这一篇博客主要讲一下处理多个工作簿。
之前我们已经创建了sales_2013.xlsx工作簿。在这里,我们再创建两个新的工作簿sales_2014.xlsx和sales_2015.xlsx,并且修改其中的工作表名称和日期数据。
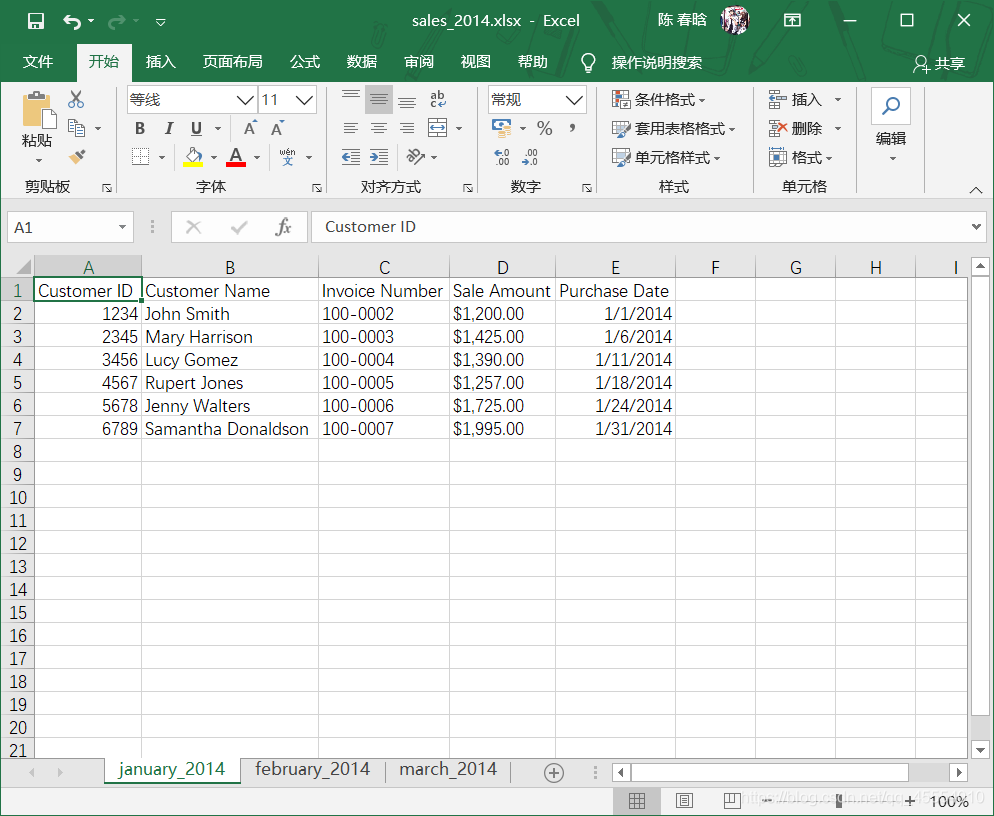
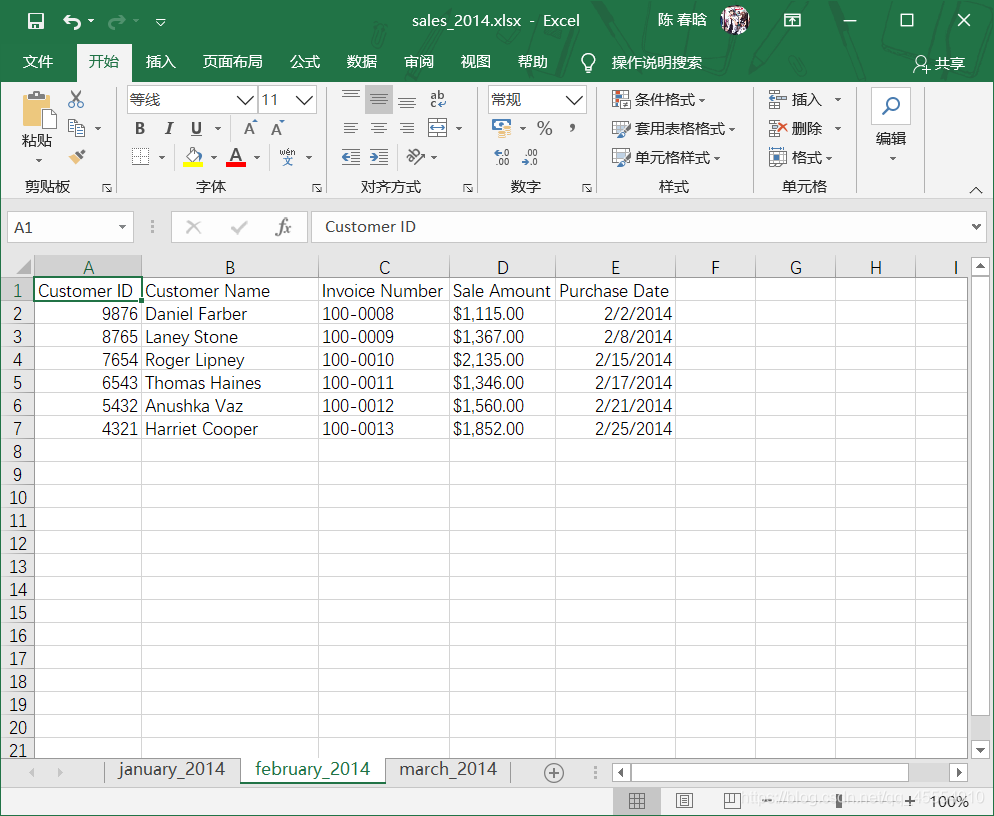
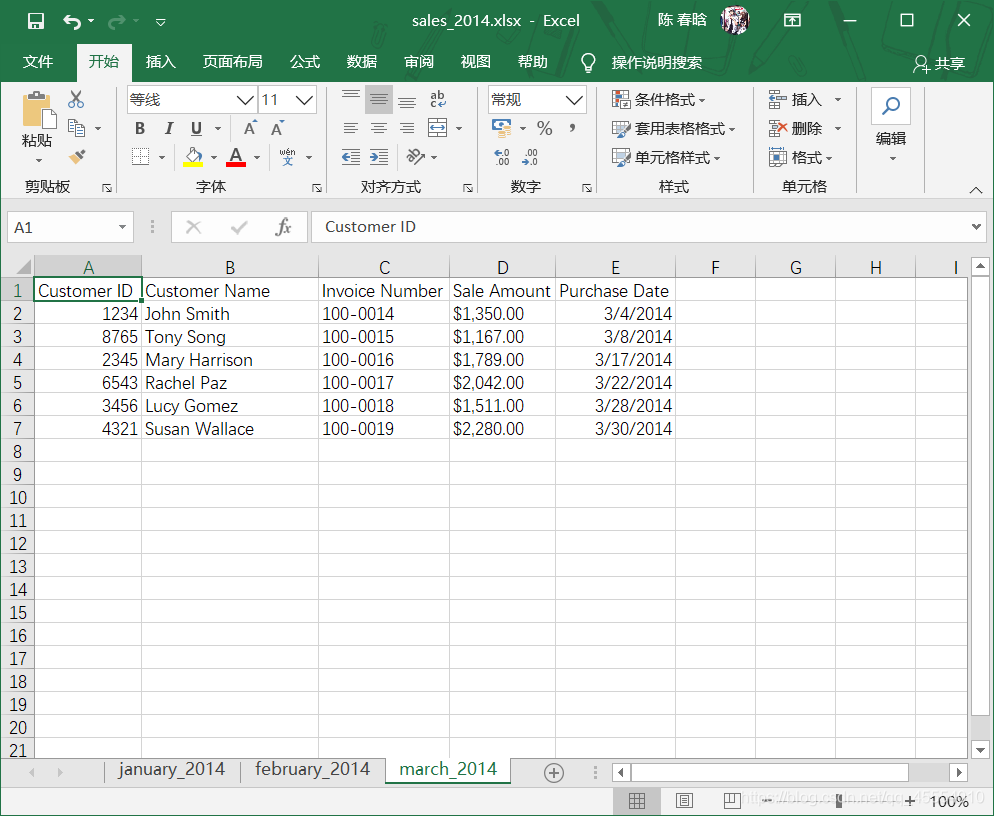
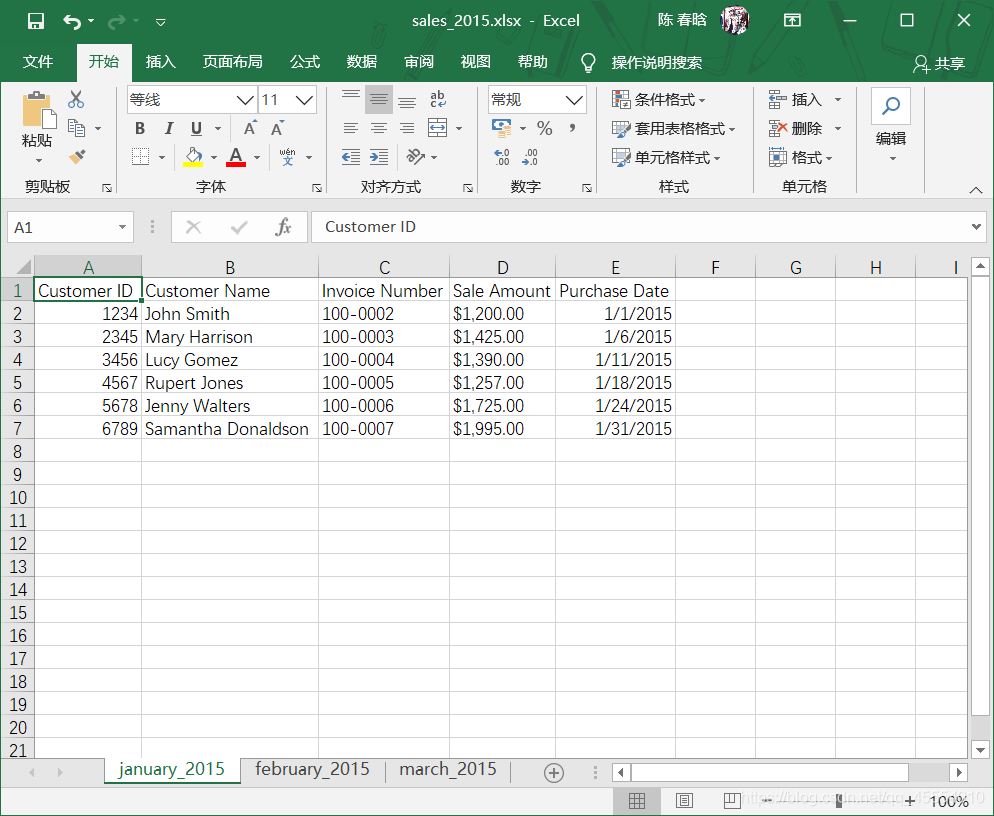
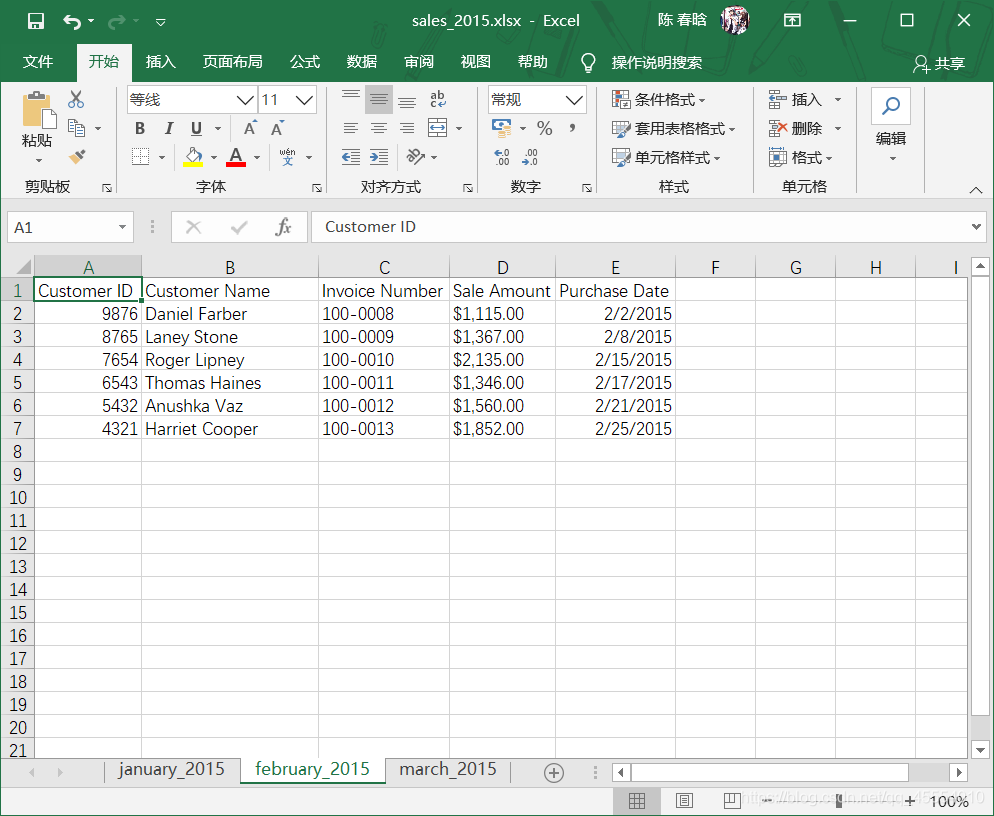
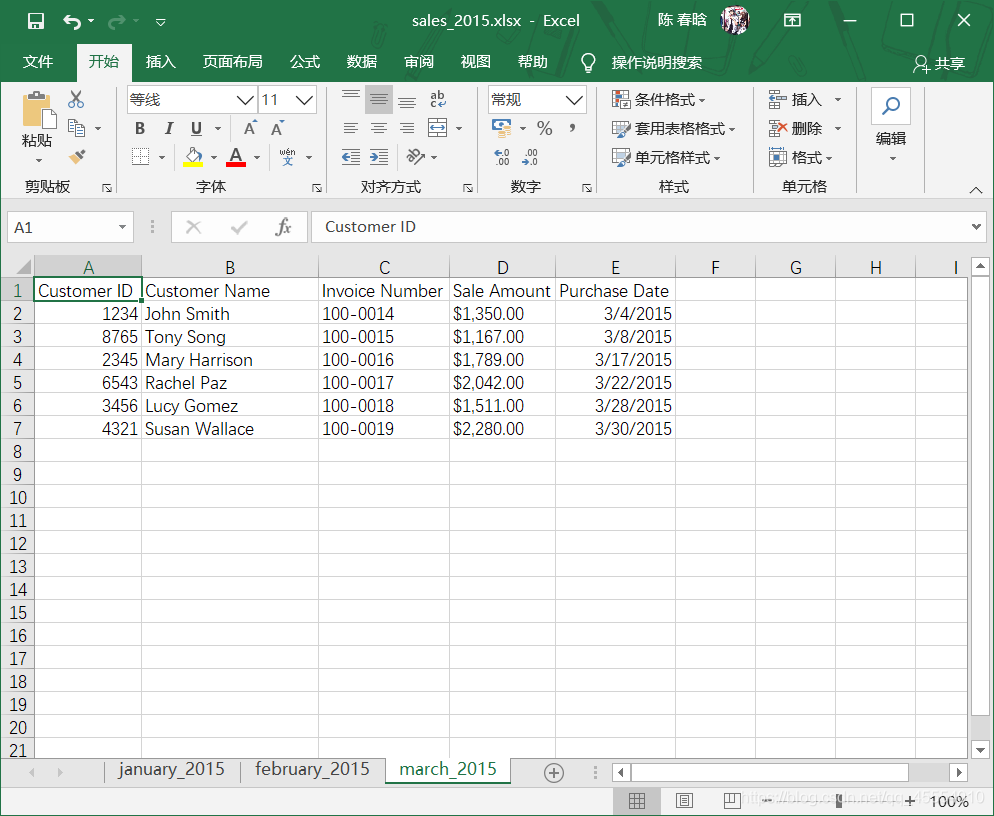
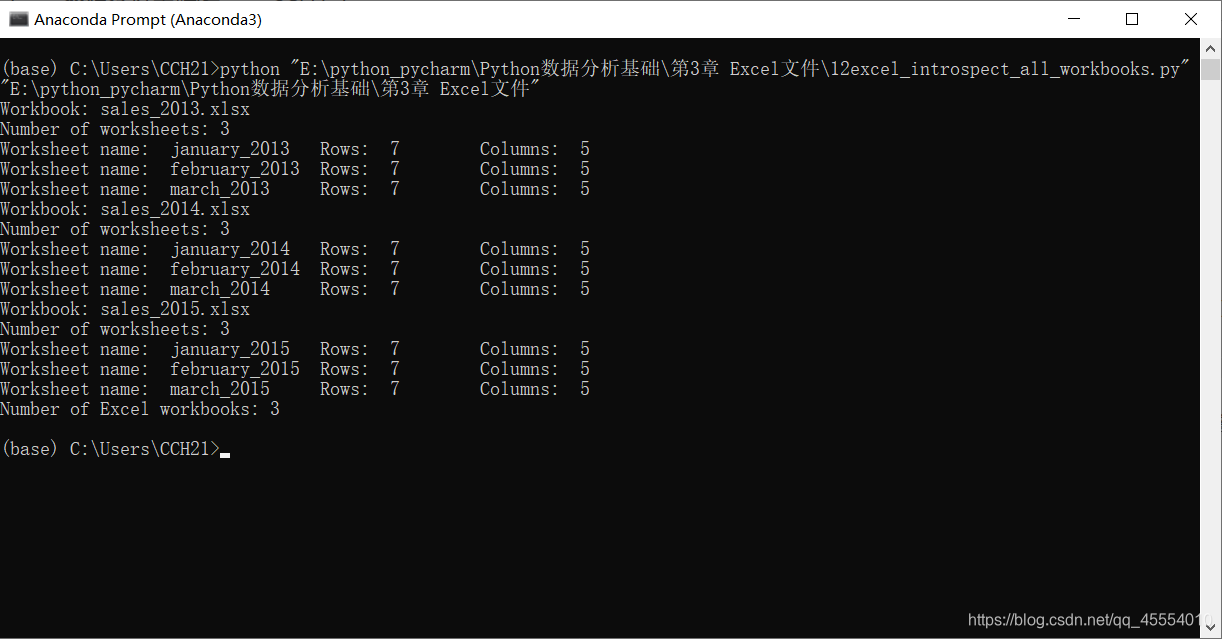
工作表计数以及每个工作表中的行列计数
如果想知道一个文件夹中工作簿的数量,每个工作簿中工作表的数量,以及每个工作表中的行与列的数量,我们可以编写下面的代码:
#!/usr/bin/env python3
import glob
import os
import sys
from xlrd import open_workbook
input_directory = sys.argv[1]
workbook_counter = 0
for input_file in glob.glob(os.path.join(input_directory, '*.xlsx')):
workbook = open_workbook(input_file)
print('Workbook: %s' % os.path.basename(input_file))
print('Number of worksheets: %d' % workbook.nsheets)
