以下链接是个人关于DenseFusion(6D姿态估计) 所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:a944284742相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。
姿态估计0-00:DenseFusion(6D姿态估计)-目录-史上最新无死角讲解https://blog.csdn.net/weixin_43013761/article/details/103053585
话不多说,我们继续论文翻译
4. Experiments
实验做了如下内容:
1.稠密(像素/点云级别)融合和全部融合做比较。
2.稠密融合估算对语义分割偏差以及重度遮挡的鲁棒性怎么样?
3.我们提出的iterative refinement module(迭代优化提炼模型)是否对初始估算的姿态心进行了优化
4.该方法是否能够让机器人进行实时的抓取物体任务
为了回答第一个问题,我们再YCB-Video数据集和 LineMOD数据集上做了实验,YCB-Video数据集包含了各种形状,纹理,遮挡程度不一样的数据,所以用它来测试我们的模型是是否合适的。LineMOD数据集是当前比较流行的评估数据集,方便我们和其他的算法进行比较,我们再该数据集上对比了当前最先进的算法,以及该些算法的变体。最后,我们做了一个机器人抓取实验。
4.1. Datasets
YCB-Video Dataset. 一起有21个类别的物体,共92个RGB-D视频,每个视频都是不同的室内场景。这是视频都有6D姿态的注释,我们使用了80个视频进行训练,12个作为测试。在使用了ICP的算法进行了比较。
LineMOD Dataset. 一起13个物体类别,在这里我们和传统的方法做了比较,和带有ICP最先进的方法做了比较。
4.2. Metrics
在 YCB-Video 数据集,使用了两个评估标准:
1.点云之间的平局距离average closest point distance(ADD-S),他分别考虑的对称和不对称物体的评估。通过估算的姿态
和ground truth pose
,ADD-S会计算由他们转换之后,对应点云之间的距离,然后取得平均值。然后我们求得了其AUC曲线,AUC得最大阈值设定为0.1m,
2.同时也做了低于2cm的实验。对于机器人抓取物体,能容忍的最大误差值就是2cm。
