选取连续的行
有时,工作表的头部和尾部是我们不想处理的。在很多情况下,工作表头部是标题、作者信息等,尾部是来源、假设、附加说明、注意事项等,我们并不需要处理这些内容。在这时,我们可以用Python来选取CSV文件中连续的行。
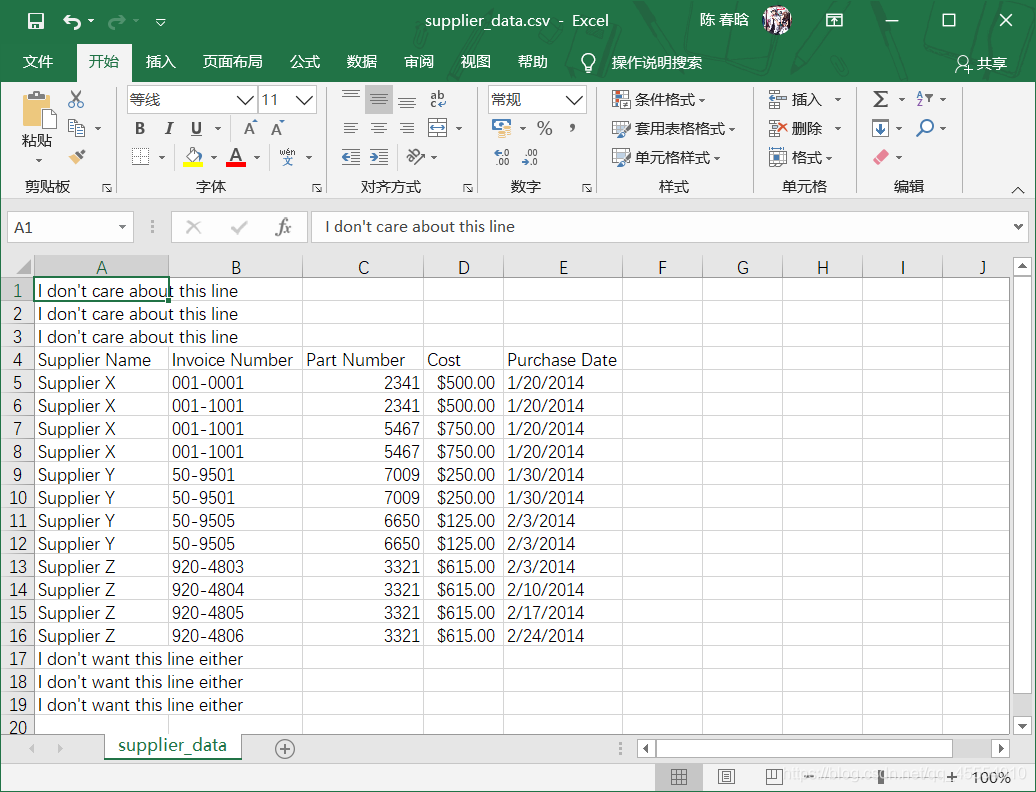
我们把之前的supplier_data.csv文件打开,在工作表头部和尾部分别加入一些不需要处理的内容,如下图所示。
1.基础Python
要使用基础Python选取特定的行,我们需要创建一个变量row_counter来跟踪行索引。在上面的示例中,我们知道应该保留行索引大于或等于3并且小于或等于15的行。代码如下:
#!/usr/bin/env python3
import csv
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
row_counter = 0
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'w', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
for row in filereader:
if 3 <= row_counter <= 15:
filewriter.writerow([value.strip() for value in row])
row_counter += 1
如果我们对比一下之前的读写CSV文件的代码,不难发现上面的这个代码只是在原来的基础上稍微做了一下改动,引入变量row_counter,并且在遍历输入文件中所有的行时使用if语句跳过不需要的头部和尾部内容,只保留需要的行。
对于输入文件的前3行,行索引值为0,1,2,此时if的判断结果为False,所以不执行if代码块,并将row_counter的值加1。对于输入文件的最后3行,行索引值为16,17,18,if的判断结果也是False,也不执行if代码块,并将row_counter的值加1。