for worksheet in workbook.sheets():
print('Worksheet name: ', worksheet.name, '\tRows: ', worksheet.nrows, '\tColumns: ', worksheet.ncols)
workbook_counter += 1
print('Number of Excel workbooks: %d' % (workbook_counter))
这和之前的内省单个工作簿的代码非常相似。我们在命令行窗口中运行这个脚本,得到下面的输出结果。
从多个工作簿中连接数据
使用Python可以将多个工作簿中所有工作表的数据垂直连接成一个输出文件。
1.基础Python
代码如下:
#!/usr/bin/env python3
import glob
import os
import sys
from datetime import date
from xlrd import open_workbook, xldate_as_tuple
from xlwt import Workbook
input_folder = sys.argv[1]
output_file = sys.argv[2]
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('all_data_all_workbooks', cell_overwrite_ok=True)
data = []
first_worksheet = True
for input_file in glob.glob(os.path.join(input_folder, '*.xlsx')):
print(os.path.basename(input_file))
with open_workbook(input_file) as workbook:
for worksheet in workbook.sheets():
if first_worksheet:
header_row = worksheet.row_values(0)
data.append(header_row)
first_worksheet = False
for row_index in range(1, worksheet.nrows):
row_list = []
for column_index in range(worksheet.ncols):
cell_value = worksheet.cell_value(row_index, column_index)
cell_type = worksheet.cell_type(row_index, column_index)
if cell_type == 3:
date_cell = xldate_as_tuple(cell_value, workbook.datemode)
date_cell = date(*date_cell[0:3]).strftime('%m/%d/%Y')
row_list.append(date_cell)
else:
row_list.append(cell_value)
data.append(row_list)
for list_index, output_list in enumerate(data):
for element_index, element in enumerate(output_list):
output_worksheet.write(list_index, element_index, element)
output_workbook.save(output_file)
