版权声明:个人随手学习笔记,任何欠妥之处,还望海涵指正~~~ https://blog.csdn.net/sinat_41842926/article/details/84728544
因本人刚开始写博客,学识经验有限,如有不正之处望读者指正,不胜感激;也望借此平台留下学习笔记以温故而知新。这个系列主要是Python数据分析基础的学习笔记。
原始CSV文件:supplier_data.csv
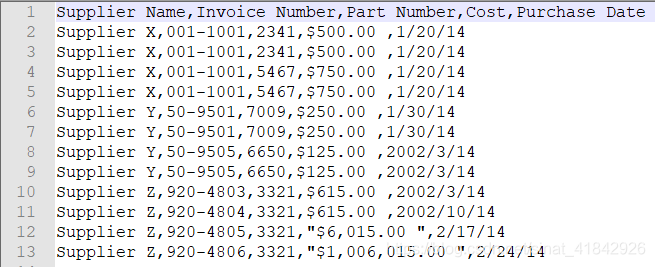
使用Python代码来读写和处理CSV文件基础实例
# 使用基础Python代码来读写和处理CSV文件
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
with open(input_file, 'r', newline='') as filereader:
with open(output_file, 'w', newline='') as filewriter:
header = filereader.readline()
header = header.strip()
header_list = header.split(',')
print(header_list)
filewriter.write(','.join(map(str,header_list))+'\n')
for row in filereader:
row = row.strip()
row_list = row.split(',')
print(row_list)
filewriter.write(','.join(map(str,row_list))+'\n')
使用pandas 代码来读写和处理CSV文件基础实例
# 使用pandas处理CSV文件
import sys
import pandas as pd
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_csv(input_file)
print(data_frame)
data_frame.to_csv(output_file, index=False)
使用Python内置的csv模块
# 使用Python内置的csv模块
import csv
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'w', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file, delimiter=',')
filewriter = csv.writer(csv_out_file, delimiter=',')
for row_list in filereader:
print(row_list)
filewriter.writerow(row_list)
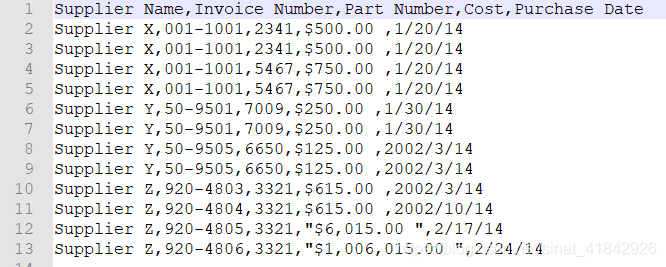
筛选特定的行
# 筛选特定的行
# -*- coding: utf-8 -*-
import sys
import csv
input_file = sys.argv[1]
output_file = sys.argv[2]
with open(input_file,'r',newline='') as csv_in_file:
with open(output_file,'w',newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
header = next(filereader)
filewriter.writerow(header)
for row_list in filereader:
supplier = str(row_list[0]).strip()
cost = str(row_list[3]).strip('$').replace(',','')
if supplier == 'Supplier Z' or float(cost)>600.0:
filewriter.writerow(row_list)
pandas 提供的loc函数选择特定的行与列
# pandas 提供的loc函数选择特定的行与列
#!/usr/bin/env python3
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_csv(input_file)
data_frame['Cost'] = data_frame['Cost'].str.strip('$').astype(float)
data_frame_value_meets_condition = data_frame.loc[(data_frame\
['Supplier Name'].str.contains('Z')) | (data_frame['Cost'] > 600.0), :]
data_frame_value_meets_condition.to_csv(output_file, index=False)
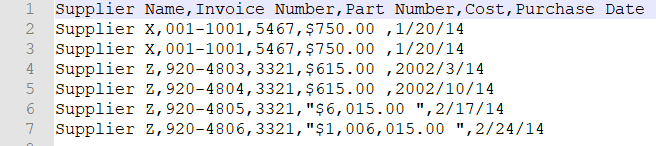
行中的值属于某个集合
# 行中的值属于某个集合
#!/usr/bin/env python3
import csv
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
important_dates = ['1/20/14', '1/30/14']
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'w', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
header = next(filereader)
filewriter.writerow(header)
for row_list in filereader:
a_date = row_list[4]
if a_date in important_dates:
filewriter.writerow(row_list)
pandas筛选指定行
# pandas筛选指定行
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_csv(input_file)
important_dates = ['1/20/14', '1/30/14']
data_frame_value_in_set = data_frame.loc[data_frame['Purchase Date'].isin(important_dates),:]
data_frame_value_in_set.to_csv(output_file, index=False)
行中的值匹配于某个模式/正则表达式
# 行中的值匹配于某个模式/正则表达式
import csv
import re
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
pattern = re.compile(r'(?P<my_pattern_group>^001-.*)', re.I)
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'w', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
header = next(filereader)