而对于想要保留的行,它们的行索引值为3~15,即row_counter在3和15之间。此时if判断结果为True,执行if代码块,处理这些行并将其写入输出文件。在列表生成式中,使用strip()函数除去每行两端的空格、制表符和换行符。
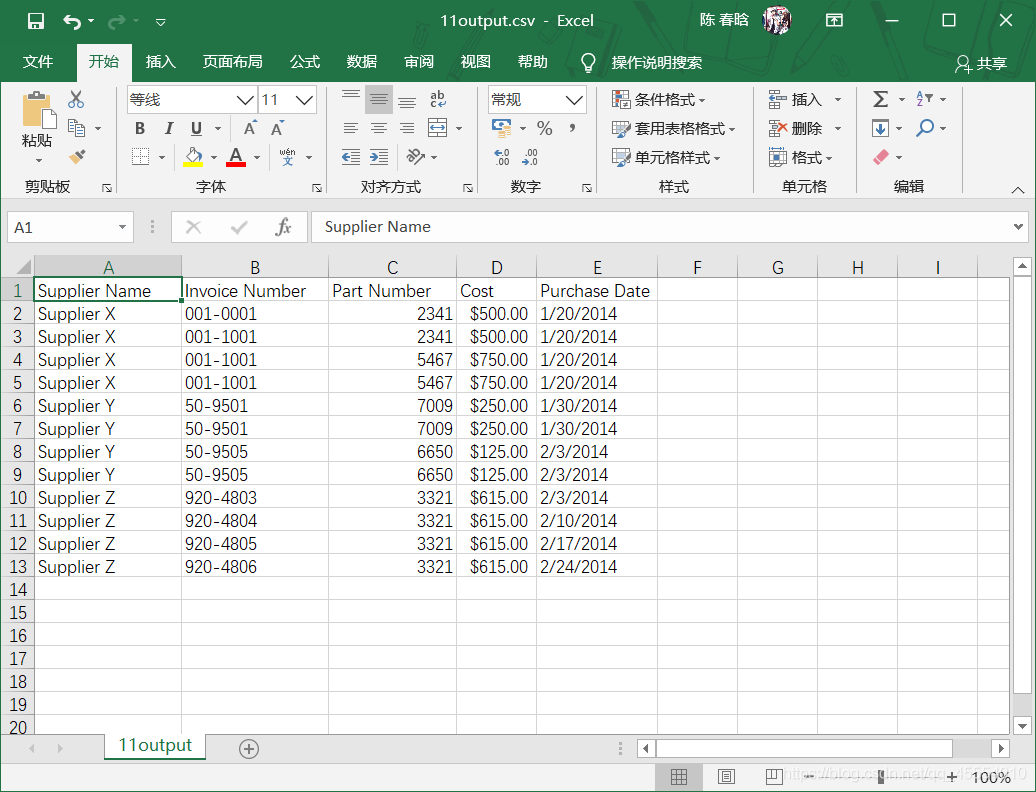
我们在命令行窗口中运行这个脚本,并打开输出文件查看结果。
2.pandas
在pandas模块中,drop()函数可以根据行索引或列标题来丢弃行或列。也就是说,我们只需要使用drop函数丢弃掉前3行和后3行(即行索引为0,1,2,16,17,18的行)即可达到目的。代码如下:
#!/usr/bin/env python3
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
data_frame = pd.read_csv(input_file, header=None)
data_frame = data_frame.drop([0, 1, 2, 16, 17, 18])
data_frame.columns = data_frame.iloc[0]
data_frame = data_frame.reindex(data_frame.index.drop(3))
data_frame.to_csv(output_file, index=False)
pandas模块中的iloc函数功能强大,它可以根据行索引选取一个单独行作为列索引。reindex()函数可以为数据框重新生成索引。
此处省略输出结果。
添加标题行
有些时候,电子表格没有标题行,而我们却希望所有列都有列标题。使用Python脚本可以添加列标题。
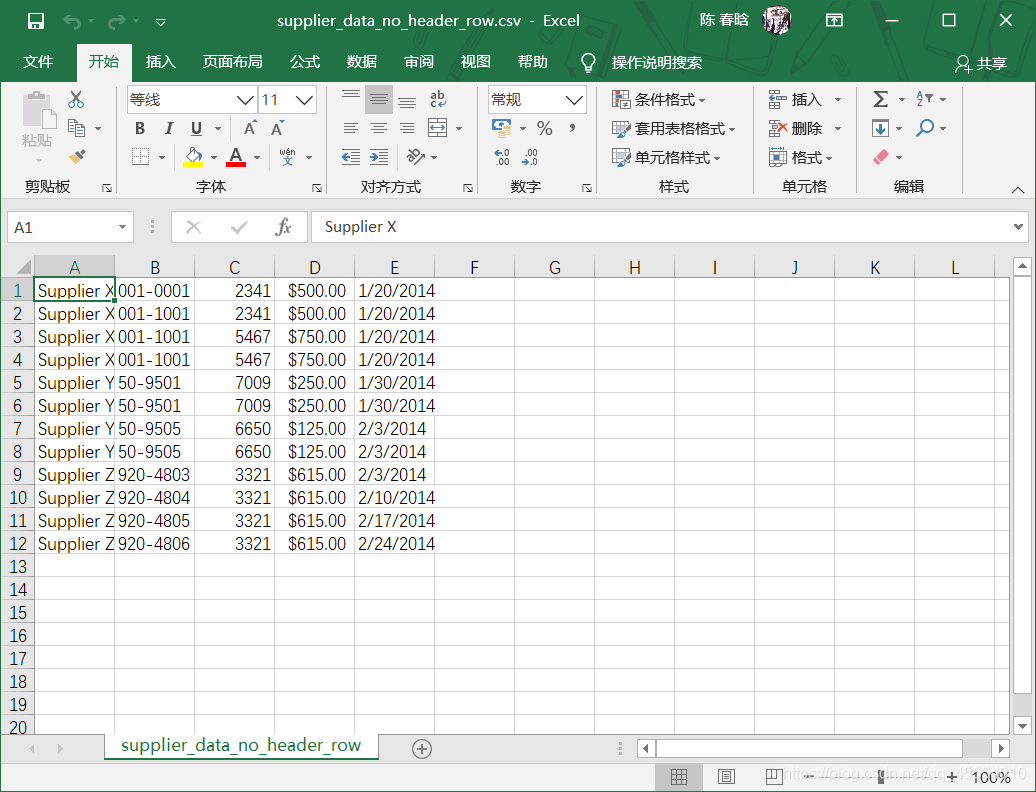
我们打开supplier_data.csv文件。删除掉标题行,并将其保存为supplier_data_no_header_row.csv。