作者注:在第14行代码中,参考书上的代码并没有’cell_overwrite_ok=True’这一参数,这是我在写代码的时候报错后自己加上去的。
报错信息如下:
Traceback (most recent call last):
File “E:\python_pycharm\Python数据分析基础\第3章 Excel文件\13excel_concat_data_from_multiple_workbook.py”, line 39, in
output_worksheet.write(list_index, element_index, element)
File “D:\Anaconda3\lib\site-packages\xlwt\Worksheet.py”, line 1088, in write
self.row®.write(c, label, style)
File “D:\Anaconda3\lib\site-packages\xlwt\Row.py”, line 235, in write
StrCell(self.__idx, col, style_index, self.__parent_wb.add_str(label))
File “D:\Anaconda3\lib\site-packages\xlwt\Row.py”, line 154, in insert_cell
raise Exception(msg)
Exception: Attempt to overwrite cell: sheetname=‘all_data_all_workbooks’ rowx=0 colx=0
查阅有关资料后得知,对一个单元格重复操作会引发ReturnsError,这个时候只要在打开文件的时候加上’cell_overwrite_ok=True’即可解决。这应该是书本上的错误。
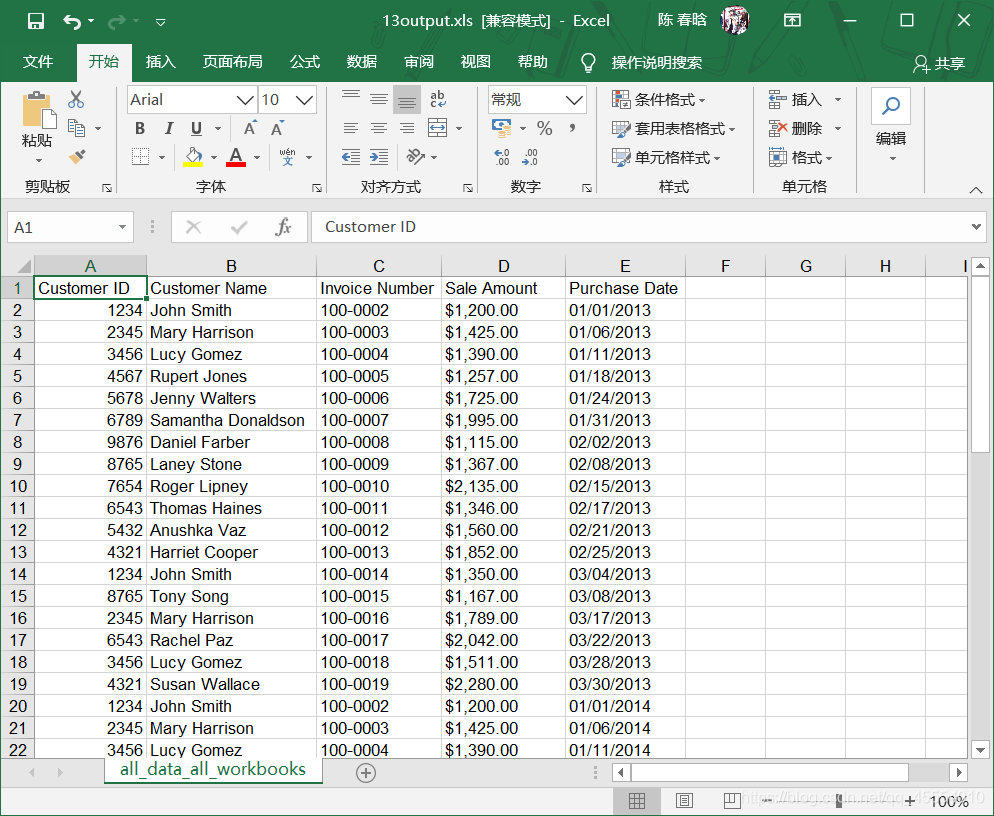