filewriter.writerow(header)
for row_list in filereader:
invoice_number = row_list[1]
if pattern.search(invoice_number):
filewriter.writerow(row_list)
pandas执行行中的值匹配于某个模式/正则表达式
# pandas执行行中的值匹配于某个模式/正则表达式
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_csv(input_file)
data_frame_value_matches_pattern = data_frame.loc[data_frame['Invoice Number'].\
str.startswith("50-"), :]
data_frame_value_matches_pattern.to_csv(output_file, index=False)

选取特定的列
# 选取特定的列
import csv
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
my_columns = [0, 3]
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'w', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
for row_list in filereader:
row_list_output = [ ]
for index_value in my_columns:
row_list_output.append(row_list[index_value])
filewriter.writerow(row_list_output)
pandas选取特定的列
# pandas选取特定的列
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_csv(input_file)
data_frame_column_by_index = data_frame.iloc[:, [0, 3]]
data_frame_column_by_index.to_csv(output_file, index=False)
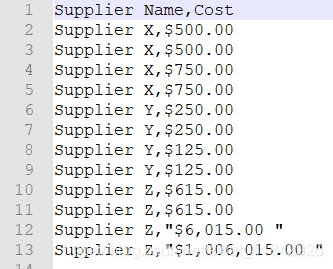
使用列标题选取特定列
# 使用列标题选取特定列
#!/usr/bin/env python3
import csv
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
my_columns = ['Invoice Number', 'Purchase Date']
my_columns_index = []
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'w', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
header = next(filereader, None)
for index_value in range(len(header)):
if header[index_value] in my_columns:
my_columns_index.append(index_value)
filewriter.writerow(my_columns)
for row_list in filereader:
row_list_output = [ ]
for index_value in my_columns_index:
row_list_output.append(row_list[index_value])
filewriter.writerow(row_list_output)
pandas使用列标题选取特定列
# pandas使用列标题选取特定列
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_csv(input_file)
data_frame_column_by_name = data_frame.loc[:, ['Invoice Number', 'Purchase Date']]
data_frame_column_by_name.to_csv(output_file, index=False)
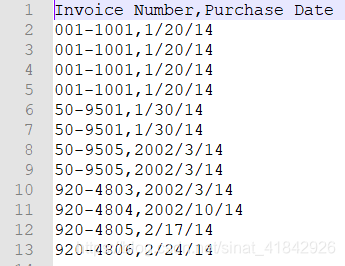
选取连续的行
# 选取连续的行
import csv
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
row_counter = 0
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'w', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
for row in filereader:
if row_counter >= 3 and row_counter <= 15:
filewriter.writerow([value.strip() for value in row])
print(row_counter, [value.strip() for value in row])
row_counter += 1
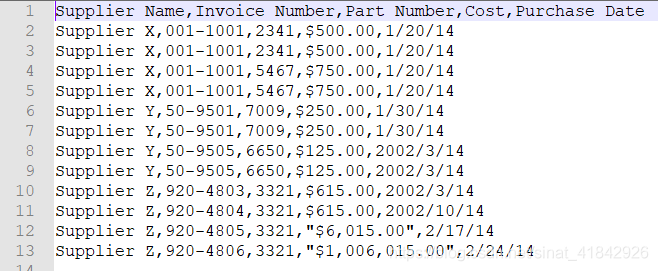
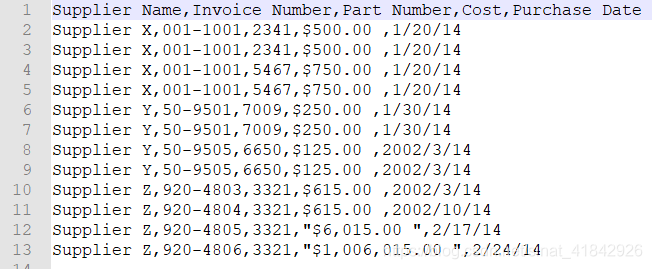
添加标题行
# 添加标题行
import csv
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'w', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
header_list = ['Supplier Name', 'Invoice Number','Part Number', 'Cost', 'Purchase Date']
filewriter.writerow(header_list)
for row in filereader:
filewriter.writerow(row)
pandas添加标题行
# pandas添加标题行
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
header_list = ['Supplier Name', 'Invoice Number',\
'Part Number', 'Cost', 'Purchase Date']
data_frame = pd.read_csv(input_file,header=None, names=header_list)
data_frame.to_csv(output_file, index=False)
文件计数与文件中的行列计数
# 文件计数与文件中的行列计数
import csv
import glob
import os
import sys
input_path = sys.argv[1]
file_counter = 0
for input_file in glob.glob(os.path.join(input_path,'sales_*')):
row_counter = 1
