以下链接是个人关于DenseFusion(6D姿态估计) 所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:a944284742相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。
姿态估计0-00:DenseFusion(6D姿态估计)-目录-史上最新无死角讲解https://blog.csdn.net/weixin_43013761/article/details/103053585
数据集讲解
通过前面,我们已经了解整个网络框架的训练流程,现在我们先来看看我们训练的数据集Linemod_preprocessed,本人存在如下上个子文件夹:

如果你的和我的长得不一样,那么抱歉,我也无能无力了。首先我们要了解的是,Linemod_preprocessed这个数据集中,一共用15种目标物体,首先我们来看看其中的data目录,如下:
分别对应十五个目标物体,随便既然一个文件夹,本人进入01如下:
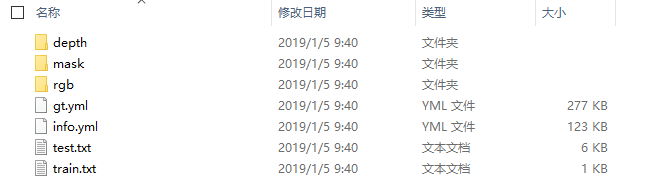
其中以及划分了验证和训练数据,保存的都是对应图片的索引,这样固定的划分好,是为了方便论文的复现。下面是对每个文件的总结:
1. depth(目录): 深度图
2. mask(目录):目标物体的掩码,为标准的分割结果
3. rgb(目录):保存为RGB图像
5. gt.yml(文件):保存了拍摄每张图片时,其对应的旋转矩阵和偏移矩阵,以及目标物体的标准box,
和该图像中目标物体所属于的类别
6. info.yml(文件):拍摄每张图像,对应的摄像头的内参,以及深度缩放的比例
这样,我们对于data已经了解完成了,我们再来看看Linemod_preprocessed/segnet_results,进入该文件如下:
其和Linemod_preprocessed/data/mask可以说时一一对应的,大小认真的对比下,发现他们对应的图片时相差无几的,那么这个又什么用?首先我们从名字来看,可以知道segnet_results时通过对目标物体进行语义分割得到的结果。再训练我们模型的时候,我们肯定希望时拿最标准的数据去训练我们的模型,所以训练和验证,都是使用最标准的mask(Linemod_preprocessed/data/mask),作为分割的标签。但是再测试的时候,是和应用场景达搭钩了,我们希望越接近实际场景越好,在实际场景中,DenseFusion网络是对分割出来的目标进行姿态预测,是的,是分割出来的物体,所以实际应用中,还需要一个分割网络。所以segnet_results中,保存的就是语义分割网络分割出来的图片,为了和实际场景更加接近,这也是倒是其和标准的/data/mask有点点区别的原因。
再下来我们就是介绍Linemod_preprocessed/models文件夹,进入如下:
这里的models可以理解为模型,是什么模型呢?那就是我们目标物体对应的模型,这些模型都用点云数据表示,并保存了起来。那么问题来了。在Linemod_preprocessed/data/xx/rgb中,有那么多的图像,这里的models是对应那个图像的模型呢? 进入obj_01.ply文件可以看到如下:
ply
format ascii 1.0
comment VCGLIB generated
element vertex 5841
property float x
property float y
property float z
property float nx
property float ny
property float nz
property uchar red
property uchar green
property uchar blue
property uchar alpha
element face 11678
property list uchar int vertex_indices
end_header
-23.0565 17.4191 -6.756 -0.617876 0.77406 -0.138061 148 57 57 255
-12.8773 -29.5554 -27.7156 -0.4007 -0.894836 0.196745 140 53 51 255
-32.2776 -17.7052 -32.4505 -0.813037 -0.537012 -0.224921 151 61 58 255
这些都是点云数据,简单的介绍可以参考如下连接:
https://blog.csdn.net/qq_36559293/article/details/90949295
可以想象得到,我们在对一个物体构建3D点云数据得时候,我们需要一个基准参考面,如果没有一个基准,我们拍摄多张照片,每个照片构建出来的点云数据都都不一样(那怕他们是同一个物体)。
所以Linemod_preprocessed\models中每个ply文件,其中的点云信息,都是以linemod\Linemod_preprocessed\data\xx\rgb\0000.png作为参考面的。有了这个参考面的点云数据(包含了整个目标的完整点云),我们就能根据其他的拍摄照片时的摄像头参数(旋转和偏移矩阵),计算出其他的视觉对应的点云数据了。
总的来说,我们对第一帧图片进行3D点云数据的建模(当然,整个过程需要多个面的图片-数据的制作过程),建模之后,我们对着目标随便拍摄一张图片,就能根据摄像头的参数,结合第一帧图片的3D点云数据,计算出该图片对应的3D点云数据了。
最后还有就是models_info.yml文件,其保存的是每个目标点云模型的半径,x,y,z轴的起始值和大小范围。
这样,我们对数据集的介绍就完成了。下面我们来看看对数据集的预处理过程
数据预处理
在tools/train.py中,我们可以看到如下:
PoseDataset_ycb()
PoseDataset_warehouse()
PoseDataset_linemod()
其都是对不同数据集的加载过程,对于本人要讲解的当然是PoseDataset_linemod,其代码的实现是在datasets/linemod/dataset.py:
import torch.utils.data as data
from PIL import Image
import os
import os.path
import errno
import torch
import json
import codecs
import numpy as np
import sys
import torchvision.transforms as transforms