在命令行窗口中运行这个代码,得到输出文件。
2.pandas
pandas模块提供了concat()函数来连接数据框。如果想把数据框一个一个地垂直堆叠起来,需要设置参数axis=0;如果想把数据框一个一个地平行连接起来,需要设置参数axis=1。如果我们需要基于某个关键字列连接数据框,可以使用pandas模块的merge()函数。
使用pandas模块的代码如下:
#!/usr/bin/env python3
import pandas as pd
import glob
import os
import sys
input_path = sys.argv[1]
output_file = sys.argv[2]
all_workbooks = glob.glob(os.path.join(input_path, '*.xlsx'))
data_frames = []
for workbook in all_workbooks:
all_worksheets = pd.read_excel(workbook, sheet_name=None, index_col=None)
for worksheet_name, data in all_worksheets.items():
data_frames.append(data)
all_data_concatenated = pd.concat(data_frames, axis=0, ignore_index=True)
writer = pd.ExcelWriter(output_file)
all_data_concatenated.to_excel(writer, sheet_name='all_data_all_workbooks', index=False)
writer.save()
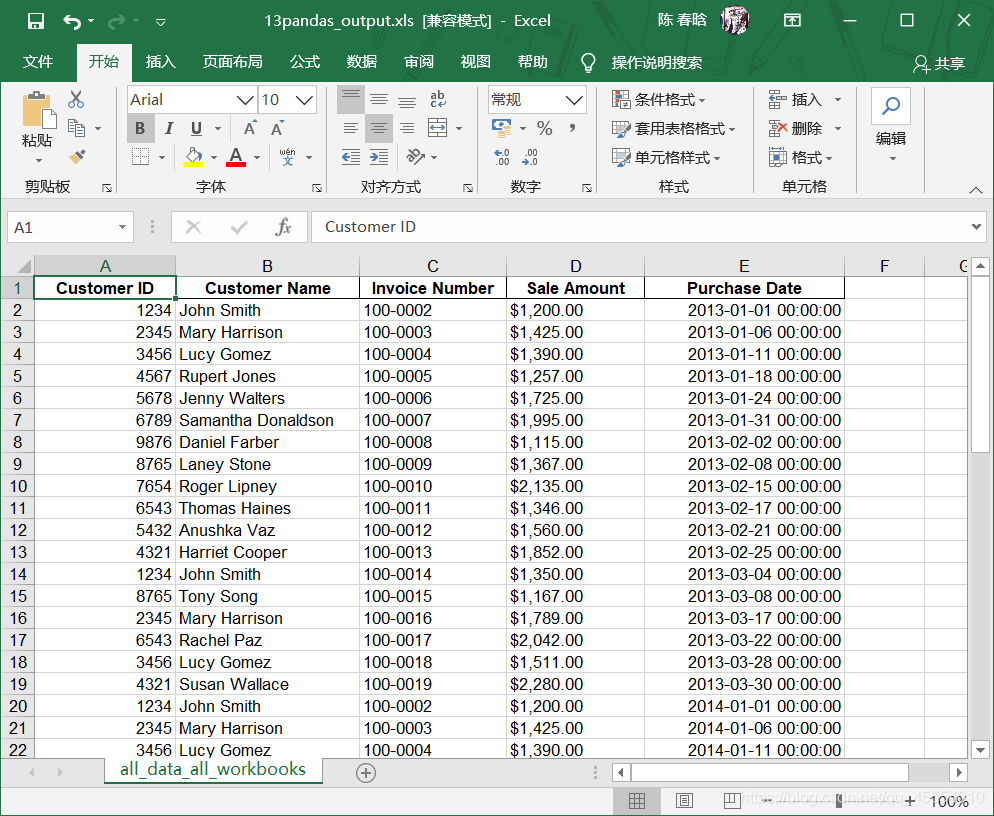
