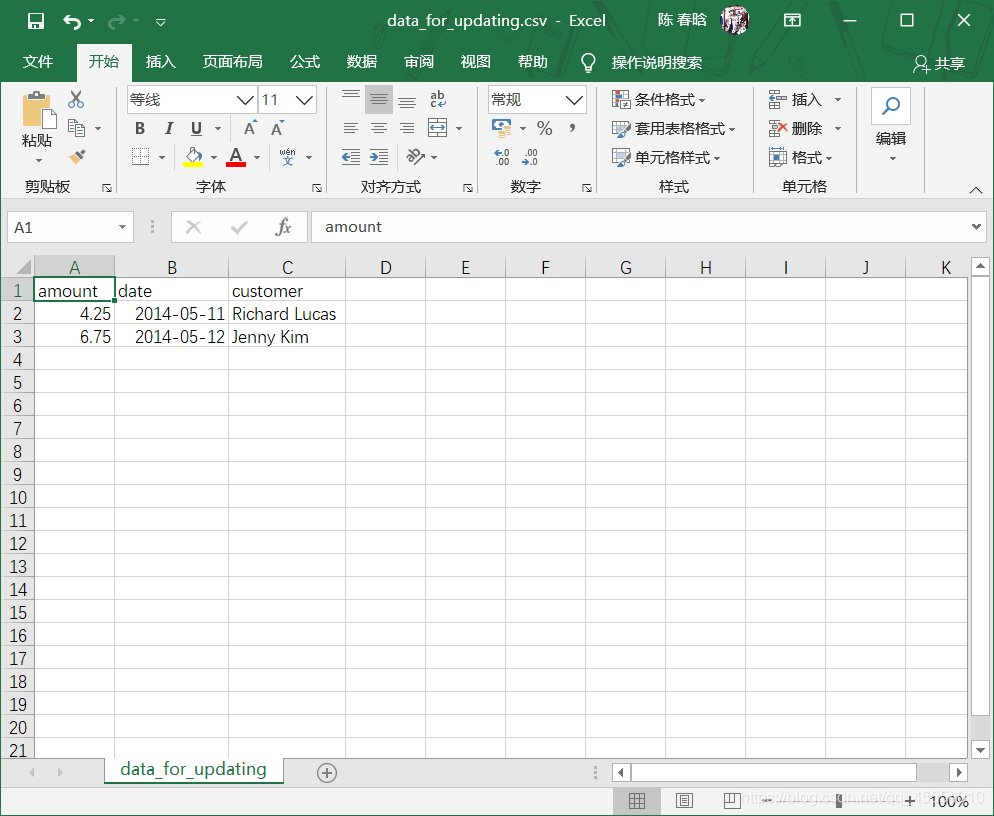
我们新建一个CSV输入文件:
在命令行窗口中运行这个脚本,得到下面的输出结果。
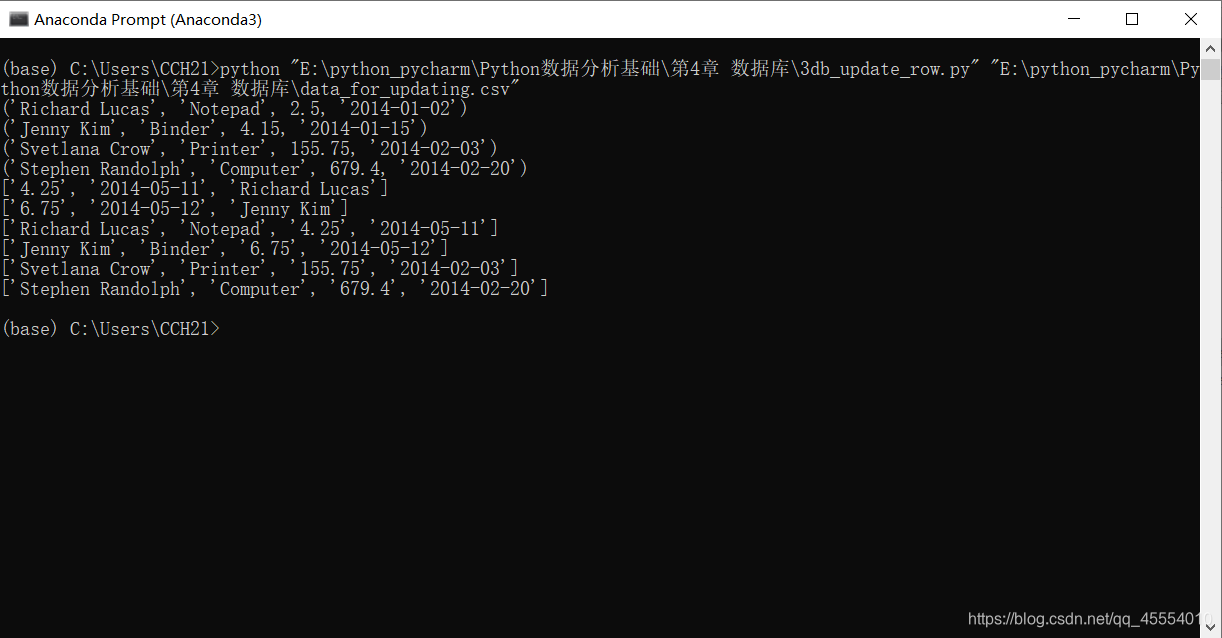
这个输出首先展示了数据库中初始的4行数据,接下来2行是要更新到数据库中的2行数据。在这2行下面,输出还展示了执行更新之后从数据表中取出的4行数据。