import argparse
import json
import time
import random
import numpy
import numpy.ma as ma
import copy
import scipy.misc
import scipy.io as scio
import yaml
import cv2
numpy.set_printoptions(threshold= 1e6)
class PoseDataset(data.Dataset):
def __init__(self, mode, num, add_noise, root, noise_trans, refine):
"""
:param mode: 可以选择train,test,eval
:param num: mesh点的数目
:param add_noise:是否加入噪声
:param root:数据集的根目录
:param noise_trans:噪声增强的相关参数
:param refine:是否需要为refine模型提供相应的数据
"""
# 这里表示目标物体类别序列号
self.objlist = [1, 2, 4, 5, 6, 8, 9, 10, 11, 12, 13, 14, 15]
# 可以选择train,test,eval
self.mode = mode
# 存储RGB图像的路径
self.list_rgb = []
# 存储深度图像的路径
self.list_depth = []
# 存储语音分割出来物体对应的mask
self.list_label = []
# 两个拼接起来,可以知道每张图片的路径,及物体类别,和图片下标
self.list_obj = []
self.list_rank = []
# 矩阵信息,拍摄图片时的旋转矩阵和偏移矩阵,以及物体box
self.meta = {}
# 保存目标模型models点云数据,及models/obj_xx.ply文件中的数据
self.pt = {}
# 数据的所在的目录
self.root = root
# 噪声相关参数
self.noise_trans = noise_trans
self.refine = refine
item_count = 0
# 对每个目标物体的相关数据都进行处理
for item in self.objlist:
# 根据训练或者测试获得相应文件中的txt内容,其中保存的都是图片对应的名称数目
if self.mode == 'train':
input_file = open('{0}/data/{1}/train.txt'.format(self.root, '%02d' % item))
else:
input_file = open('{0}/data/{1}/test.txt'.format(self.root, '%02d' % item))
# 循环txt记录的每张图片进行处理
while 1:
# 记录处理的数目
item_count += 1
input_line = input_file.readline()
# test模式下,图片序列为10的倍数则continue
if self.mode == 'test' and item_count % 10 != 0:
continue
# 文件读取完成
if not input_line:
break
if input_line[-1:] == '\n':
input_line = input_line[:-1]
# 把RGB图像的路径加载到self.list_rgb列表中
self.list_rgb.append('{0}/data/{1}/rgb/{2}.png'.format(self.root, '%02d' % item, input_line))
# 把data/x/depth图像的路径加载到self.list_depth列表中
self.list_depth.append('{0}/data/{1}/depth/{2}.png'.format(self.root, '%02d' % item, input_line))
# 如果是评估模式,则添加segnet_results图片的mask,否则添加data中的mask图片(该为标准mask)
# 大家可以想想,训练的时候,肯定使用最标准的mask,但是在测试的时候,是要结合实际了,所以使用的
# 是通过分割网络分割出来的mask,即则添加segnet_results中的图片
if self.mode == 'eval':
self.list_label.append('{0}/segnet_results/{1}_label/{2}_label.png'.format(self.root, '%02d' % item, input_line))
else:
self.list_label.append('{0}/data/{1}/mask/{2}.png'.format(self.root, '%02d' % item, input_line))
# 把物体的下标,和txt读取到的图片数目标记分别添加到list_obj,list_rank中
self.list_obj.append(item)
self.list_rank.append(int(input_line))
# gt.yml主要保存的,是拍摄图片时,物体的旋转矩阵以及偏移矩阵,以及物体标签的box
# 有了该参数,我们就能把对应的图片,从2维空间恢复到3维空间了
meta_file = open('{0}/data/{1}/gt.yml'.format(self.root, '%02d' % item), 'r')
self.meta[item] = yaml.load(meta_file)
# 这里保存的是目标物体,拍摄物体第一帧的点云数据,可以成为模型数据
self.pt[item] = ply_vtx('{0}/models/obj_{1}.ply'.format(self.root, '%02d' % item))
print("Object {0} buffer loaded".format(item))
# 读取所有图片的路径,以及文件信息之后,打印图片数目
self.length = len(self.list_rgb)
# 摄像头的中中心坐标
self.cam_cx = 325.26110
self.cam_cy = 242.04899
# 摄像头的x,y轴的长度
self.cam_fx = 572.41140
self.cam_fy = 573.57043