在 LineMOD数据集,使用ADD标准评估不对称的物体,ADD-S评估对称的物体。
4.3. Implementation Details
rgb_img特征的抽取(抽取颜色信息)是一个18层的编码解码网络,4个上采样作为解码过程。PointNe架构在全连接层之后跟随着average-pooling作为reduction function。color和geometric特征融合之后的特征向量是128维的,其中的超参数 。经过试验证明,对于refinement module 使用4个全连接层,连接起来对姿态进行评估效果比较好。所有的实验中,我们都使用了两次迭代进行优化提炼
4.4. Architectures
我们对DenseFusion进行了研究,出现了几个变体,去找到最合适的搭配。
1.PointFusion通过连接image feature以及geometry featur得到一个固定尺寸的feature,其余的架构和我们的都是相似的.
2.Ours (single):使用了稠密融合的方法,但是没有使用稠密(点云级别)的姿态估算,直接使用一个global feature,进行了一次姿态估算。
3.Ours (per-pixel):使用稠密融合,也使用稠密姿态估算。
4.Ours (iterative) :在Ours (per-pixel)的基础下,使用iterative refinement 。
4.5. Evaluation on YCB-Video Dataset
下面是上面的方法,在YCB-Video数据集上的评估结果
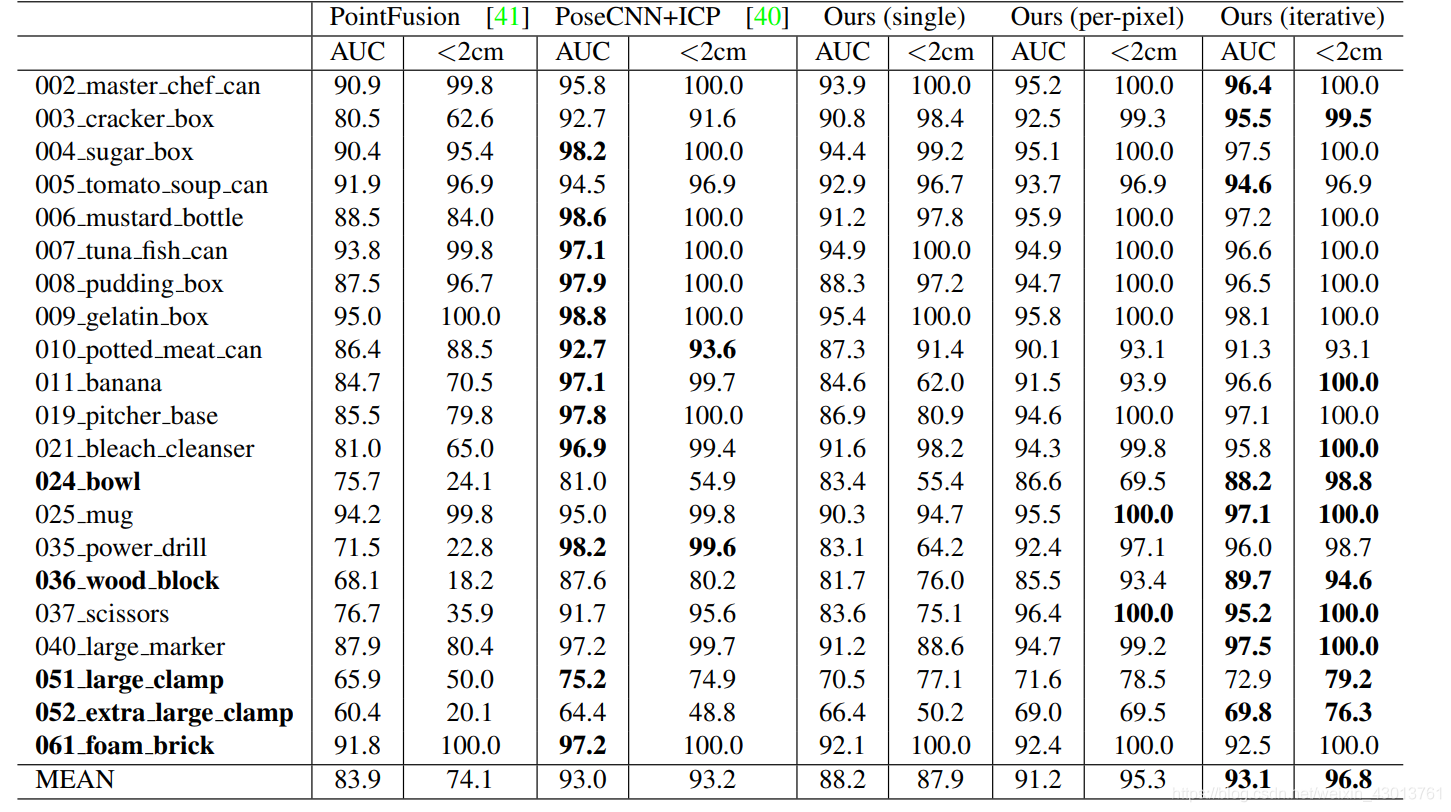
其中第一列表示的是目标物体的名称,带粗体标记的,表示的是对称的物体。从上面我们可以分析出各个模块对整个网络的影响。上面是定量的分析,下面是定性的分析:

4.6. Evaluation on LineMOD Dataset
使用LineMOD数据集,可以看到我们的网络相对于PonintFusion以及PoseCNN+ICP是要好很多的。下面和现在一些先进网络的比较:
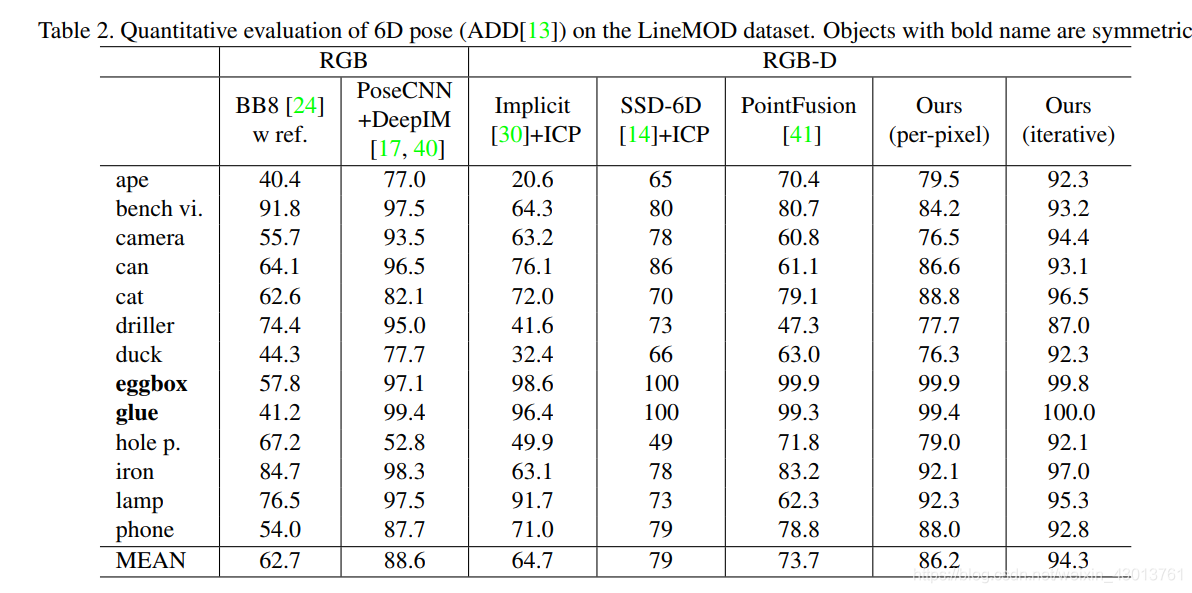
然后是使用了Iterative refinement之后的对比:

明显的可以看到,效果是有不少改进的。
4.7. Robotic Grasping Experiment
最后还做了一个机器人抓取的实验,在代码的README.md有介绍的。
