
背景
该论文发表于2018年CVPR,解决的问题是:给定单幅RGB图像,估计图像中包含目标物体的6DoF位姿;6DoF位姿包括了3维位置和3维空间朝向;传统方法包括以下两种:基于RGB图像的方法,或者使用edge特征,但对复杂背景敏感,或者使用feature points,但无法处理弱纹理或者无纹理情况;基于RGB-D的方法,依赖传感器,本身有一定限制。近年来深度学习的方法,可以给6DoF位姿估计,带来极大的效果提升。
算法概述
该论文设计了一个端到端可训练的网络,实时预测物体的6DoF位姿;受到2D物体检测算法YOLO的启发设计CNN网络,预测物体3D包围盒顶点的2D投影点;YOLO只预测出2D包围盒,而该论文预测更多的2D投影点;之后给定这些2D投影点对应的3D点,可以通过PnP算法估计物体的6DoF位姿。
算法框架
首先将每个物体的3D模型用9个控制点表示,分别是外切包围盒的8个顶点以及3D模型的重心,这样训练时只需要知道物体的3D包围盒,而不需要确切的网格模型以及附带的纹理图;算法输入为一个单幅完整的彩色图像,如图1(b);使用图1(a)的卷积网络将图像划分成SxS的Cell,如图1 ;网络的输出结果图1(d)用SxSxD的张量表示,如图1(e),D的维度为(9x2+C+1),分别包含了9个2D投影点坐标 ,C个类别概率,以及一个置信值。如果某一个Cell的置信值较低,则删除该Cell。
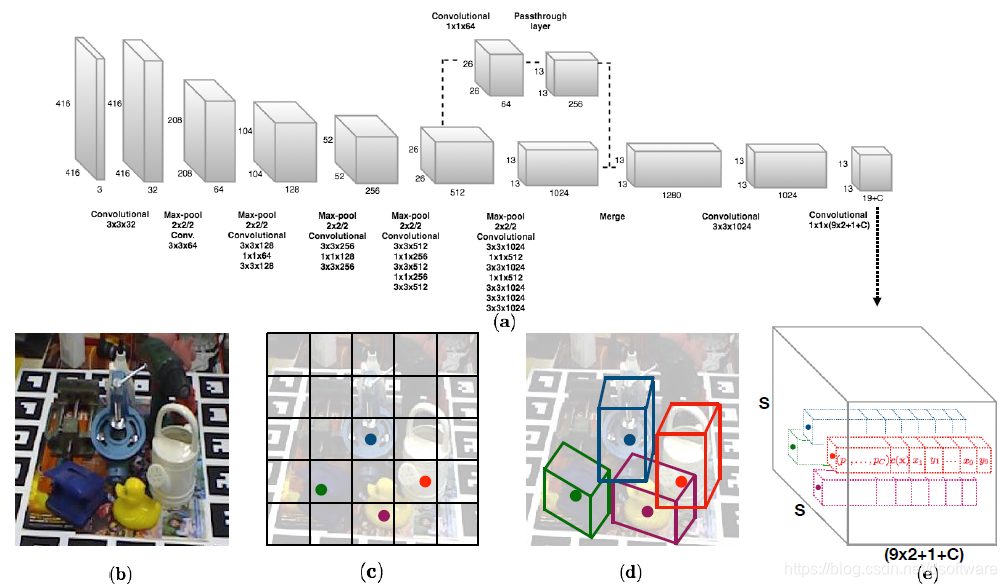
置信函数设计:
依据图像空间的2D欧氏距离,计算预测的2D投影点和真值点的平均偏差。

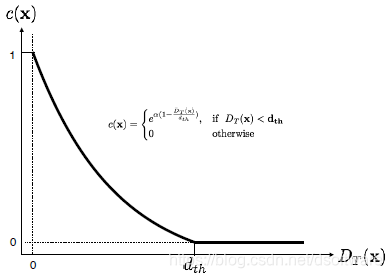
令 代表估计的2D位置和真值位置之间的欧氏距离,则置信函数 和 的关系如下图所示,距离越大置信越低。
训练过程
训练时,置信值根据预测的2D投影点和真值2D投影点之间的
,依据公式(1)在线计算;依据网格cell的左上顶点
计算offsets。对于重心,offset设置为[0,1],对于顶点,预测的
设置为:
,
,这里
选择1D的sigmoid函数;这样设置保证了网络首先选择近似的cell位置,其后再估计8个顶点位置。最终,整个网络的损失函数设置为如下:
其中
,
分别是坐标损失,置信损失,使用均方差算法,
是分类损失,使用交叉熵。对于权重,如果包含物体,
设置为5.0,不包含物体设置为0.1;对于每个cell,最多允许包含5个物体。
实现细节
- 在ImageNet的分类任务数据集上训练初始网络初始化参数;
- 对包含物体的cell设置λ_conf为5,不包含物体的cell设置λ_conf为0.1;
- 设置置信函数的锐度α为2,距离阈值为30pixels;
- 训练集图像随机按照像素大小的20%进行尺度放缩和平移;
实验
数据集
- LineMod,这是在杂乱环境中估计无纹理物体6DoF姿态的Benchmark;每一个RGB图像中的物体都赋予了一个真值的旋转、平移以及ID,也提供了完整的3D网格;
- OCCULUSION,这是进行多物体检测和姿态估计的数据集,对LineMod数据集的子集进行了额外的标注;
评价度量
- 2D重投影误差:将物体3D模型点根据估计位姿,以及真值位姿,分别投影到2D图像;如果所有点的平均偏差在5个pixel以内,则认为位姿估计正确;
- 平均模型点的3D距离(ADD):将估计位姿下的3D模型点和真值位姿下的3D模型点,计算平均距离偏差,如果偏差小于物体直径的10%,则认为位姿估计正确;
- IOU(Intersection over union,并交比)评分:计算3D模型根据估计位姿,以真值位姿,分别投影到2D图像区域的并交比,如果重叠大于0.5,则认为位姿正确;
结果
和已有算法在三种度量上均得到了精度和速度的提升,具体定量比较结果见论文。这里只给出定性结果,如下图所示,一至四列分别给出了杂乱背景,遮挡以及朝向模糊情况下的结果。最后一列给出了由于运动模糊、极度遮挡和镜面反射情况下的失败情况。

总结
- 提出了一种新的CNN框架,快速准确地预测6DoF位姿,自然地将2D物体检测框架扩展到3D物体检测;
- 提出的算法不需要后处理,而现存的基于CNN的6D物体检测算法都需要后处理以优化位姿;
- 算法实时,在Titan X GPU上能够达到50-94fps,根据图像分辨率而定;
声明:本文中所有图片均引自改论文。本解读只讲述核心观点,如需深入了解,可阅读原始论文。如有问题,请随时交流,如有错误,请随时指正。