以下链接是个人关于DenseFusion(6D姿态估计) 所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:a944284742相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。
姿态估计0-00:DenseFusion(6D姿态估计)-目录-史上最新无死角讲解https://blog.csdn.net/weixin_43013761/article/details/103053585
代码引导
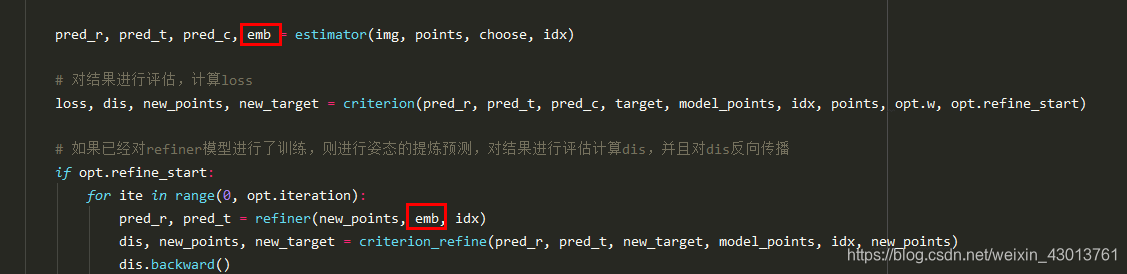
没有办法,还是得把代码贴上来一下tools/train.py:
# 进行预测获得,获得预测的姿态,姿态预测之前的特征向量
# pred_r: 预测的旋转参数[bs, 500, 4]
# pred_t: 预测的偏移参数[bs, 500, 3]
# pred_c: 预测的置信度[bs, 500, 1],置信度
#
pred_r, pred_t, pred_c, emb = estimator(img, points, choose, idx)
# 对结果进行评估,计算loss
loss, dis, new_points, new_target = criterion(pred_r, pred_t, pred_c, target, model_points, idx, points, opt.w, opt.refine_start)
# 如果已经对refiner模型进行了训练,则进行姿态的提炼预测,对结果进行评估计算dis,并且对dis反向传播
if opt.refine_start:
for ite in range(0, opt.iteration):
pred_r, pred_t = refiner(new_points, emb, idx)
dis, new_points, new_target = criterion_refine(pred_r, pred_t, new_target, model_points, idx, new_points)
dis.backward()
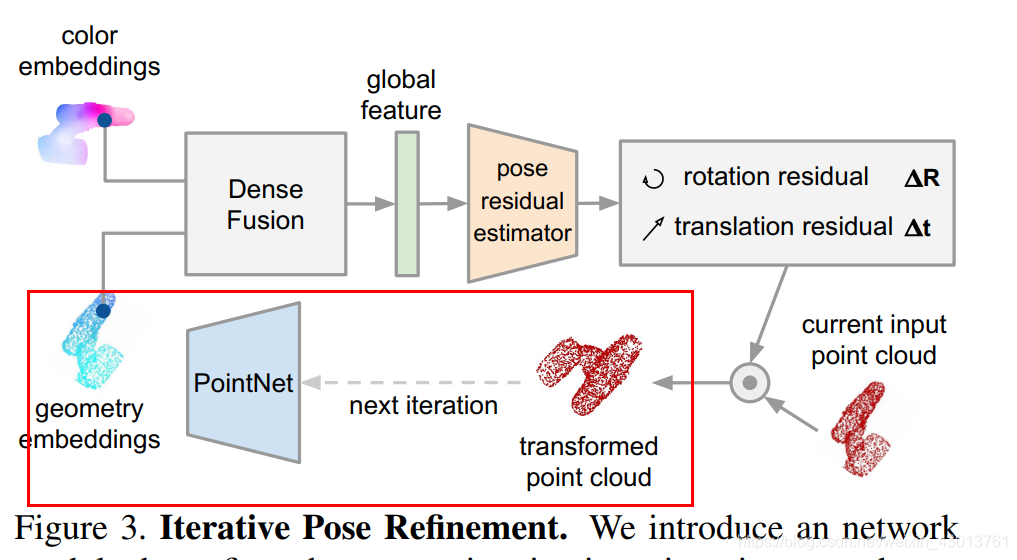
