逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。通常,所有记录都有完全相同的字段序列。通常都是纯文本文件。
与Excel文件相比,CSV文件的一个主要优点是有很多程序可以存储、转换和处理纯文本文件;相比之下,能处理Excel文件的应用程序却不多。使用CSV文件的另一个问题它只能保存数据,不能保存公式,但是通过数据存储(CSV文件)和数据处理(Python脚本)分离,我们可以很容易地在不同数据集上进行加工处理。当数据存储和数据处理过程分开进行时,错误(不管是数据处理中的错误,还是数据存储中的错误)不但更容易被发现,而且更难扩散。
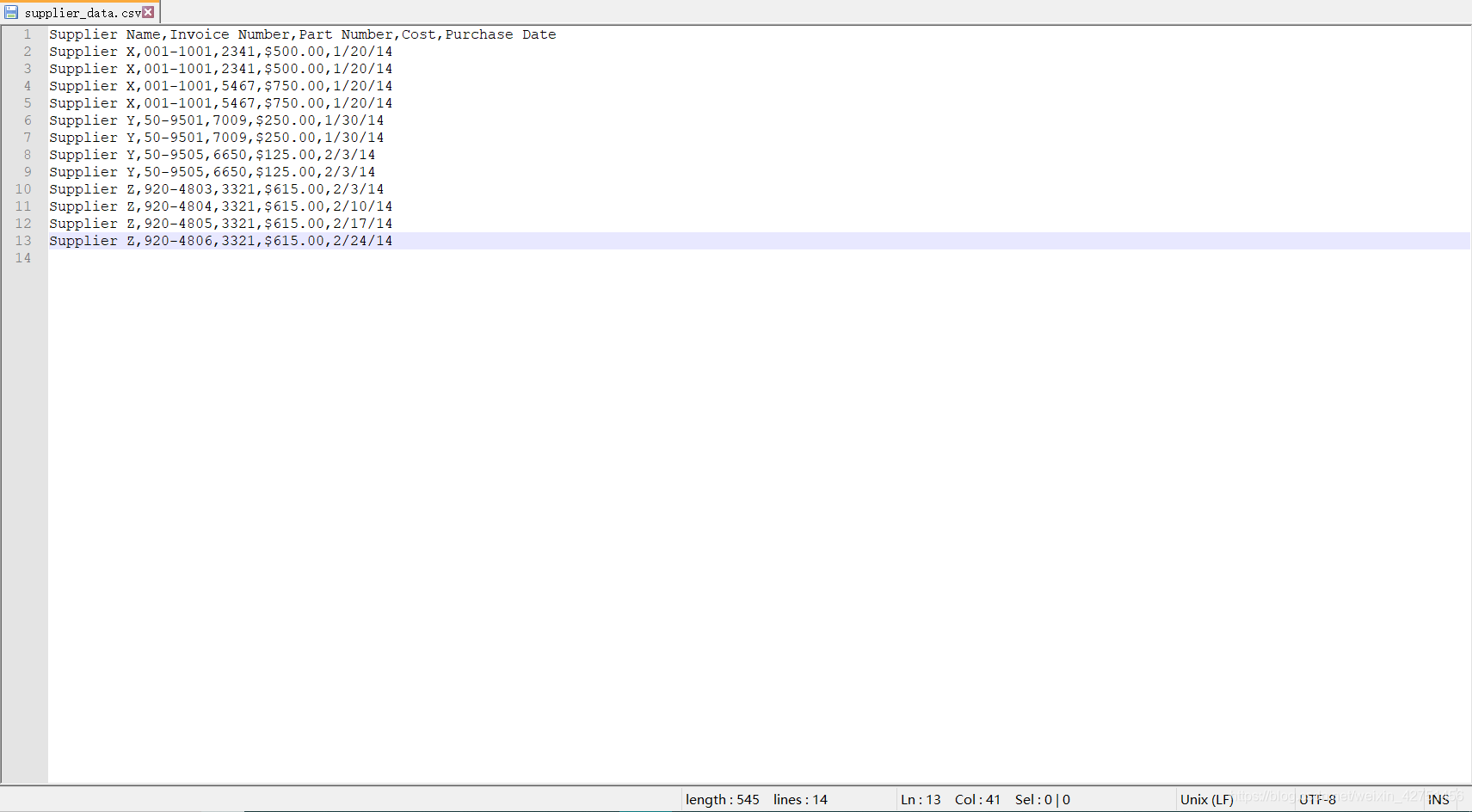
下面我用几个对CSV文件的具体操作来展示。下面是我们要进行操作的一个CSV文件:
读写CSV文件(使用csv模块)
先贴上代码:
import csv # 导入csv模块
import sys
input_file = sys.argv[1] # argv变量捕获了传递给python脚本的命令行参数列表(你在命令行中的所有输入)
output_file = sys.argv[2] # argv[0]就是脚本名称,argv[1]则是传递给脚本的第一个附加参数
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'w', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file, delimiter=',')
# 用reader函数创建一个文件读取对象,用来读取输入文件中的行
filewriter = csv.writer(csv_out_file, delimiter=',')
# 用writer函数创建一个文件写入对象,用来将数据写入输出文件
for row_list in filereader:
print(row_list)
filewriter.writerow(row_list)
这里对那个reader函数和writer函数中的第二个参数解释一下:它是默认分隔符,指定这个分隔符参数,是为了防备我们处理的输入文件或要写入的输出文件具有不同的分隔符,例如分号或制表符。这个实例中,如果我们要处理的文件里面有逗号出现,比如$6,015.00,如果不指定分隔符,那么这个数据就会被切开导致处理失败。