在命令行窗口中运行这个脚本,得到输出文件。
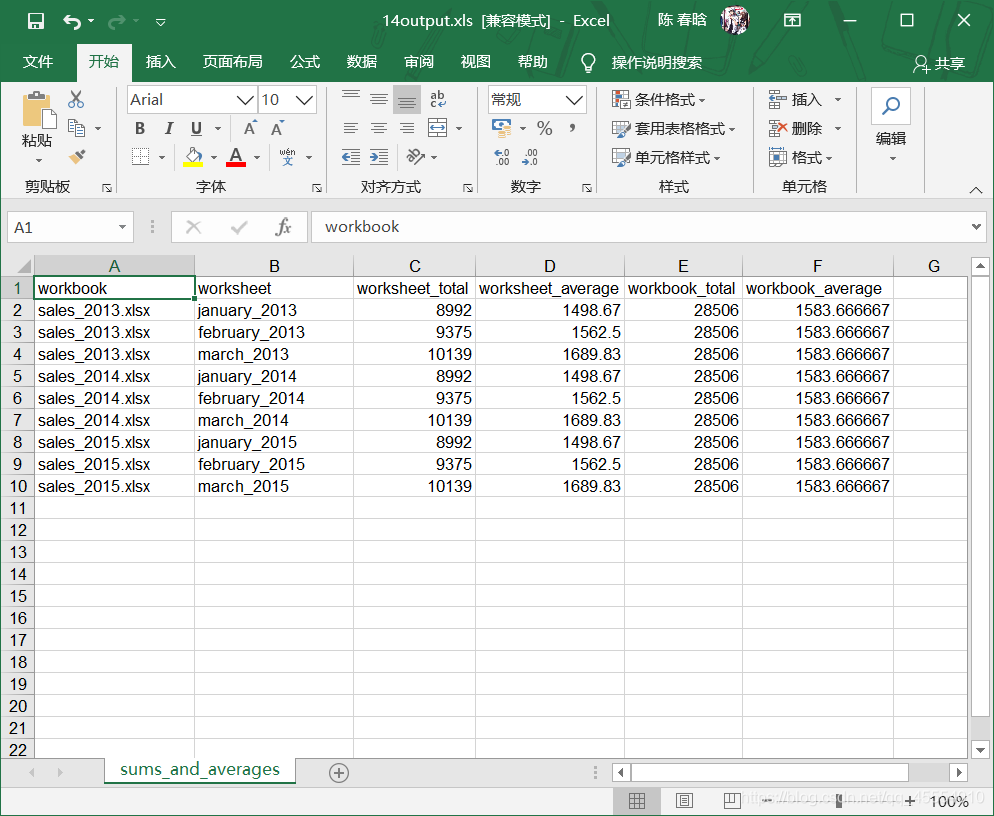
为每个工作簿和工作表计算总数和均值
基础Python
代码如下:
#!/usr/bin/env python3
import glob
import os
import sys
from datetime import date
from xlrd import open_workbook, xldate_as_tuple
from xlwt import Workbook
input_folder = sys.argv[1]
output_file = sys.argv[2]
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('sums_and_averages')
all_data = []
sales_column_index = 3
header = ['workbook', 'worksheet', 'worksheet_total', 'worksheet_average', 'workbook_total', 'workbook_average']
all_data.append(header)
for input_file in glob.glob(os.path.join(input_folder, '*.xlsx')):
with open_workbook(input_file) as workbook:
list_of_totals = []
list_of_numbers = []
workbook_output = []
for worksheet in workbook.sheets():
total_sales = 0
number_of_sales = 0