该篇博客,主要是对上面的refiner以及criterion_refine进行讲解,还是按顺序来,我们来看看refiner,假设这是第一执行refiner,那么其输入的new_points,emb来自于criterion函数的返回值。如果看了上篇博客,criterion返回的new_points,是经过逆转之后的points,如果看了前面的博客,可以知道这里的new_points相当于是points转换到相机的空间。其实这里可以理解为论文图示Figure 3的如下部分:
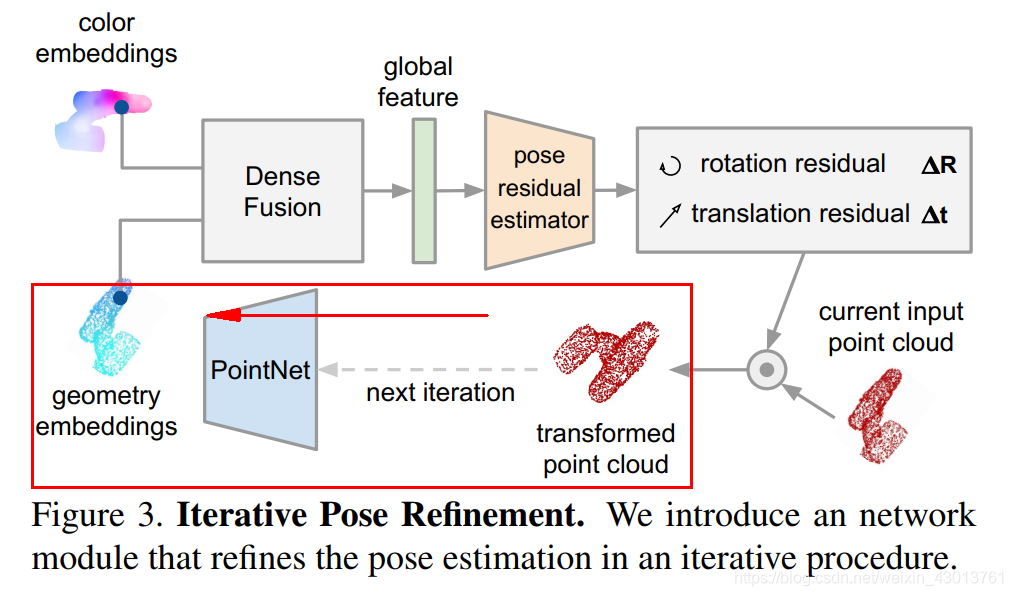
其中的points你可以理解(仅仅是理解,实际不是这样的)为下图:
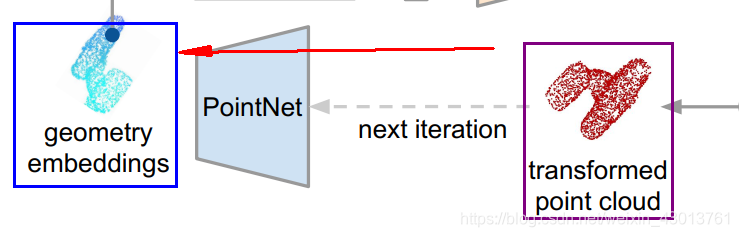
中的transformed point cloud,然后呢,通过逆转,变成geometry embeddings = 代码中的new_points。现在呢我们拿到了geometry embeddings(new_points=空间信息),从图示中,我们可以知道,其还需要一个color embeddings(颜色信息),才能进行融合,如下:
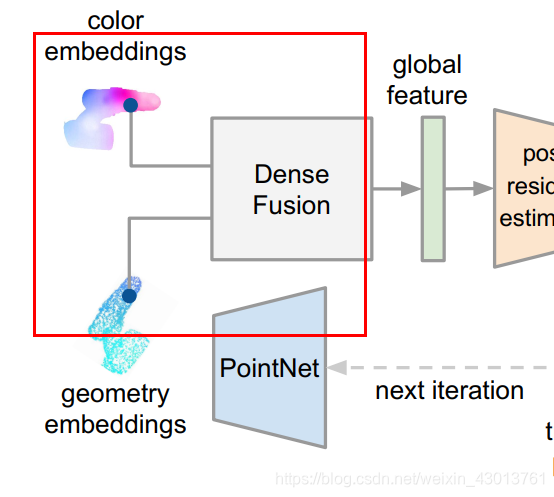
这里的颜色信息从哪里来呢?他是由主干网络从当前特征抽取出来的color embeddings,也就是相当于源码中如下标记:
可以明确的看到,在迭代过程中emb一直都是从主干网络PoseNet抽取出来的color embeddings,没有做任何的改变,也符合了论文中的描述。但是这里的color embeddings也还是带有一些空间信息的,他的空间信息就是当前帧的空间信息。
前面说到new_points是points逆转之后的结果,但是color embeddings带有的少量空间信息是当前帧的(接近于points),所以出现了如下图示现象:
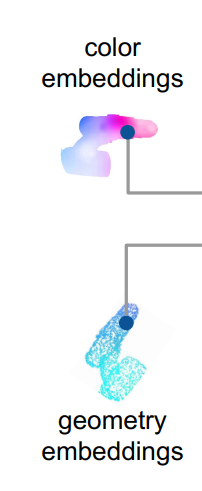
可以明显的看到,他们空间几何信息是不一样的。color embeddings=emb,geometry embeddings=new_points。他们既然空间信息不一样,那么我们就能对他进行pose的预测,对应论文图示如下部分:
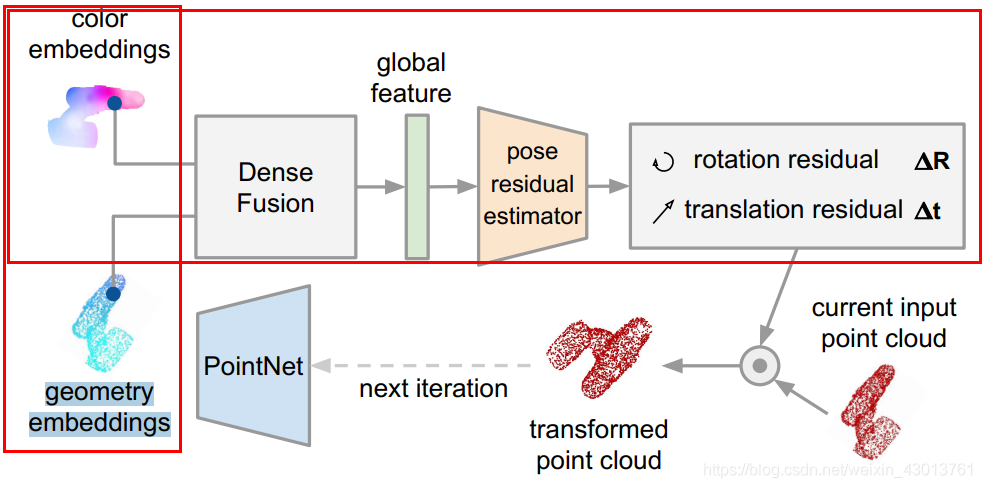
可以看到color embeddings=emb(源码),geometry embeddings=new_points(源码)被送入了一个网络,然后进行姿态估算,也就是如下函数:
pred_r, pred_t = refiner(new_points, emb, idx)
