这一节主要讲一下在读写CSV文件时筛选特定的行。
有些时候,我们并不需要文件中所有的数据。例如,我们可能只需要一个包含特定词或数字的行的子集,或者是与某个具体日期关联的行的子集。在这些情况下,我们可以用Python筛选出特定的行来使用。
下面主要来讲在输入文件中筛选出特定行的3种方法:
1.行中的值满足某个条件;
2.行中的值属于某个集合;
3.行中的值匹配于某个模式(正则表达式)。
其实,这三种筛选方法的代码在结构上是一致的。通用结构如下:
for row in filereader:
***if value in row meets some business rule or set of rules:***
do something
else:
do something else
下面我们来详细讨论一下上述3种方法。
行中的值满足某个条件
1.基础Python
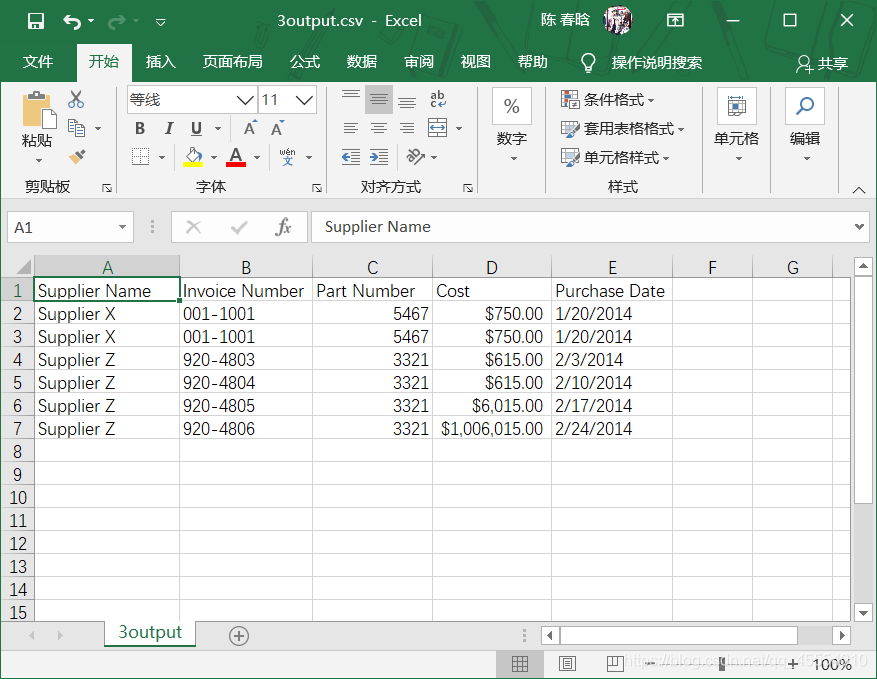
在之前的样例中,如果我们只想保留供应商名字为Supplier Z或成本大于$600.00的行,并将结果写入输出文件。代码如下:
#!/usr/bin/env python3
import csv
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'w', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
header = next(filereader)
filewriter.writerow(header)
for row_list in filereader:
supplier = str(row_list[0]).strip()
cost = str(row_list[3]).strip('$').replace(',', '')
if supplier == 'Supplier Z' or float(cost) > 600.0:
filewriter.writerow(row_list)
我们来解释一下上面的代码。
header = next(filereader)
filewriter.writerow(header)
这两行代码使用csv模块的next()函数读出输入文件的第一行,赋给列表变量header,并且使用writerow()函数将标题行写入输出文件。
supplier = str(row_list[0]).strip()
这行代码取出每行数据中的供应商名字,赋给变量supplier。这行代码使用列表索引取出每行数据的第一个值row[0],使用str()函数将其转换为一个字符串,再使用strip()函数删除字符串两端的空格、制表符和换行符。最后,将处理好的字符串赋给变量supplier。
cost = str(row_list[3]).strip('$').replace(',', '')
这行代码取出每行数据中的成本,赋给变量cost。这行代码使用列表索引取出每行数据的第四个值row[3],使用str()函数将其转换为一个字符串,再使用strip('$')函数从字符串中删除$符号,再使用replace()函数从字符串中删除逗号。最后,将处理好的字符串赋给变量cost。
if supplier == 'Supplier Z' or float(cost) > 600.0:
filewriter.writerow(row_list)
这两行代码通过创建if语句来检验每行中的这两个值是否满足条件,若条件满足,则使用filewriter的writerow()函数将其写入输出文件。
我们在命令行窗口运行这个脚本。在窗口中没有任何输出,我们可以打开输出文件来查看结果。
2.pandas
pandas模块提供了一个loc函数,它可以同时选择特定的行与列。使用pandas模块的代码如下:
#!/usr/bin/env python3
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_csv(input_file)
data_frame['Cost'] = data_frame['Cost'].str.strip('$').astype(float)
data_frame_value_meets_condition = data_frame.loc[(data_frame['Supplier Name'].str.contains('Z'))
| (data_frame['Cost'] > 600.0), :]
data_frame_value_meets_condition.to_csv(output_file, index=False)
我们在命令行窗口运行这个脚本,同样地,在屏幕上我们看不到任何输出,我们可以打开输出文件查看结果。
此处省略输出结果。
行中的值属于某个集合
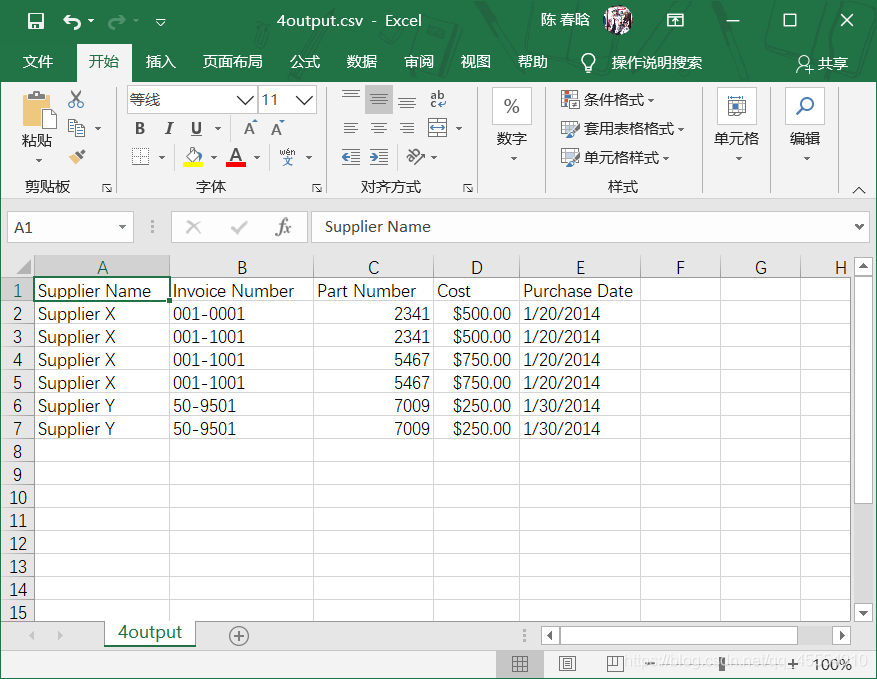
有些时候,当行中的值属于某个集合时,才需要保留这些行。例如,我们希望在数据集中保留那些供应商名字属于集合{Supplier X, Supplier Y}的行,或者希望保留所有购买日期属于集合{'1/20/2014', '1/30/2014'}的行。在这种情况下,我们可以检验行中的值是否属于某个集合,筛选出具有属于该集合的行。
1.基础Python
代码如下:
#!/usr/bin/env python3
import csv
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
important_dates = ['1/20/2014', '1/30/2014']
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'w', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
header = next(filereader)
filewriter.writerow(header)
for row_list in filereader:
a_date = row_list[4]
if a_date in important_dates:
filewriter.writerow(row_list)
我们来讨论一下上述代码。
important_dates = ['1/20/2014', '1/30/2014']
这行代码创建了一个名为important_dates的列表变量,其中包含了两个特定日期。这个列表变量就是我们的集合。
a_date = row_list[4]
这行代码取出每一行的购买日期,并赋给变量a_date。
if a_date in important_dates:
filewriter.writerow(row_list)
这行代码创建了一个if语句来检验变量a_date中的购买日期是否属于集合important_date,如果变量值在集合中,下一行代码就将这一行写入输出文件。
我们在命令行窗口中运行这个脚本,并打开输出文件来查看结果。
2.pandas
使用pandas模块的代码如下所示:
#!/usr/bin/env python3
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_csv(input_file)
important_dates = ['1/20/2014', '1/30/2014']
data_frame_value_in_set = data_frame.loc[data_frame['Purchase Date'].isin(important_dates), :]