# 列举处图片的x和y坐标
# xmap[480,640] ymap[480,640]
self.xmap = np.array([[j for i in range(640)] for j in range(480)])
#print(self.xmap.shape)
self.ymap = np.array([[i for i in range(640)] for j in range(480)])
# 设定获取目标物体点云的数据
self.num = num
self.add_noise = add_noise
self.trancolor = transforms.ColorJitter(0.2, 0.2, 0.2, 0.05)
self.norm = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
# 边界列表,可以想象把一个图片切割成了多个坐标
self.border_list = [-1, 40, 80, 120, 160, 200, 240, 280, 320, 360, 400, 440, 480, 520, 560, 600, 640, 680]
# 点云的最大和最小数目
self.num_pt_mesh_large = 500
self.num_pt_mesh_small = 500
# 标记对称物体的序列号
self.symmetry_obj_idx = [7, 8]
# 迭代的时候,会调用该函数
def __getitem__(self, index):
# 根据索引获得对应图像的RGB像素
img = Image.open(self.list_rgb[index])
#ori_img = np.array(img)
# 根据索引获得对应图像的深度图像素
depth = np.array(Image.open(self.list_depth[index]))
# 根据索引获得对应图像的mask像素
label = np.array(Image.open(self.list_label[index]))
# 获得物体属于的类别的序列号
obj = self.list_obj[index]
# 获得该张图片物体图像的下标
rank = self.list_rank[index]
# 如果该目标物体的序列为2,暂时不对序列为2的物体图像进行处理
if obj == 2:
# 对该物体的每个图片下标进行循环
for i in range(0, len(self.meta[obj][rank])):
# 验证该图片目标十分为2,如果是则赋值给meta
if self.meta[obj][rank][i]['obj_id'] == 2:
meta = self.meta[obj][rank][i]
break
# 如果目标物体的序列不为2,获得目标物体第一帧图片的旋转以及偏移矩阵
else:
meta = self.meta[obj][rank][0]
# 只要像素不为0的,返回值为Ture,如果为0的像素,还是返回False
mask_depth = ma.getmaskarray(ma.masked_not_equal(depth, 0))
#print(mask_depth)
# 标准的数据中的mask是3通道的,通过网络分割出来的mask,其是单通道的
if self.mode == 'eval':
mask_label = ma.getmaskarray(ma.masked_equal(label, np.array(255)))
else:
mask_label = ma.getmaskarray(ma.masked_equal(label, np.array([255, 255, 255])))[:, :, 0]
# 把mask和深度图结合到到一起,物体存在的区域像素为True,背景像素为False
mask = mask_label * mask_depth
# print('1='*50)
# print(mask.shape)
# print(mask)
# p_img = np.transpose(mask, (1, 2, 0))
# scipy.misc.imsave('evaluation_result/{0}_mask.png'.format(index), p_img)
# 对图像加入噪声
if self.add_noise:
img = self.trancolor(img)
# [b,h,w,c] --> [b,c,h,w]
img = np.array(img)[:, :, :3]
img = np.transpose(img, (2, 0, 1))
img_masked = img
# 如果为eval模式,根据mask_label获得目标的box(rmin-rmax表示行的位置,cmin-cmax表示列的位置)
if self.mode == 'eval':
# mask_to_bbox表示的根据mask生成合适的box
rmin, rmax, cmin, cmax = get_bbox(mask_to_bbox(mask_label))
# 如果不是eval模式,则从gt.yml文件中,获取最标准的box
else:
rmin, rmax, cmin, cmax = get_bbox(meta['obj_bb'])
# 根据确定的行和列,对图像进行截取,就是截取处包含了目标物体的图像
img_masked = img_masked[:, rmin:rmax, cmin:cmax]
#p_img = np.transpose(img_masked, (1, 2, 0))
#scipy.misc.imsave('evaluation_result/{0}_input.png'.format(index), p_img)
# 获得目标物体旋转矩阵的参数,以及偏移矩阵参数
target_r = np.resize(np.array(meta['cam_R_m2c']), (3, 3))
target_t = np.array(meta['cam_t_m2c'])
# 对偏移矩阵添加噪声
add_t = np.array([random.uniform(-self.noise_trans, self.noise_trans) for i in range(3)])
# 对mask图片的目标部分进行剪裁,变成拉平,变成一维
choose = mask[rmin:rmax, cmin:cmax].flatten().nonzero()[0]