我们运行一下试试看:
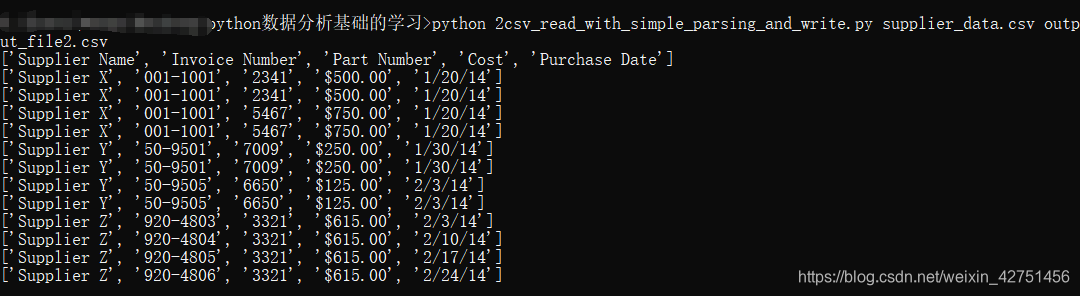
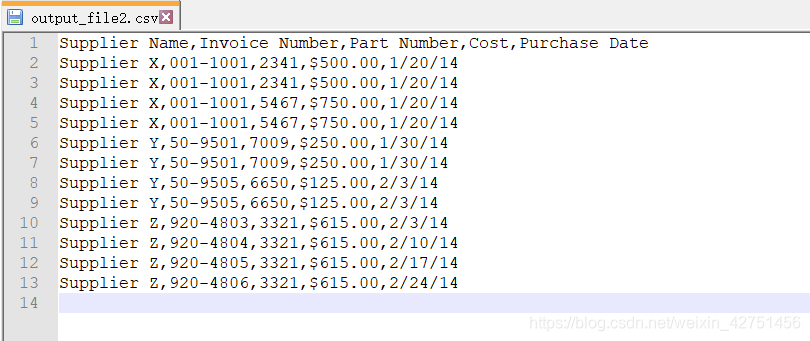 单个文件我们可能体会不到,但如果需要处理上百个甚至上千个或者数据量极为庞大的文件,用脚本处理的方便快捷性会更加明显,后面还会说到处理多个文件。
单个文件我们可能体会不到,但如果需要处理上百个甚至上千个或者数据量极为庞大的文件,用脚本处理的方便快捷性会更加明显,后面还会说到处理多个文件。
筛选特定的行
行中的值满足某个条件
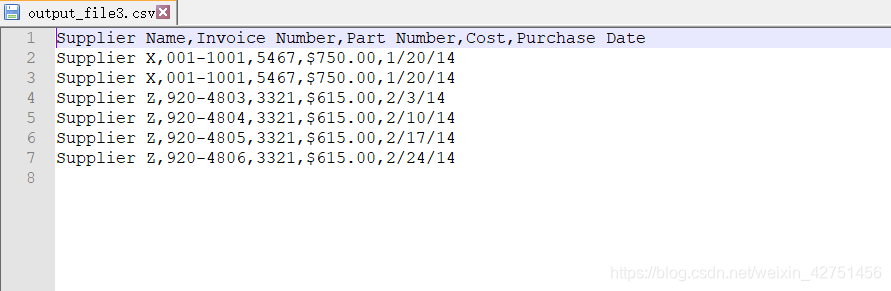
在这个实例中,假设我们要保留供应商名字为Supplier Z或成本大于$600.00的行
import csv
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'w', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
header = next(filereader)
# next函数读取输入文件的第一行,赋值给名为header的列表变量
filewriter.writerow(header)
for row_list in filereader:
supplier = str(row_list[0]).strip()
cost = str(row_list[3]).strip('$').replace(',', '')
if supplier == 'Supplier Z' or float(cost) > 600.0:
filewriter.writerow(row_list)

行中的值属于某个集合
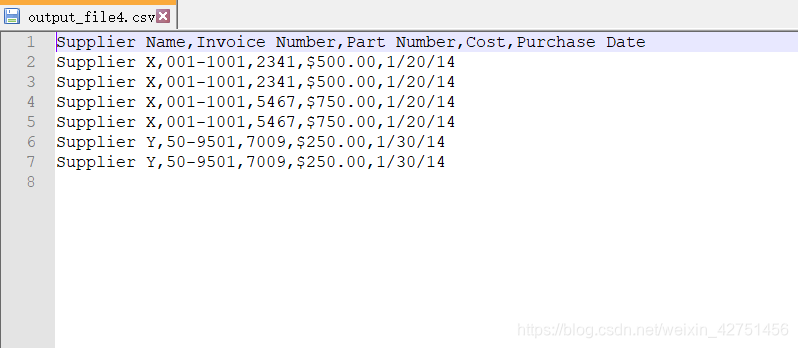
这个实例中,假设我们需要保留那些购买日期属于集合{‘1/20/14’,‘1/30/14’}的行
import csv
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