with open(input_file, 'r', newline='') as csv_in_file:
filereader = csv.reader(csv_in_file)
header = next(filereader, None)
for row in filereader:
row_counter += 1
print('{0!s}: \t{1:d} rows \t{2:d} columns'.format(os.path.basename(input_file), row_counter, len(header)))
file_counter += 1
print('Number of files: {0:d}'.format(file_counter))
从多个文件中连接数据
# 从多个文件中连接数据
import csv
import glob
import os
import sys
input_path = sys.argv[1]
output_file = sys.argv[2]
first_file = True
for input_file in glob.glob(os.path.join(input_path,'sales_*')):
print(os.path.basename(input_file))
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'a', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
if first_file:
for row in filereader:
filewriter.writerow(row)
first_file = False
else:
header = next(filereader)
for row in filereader:
filewriter.writerow(row)
pandas文件计数与文件中的行列计数
# pandas文件计数与文件中的行列计数
import pandas as pd
import glob
import os
import sys
input_path = sys.argv[1]
output_file = sys.argv[2]
all_files = glob.glob(os.path.join(input_path,'sales_*'))
all_data_frames = []
for file in all_files:
data_frame = pd.read_csv(file, index_col=None)
all_data_frames.append(data_frame)
data_frame_concat = pd.concat(all_data_frames, axis=0, ignore_index=True)
data_frame_concat.to_csv(output_file, index = False)
原始CSV文件:sales_january_2014

原始CSV文件:sales_february_2014
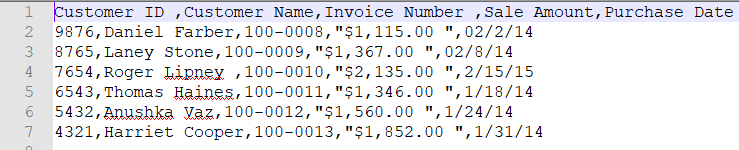
原始CSV文件:sales_march_2014

计算每个文件中值的总和与均值
# 计算每个文件中值的总和与均值
import csv
import glob
import os
import sys
input_path = sys.argv[1]
output_file = sys.argv[2]
output_header_list = ['file_name', 'total_sales', 'average_sales']
csv_out_file = open(output_file, 'a', newline='')
filewriter = csv.writer(csv_out_file)
filewriter.writerow(output_header_list)
for input_file in glob.glob(os.path.join(input_path,'sales_*')):
with open(input_file, 'r', newline='') as csv_in_file:
filereader = csv.reader(csv_in_file)
output_list = [ ]
output_list.append(os.path.basename(input_file))
header = next(filereader)
total_sales = 0.0
number_of_sales = 0.0
for row in filereader:
sale_amount = row[3]
total_sales += float(str(sale_amount).strip('$').replace(',',''))
number_of_sales += 1
average_sales = '{0:.2f}'.format(total_sales / number_of_sales)
output_list.append(total_sales)
output_list.append(average_sales)
filewriter.writerow(output_list)
csv_out_file.close()
pandas计算每个文件中值的总和与均值
# pandas计算每个文件中值的总和与均值
import pandas as pd
import glob
import os
import sys
input_path = sys.argv[1]
output_file = sys.argv[2]
all_files = glob.glob(os.path.join(input_path,'sales_*'))
all_data_frames = []
for input_file in all_files:
data_frame = pd.read_csv(input_file, index_col=None)
total_sales = pd.DataFrame([float(str(value).strip('$').replace(',','')) \
for value in data_frame.loc[:, 'Sale Amount']]).sum()
average_cost = pd.DataFrame([float(str(value).strip('$').replace(',','')) \
for value in data_frame.loc[:, 'Sale Amount']]).mean()
data = {'file_name': os.path.basename(input_file),\
'total_sales': total_sales,'average_cost': average_cost}
all_data_frames.append(pd.DataFrame(data, \
columns=['file_name', 'total_sales', 'average_cost']))
data_frames_concat = pd.concat(all_data_frames, axis=0, ignore_index=True)
data_frames_concat.to_csv(output_file, index = False)