# print('2='*50)
# print(choose.shape)
# print(choose)
# 如果剪切下来的部分面积为0,则直接返回五个0的元组,即表示没有目标物体
if len(choose) == 0:
cc = torch.LongTensor([0])
return(cc, cc, cc, cc, cc, cc)
# 如果剪切下来目标图片的像素,大于了点云的数目(一般都是这种情况)
if len(choose) > self.num:
# c_mask全部设置为0,大小和choose相同
c_mask = np.zeros(len(choose), dtype=int)
# 前self.num设置为1
c_mask[:self.num] = 1
# 随机打乱
np.random.shuffle(c_mask)
# 选择c_mask不是0的部分,也就是说,只选择了500个像素,注意nonzero()返回的是索引
choose = choose[c_mask.nonzero()]
# 如果剪切像素点的数目,小于了点云的数目
else:
# 这使用0填补,调整到和点云数目一样大小(500)
choose = np.pad(choose, (0, self.num - len(choose)), 'wrap')
# 得到的choose输出为(500,)这里保存的,是挑选出来的500个索引
#print(choose.shape)
#print(choose)
# 把深度图,对应着物体的部分也剪切下来,然后拉平,变成一维,挑选坐标
depth_masked = depth[rmin:rmax, cmin:cmax].flatten()[choose][:, np.newaxis].astype(np.float32)
# 把物体存在于原图的位置坐标剪切下来,拉平,然后进行挑选坐标挑选
xmap_masked = self.xmap[rmin:rmax, cmin:cmax].flatten()[choose][:, np.newaxis].astype(np.float32)
ymap_masked = self.ymap[rmin:rmax, cmin:cmax].flatten()[choose][:, np.newaxis].astype(np.float32)
choose = np.array([choose])
# 摄像头缩放参数
cam_scale = 1.0
pt2 = depth_masked / cam_scale
# 为对坐标进行正则化做准备
pt0 = (ymap_masked - self.cam_cx) * pt2 / self.cam_fx
pt1 = (xmap_masked - self.cam_cy) * pt2 / self.cam_fy
# 把y,x,depth他们3个坐标合并在一起,变成点云数据,
cloud = np.concatenate((pt0, pt1, pt2), axis=1)
#print(cloud)
# 这里把点云数据除以1000,是为了根据深度进行正则化
cloud = cloud / 1000.0
#print(cloud)
# 对点云添加噪声
if self.add_noise:
cloud = np.add(cloud, add_t)
#fw = open('evaluation_result/{0}_cld.xyz'.format(index), 'w')
#for it in cloud:
# fw.write('{0} {1} {2}\n'.format(it[0], it[1], it[2]))
#fw.close()
# 存储在obj_xx.ply中的点云数据,对其进行正则化,也就是目标物体的点云信息
model_points = self.pt[obj] / 1000.0
# 随机删除多余的点云数据,训练时,只需要num_pt_mesh_small数目的点云
dellist = [j for j in range(0, len(model_points))]
dellist = random.sample(dellist, len(model_points) - self.num_pt_mesh_small)
model_points = np.delete(model_points, dellist, axis=0)
#fw = open('evaluation_result/{0}_model_points.xyz'.format(index), 'w')
#for it in model_points:
# fw.write('{0} {1} {2}\n'.format(it[0], it[1], it[2]))
#fw.close()
# 根据model_points(第一帧目标模型对应的点云信息),以及target(目前迭代这张图片)的旋转和偏移矩阵,计算出对应的点云数据
target = np.dot(model_points, target_r.T)
if self.add_noise:
target = np.add(target, target_t / 1000.0 + add_t)
out_t = target_t / 1000.0 + add_t
else:
target = np.add(target, target_t / 1000.0)
out_t = target_t / 1000.0
#fw = open('evaluation_result/{0}_tar.xyz'.format(index), 'w')
#for it in target:
# fw.write('{0} {1} {2}\n'.format(it[0], it[1], it[2]))
#fw.close()
# 总结:
# cloud:由深度图计算出来的点云,该点云数据以本摄像头为参考坐标
# choose:所选择点云的索引
# img_masked:通过box剪切下来的RGB图像
# target:根据model_points点云信息,以及旋转偏移矩阵转换过的点云信息
# model_points:目标初始帧(模型)对应的点云信息
# [self.objlist.index(obj)]:目标物体的序列编号
return torch.from_numpy(cloud.astype(np.float32)), \
torch.LongTensor(choose.astype(np.int32)), \
self.norm(torch.from_numpy(img_masked.astype(np.float32))), \
torch.from_numpy(target.astype(np.float32)), \