worksheet_list = []
worksheet_list.append(os.path.basename(input_file))
worksheet_list.append(worksheet.name)
for row_index in range(1, worksheet.nrows):
try:
total_sales += float(str(worksheet.cell_value(row_index, sales_column_index))
.strip('$').replace(',', ''))
number_of_sales += 1
except:
total_sales += 0
number_of_sales += 0
average_sales = '%.2f' % (total_sales / number_of_sales)
worksheet_list.append(total_sales)
worksheet_list.append(float(average_sales))
list_of_totals.append(total_sales)
list_of_numbers.append(float(number_of_sales))
workbook_output.append(worksheet_list)
workbook_total = sum(list_of_totals)
workbook_average = sum(list_of_totals) / sum(list_of_numbers)
for list_element in workbook_output:
list_element.append(workbook_total)
list_element.append(workbook_average)
all_data.extend(workbook_output)
for list_index, output_list in enumerate(all_data):
for element_index, element in enumerate(output_list):
output_worksheet.write(list_index, element_index, element)
output_workbook.save(output_file)
第21-23行分别创建了3个空列表,list_of_totals用来保存工作簿中所有工作表的销售额总计,list_of_numbers用来保存工作簿的所有工作表中用来计算总销售额的销售额数据个数,workbook_output用来保存要写入输出文件的所有输出列表。
第27行代码创建了列表worksheet_list,用来保存要保留的所有工作表的信息。
第28-29行代码将工作簿名称和工作表名称追加到worksheet_list中。同样地,第39-40行代码将销售额总计和均值追加到worksheet_list中,第43行代码将worksheet_list追加到workbook_output中,在工作簿级别保存信息。
第41-42行代码将工作表的销售额总计和销售额数据个数分别追加到list_of_totals和list_of_numbers中,这样我们可以对所有工作表保存这些值。
当获得了所有要为工作簿保留的信息之后,就将这些列表扩展到all_data中。这里使用extend()而不是append(),以使workbook_output中的每个列表都会成为all_data中的一个独立元素。在处理完所有工作簿之后,all_data是一个具有9个元素的列表,每个元素都是一个列表。否则,如果使用append(),all_data中就会只有3个元素,每个元素都是一个列表的列表。
在命令行窗口中运行这个脚本,得到输出文件。