得到新的估算姿态之后,他又和new_points(图示的current input point cloud)结合,把new_points进行偏转。本来new_points是points逆转过来的,又被偏转了回去,相当于又回到points状态,那么代码是怎么体现的呢?我们进入到criterion_refine函数,也就是lib/loss_refiner.py中的loss_calculation。我就不注释了啊 ,代码基本和lib/loss.py中的一样的,可以说是一个阉割的版本。如下代码
pred = torch.add(torch.bmm(model_points, base), pred_t)
就是一个转换的过程,对应图示如下部分:
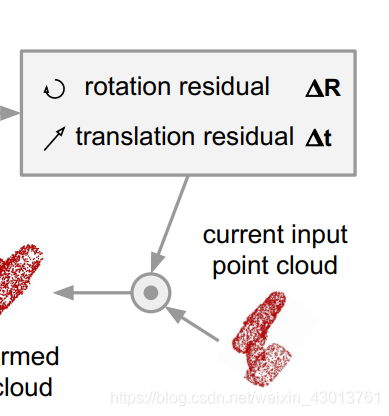
前面说到,转换过去之后,还需要一个逆转的过程,如下代码:
ori_base = ori_base[0].view(1, 3, 3).contiguous()
ori_t = t.repeat(bs * num_input_points, 1).contiguous().view(1, bs * num_input_points, 3)
new_points = torch.bmm((points - ori_t), ori_base).contiguous()
new_target = ori_target[0].view(1, num_point_mesh, 3).contiguous()
ori_t = t.repeat(num_point_mesh, 1).contiguous().view(1, num_point_mesh, 3)
new_target = torch.bmm((new_target - ori_t), ori_base).contiguous()
根据我们前面对代码的解析,看到- ori_t,我们就知道这是一个逆转的过程了。也就是图示如下部分:
这样,是不是带着大家走完一次迭代了。后续的迭代也是同样的原理。还又就是对其的理解了。上一篇博客中,其实已经举了一个很形象的例子。中的来说,就是说主干网络初始估算的pose,是存在误差的,这些误差的原因呢,要么就是语义分割做的不好(如切割下来的掺杂着背景),要么,存在遮挡现象等一系列的原因。为了进行减少这个误差,所以构建了Iterative Pose Refinement,通过多次迭代之后,用新估算出来的姿态,取弥补这些误差。
其实,这个地方比较抽象,不懂的朋友可以点个赞,然后来找我讨论,随时都欢迎。再见了,看到这里的你,应该也不容易,一路辛苦了。