torch.from_numpy(model_points.astype(np.float32)), \
torch.LongTensor([self.objlist.index(obj)])
def __len__(self):
return self.length
def get_sym_list(self):
return self.symmetry_obj_idx
def get_num_points_mesh(self):
if self.refine:
return self.num_pt_mesh_large
else:
return self.num_pt_mesh_small
border_list = [-1, 40, 80, 120, 160, 200, 240, 280, 320, 360, 400, 440, 480, 520, 560, 600, 640, 680]
img_width = 480
img_length = 640
def mask_to_bbox(mask):
mask = mask.astype(np.uint8)
#_, contours, _ = cv2.findContours(mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
contours, _ = cv2.findContours(mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
x = 0
y = 0
w = 0
h = 0
for contour in contours:
tmp_x, tmp_y, tmp_w, tmp_h = cv2.boundingRect(contour)
if tmp_w * tmp_h > w * h:
x = tmp_x
y = tmp_y
w = tmp_w
h = tmp_h
return [x, y, w, h]
def get_bbox(bbox):
bbx = [bbox[1], bbox[1] + bbox[3], bbox[0], bbox[0] + bbox[2]]
if bbx[0] < 0:
bbx[0] = 0
if bbx[1] >= 480:
bbx[1] = 479
if bbx[2] < 0:
bbx[2] = 0
if bbx[3] >= 640:
bbx[3] = 639
rmin, rmax, cmin, cmax = bbx[0], bbx[1], bbx[2], bbx[3]
r_b = rmax - rmin
for tt in range(len(border_list)):
if r_b > border_list[tt] and r_b < border_list[tt + 1]:
r_b = border_list[tt + 1]
break
c_b = cmax - cmin
for tt in range(len(border_list)):
if c_b > border_list[tt] and c_b < border_list[tt + 1]:
c_b = border_list[tt + 1]
break
center = [int((rmin + rmax) / 2), int((cmin + cmax) / 2)]
rmin = center[0] - int(r_b / 2)
rmax = center[0] + int(r_b / 2)
cmin = center[1] - int(c_b / 2)
cmax = center[1] + int(c_b / 2)
if rmin < 0:
delt = -rmin
rmin = 0
rmax += delt
if cmin < 0:
delt = -cmin
cmin = 0
cmax += delt
if rmax > 480:
delt = rmax - 480
rmax = 480
rmin -= delt
if cmax > 640:
delt = cmax - 640
cmax = 640
cmin -= delt
return rmin, rmax, cmin, cmax
def ply_vtx(path):
f = open(path)
assert f.readline().strip() == "ply"
f.readline()
f.readline()
N = int(f.readline().split()[-1])
while f.readline().strip() != "end_header":
continue
pts = []
for _ in range(N):
pts.append(np.float32(f.readline().split()[:3]))
return np.array(pts)
我相信,注释已经很详细,我们回到tools/train.py:
points, choose, img, target, model_points, idx = data
# points:由深度图计算出来的点云,该点云数据以摄像头为参考坐标
# choose:所选择点云的索引,
# img:通过box剪切下来的RGB图像
# target:根据model_points点云信息,以及旋转偏移矩阵转换过的点云信息
# model_points:目标初始帧(模型)对应的点云信息
# idx:目标物体的序列编号
其上可以说,就是对整个数据加载,以及预测处理的目的了。
细心的朋友应该发现了,修改batch_size参数,似乎没有什么用,其主要的原因是torch.utils.data.DataLoader()函数的参数batch_size=1设置为1,集每次都是获得一个样本,如果强行修改为其他的整数(如本人修改为2),会报错如下:
taloader.py", line 209, in default_collate
return torch.stack(batch, 0, out=out)
RuntimeError: invalid argument 0: Sizes of tensors must match except in dimension 0. Got 160 and 120 in dimension 2 at /pytorch/aten/src/TH/generic/THTensorMoreMath.cpp:1307
大概的原因就是,对于每个我们分割出来的目标图像,其大小都是不一样的,所以我们只能一张一张的去进行训练。多个图片大小不一样的图像,没有办法统一成一个batch。