data_frame_value_in_set.to_csv(output_file, index=False)
这里的输出结果和上面基础Python方法的输出结果一致,故省略。
行中的值匹配于某个模式(正则表达式)
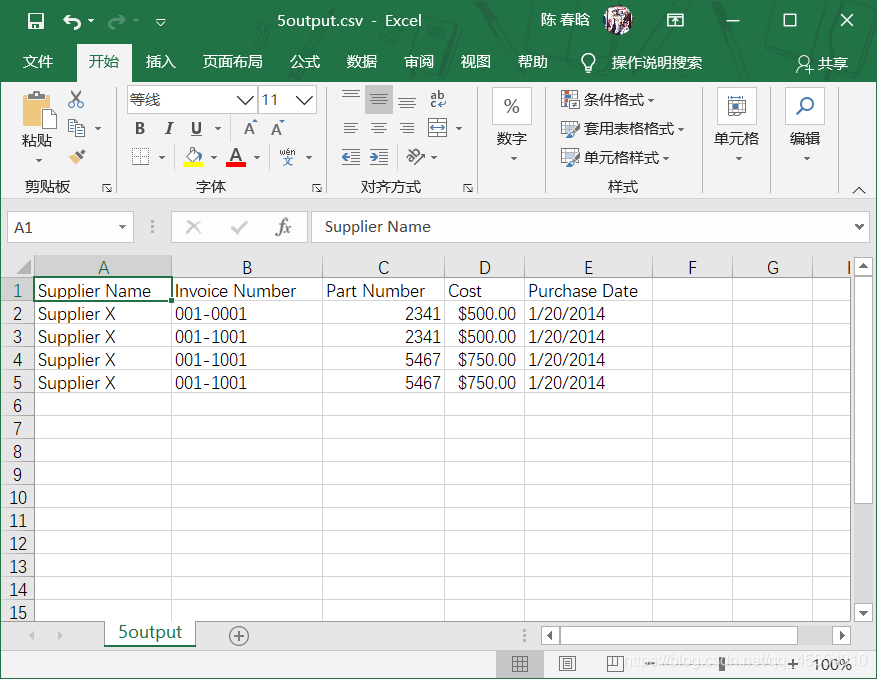
有些时候,当行中的值匹配或包含一个特定模式(正则表达式)时,才需要保留这些行。例如,我们希望在数据集中保留所有发票开始于“001-”的行,或者希望保留所有供应商名字中包含“Y”的行。在这种情况下,我们可以检验行中的值是否匹配或包含某种模式,然后筛选出匹配或包含该模式的行。
1.基础Python
代码如下:
#!/usr/bin/env python3
import csv
import re
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
pattern = re.compile(r'(?P<my_pattern_group>^001-.*)', re.I)
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'w', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
header = next(filereader)
filewriter.writerow(header)
for row_list in filereader:
invoice_number = row_list[1]
if pattern.search(invoice_number):
filewriter.writerow(row_list)
我们来讨论一下上述代码。
import re
这一行代码导入了re模块,也就是正则表达式模块。
pattern = re.compile(r'(?P<my_pattern_group>^001-.*)', re.I)
这行代码使用re模块的compile()函数创建变量pattern。其中r表示将单引号之间的模式当作原始字符串来处理。元字符?P<my_pattern_group>捕获了名为<my_pattern_group>的组中匹配了的字符串,以便在需要的时候将它们打印到屏幕或写入文件。这里要搜索的实际模式是^001-.*。插入符号^表示只在字符串开头搜索模式,*表示重复前面的字符0次或更多次,.*组合在一起使用表示除换行符\n之外的任意字符可以在“001-”后面出现任意次。最后,参数re.I告诉了正则表达式进行大小写敏感的匹配。
有关正则表达式的内容,可以参考我之前写的博客:Python与正则表达式。
if pattern.search(invoice_number):
filewriter.writerow(row_list)
这里使用re模块的search()函数在invoice_number的值中寻找模式,如果模式出现在变量值中,就将这行写入输出文件。
我们在命令行窗口运行这个脚本,得到输出文件如下图所示。
2.pandas
使用pandas模块的代码如下所示:
#!/usr/bin/env python3
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_csv(input_file)
data_frame_value_matches_pattern = data_frame.loc[data_frame['Invoice Number'].str.startswith("001-"), :]
data_frame_value_matches_pattern.to_csv(output_file, index=False)
上述代码中,startswith()函数用来搜索数据,不用再使用正则表达式。
这里的输出结果和上面基础Python方法的输出结果一致,故省略。