important_dates = ['1/20/14', '1/30/14']
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'w', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
header = next(filereader)
filewriter.writerow(header)
for row_list in filereader:
a_date = row_list[4]
if a_date in important_dates:
# 加入判断条件
filewriter.writerow(row_list)
行中的值匹配于某个模式/正则表达式
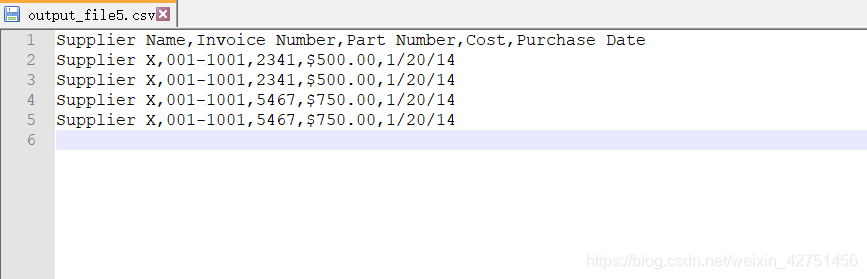
在这个实例中,假设我们要保留所有发票编号由‘001-’开头的行
import csv
import re
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
pattern = re.compile(r'(?P<my_pattern_group>^001-.*)', re.I)
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'w', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
header = next(filereader)
filewriter.writerow(header)
for row_list in filereader:
invoice_number = row_list[1]
if pattern.search(invoice_number):
filewriter.writerow(row_list)
筛选特定行的方法大同小异,只要留意筛选条件,熟悉基本操作流程就可以做到。选取特定的列就不说了。
剩下的有点难度的会放到下一篇博客来讲,熟悉这两个基本操作就可以使用大多操作哦,个人觉得这两个操作比较具有代表性。
如需转载,请注明原文出处,作者:vergilben