1.基础Python
代码如下:
#!/usr/bin/env python3
import csv
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'w', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
header_list = ['Supplier Name', 'Invoice Number', 'Part Number', 'Cost', 'Purchase Date']
filewriter.writerow(header_list)
for row in filereader:
filewriter.writerow(row)
在上面的代码中,创建了一个列表变量header_list,其中包含了作为列标题的5个字符串。writerow()函数将这些列表值写入输出文件的第一行。
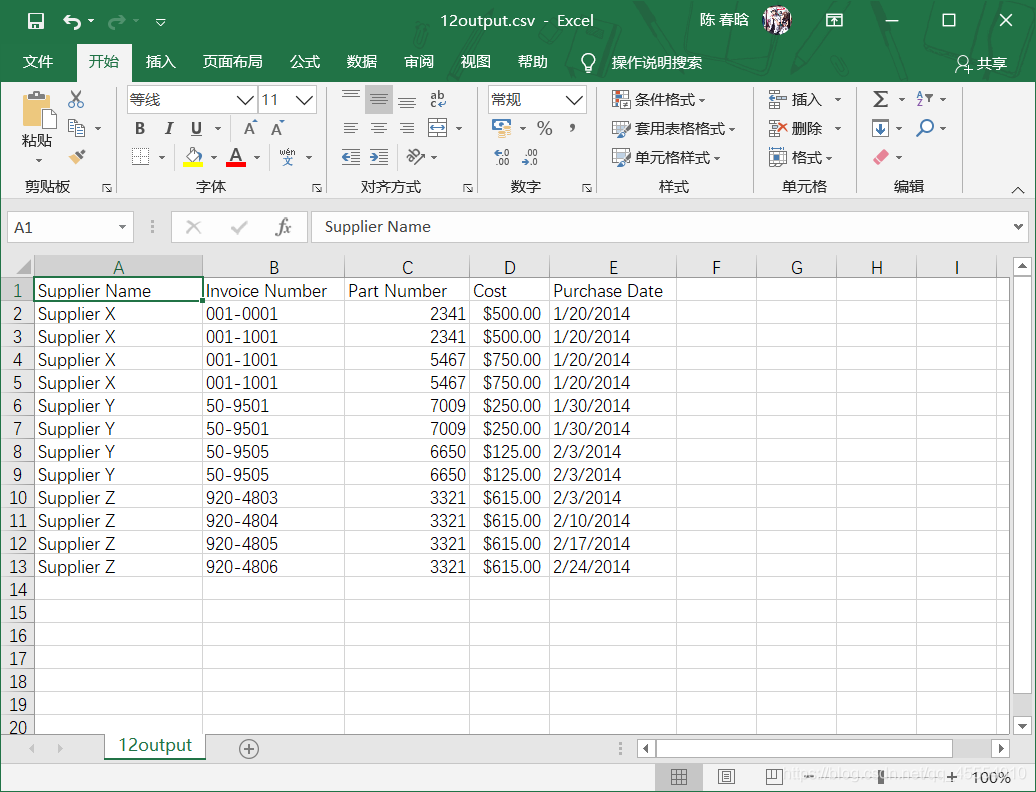
我们在命令行窗口中运行这个脚本,并打开输出文件查看结果。
2.pandas
pandas模块中的read_csv()函数可以直接指定输入文件不包含标题行,并可以提供一个列标题列表。代码如下:
#!/usr/bin/env python3
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
header_list = ['Supplier Name', 'Invoice Number', 'Part Number', 'Cost', 'Purchase Date']
data_frame = pd.read_csv(input_file, header=None, names=header_list)
data_frame.to_csv(output_file, index=False)
此处省略输出结果。
