
摘要
在机器人操作和虚拟现实应用中,从图像中估计物体的6D位姿是一个非常重要的问题。鉴于直接从图像中回归得到的物体姿态精度不高,如果将输入图像和物体渲染得到的图像进行匹配,则能够得到精确的结果。在本文中,作者提出了一种叫做DeepIM的深度神经网络:给定一个初始位姿,网络能将观测图像和渲染得到的图像匹配,迭代地优化位姿。网络训练后能够预测一个相对的姿态变换,使用了一种解耦表示的3D坐标和3D朝向,并且使用了一种迭代的训练过程。本文在用于6D位姿估计的两个基准数据集上证明了DeepIM实现了较当前算法精度的极大提升,而且DeepIM有效处理之前未见到的物体。
1 问题提出
物体6D位姿估计的方法依据物体的纹理情况可以分为两大类:针对丰富纹理的物体以及针对弱纹理或无纹理物体。前者通过局部特征匹配来寻找到2D图像和3D物体点之间的对应,使用PnP方法解决;后者可分为两种方法:一种估计输入图像中的像素点或者物体的关键点对应的3D模型坐标系;另一种离散化位姿空间,将问题转变成姿态回归问题。这两种方法能够处理无纹理物体,但由于在分类或者回归阶段存在小误差,导致位姿不匹配,不能得到精确位姿。常见的后优化方法使用手动设置的图像特征匹配,或者使用代价函数,精度都不高。因此本文提出了一种基于深度神经网络的位姿优化技术,迭代地进行6D位姿的估计,提高位姿精度。
本篇论文的核心贡献如下:
- 提出了一种深度网络迭代地进行图像中物体位姿的优化,不需要任何手工设计的图像特征,能够自动地学习一种内部优化机制;
- 提出了一种对于位姿SE(3)的分别表示变换,描述物体位姿见的变换。这种变换允许对于位姿物体姿态的优化;
- 在LINEMOD和Occlusion数据集上评估了算法的精度以及其他特性,显示提出算法达到了基于RGB图像估计位姿方法的最优,而且在未知物体上得到的精度也很高。
2 算法综述
给定图像中一个物体的初始6D位姿,DeepIM能够将物体渲染得到的图像和当前观测的图像匹配,预测一个相对的SE(3)变换;之后迭代地根据估计的更为精确的位姿重新渲染物体得到渲染图像,并和观测图像相匹配,从而会变得越来越相似,使网络得到越来越精确的位姿。整体框架如下图所示:
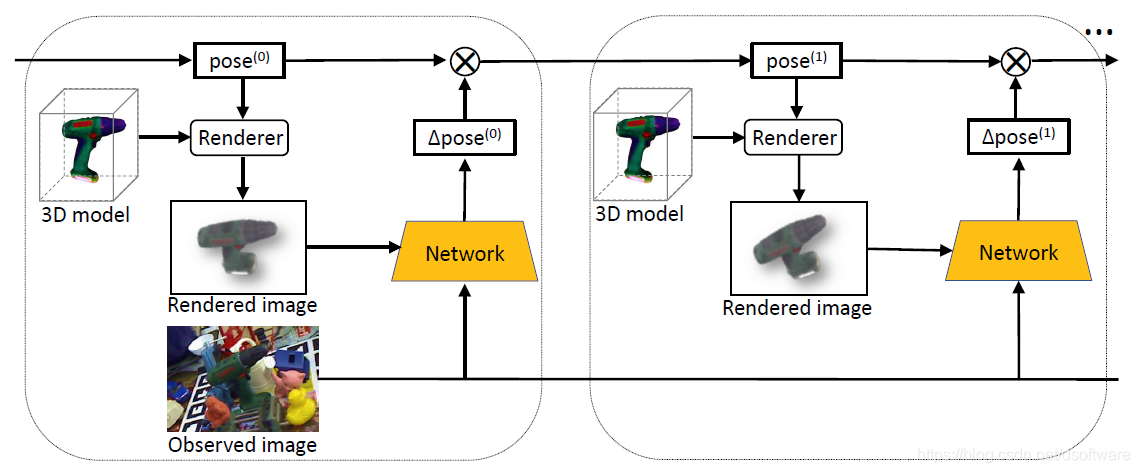
图1 算法框架
网络的输入:观测的RGB图像以及图像中物体位姿的初始估计值;网络输出:相对的SE(3)变换,可以直接作用于初始位姿以提高估计位姿的精度;
以下通过五部分介绍: a.观测图像和渲染图像的放大策略; b.进行位姿匹配的网络结果; c.一种SE(3)变换的分开表示; d.以及一种用于位姿回归的新的损失函数; e.介绍网络的训练过程并且测试网络。
2.1 高精度图像放大
为了在进行位姿匹配时获取足够多的细节,在将观测图像和渲染得到的图像送入网络前,我们将他们放大;特别地,再第
次迭代匹配过程中,给定上一步得到的6D的位姿估计
,我们将3D物体模型,根据
渲染得到一个合成的图像;之后,我们额外地为观测图像和渲染图像生成一个前景的蒙板。 这四张图像再使用一个将蒙板扩大后的包围盒裁剪。最后,我们放大并且进行双线性上采样得到和原始输入图像一样的尺寸(480*640)。重要地,物体的比例不发生变化。

图2 输入图像放大策略
2.2 网络结构
-
观测图像、渲染图像以及对应的蒙板区域串联形成一个8通道(观测和渲染图像各自具有3通道,蒙板具有1通道)的张量,输入进网络;鉴于使用VGG16的图像分类网络作为支撑网络的效果不好,因此本文使用预测图像间光流的FlowNetSimple架构作为支撑网络;位姿估计分支将由FlowNetSimple网络的11层卷积层得到的特征图作为输入,之后经过2个256维的全连接层,再分别由两个全连接层得到四元数表示的3D旋转和3D平移;
-
在训练过程中,我们增加了两个辅助的分支来归一化网络的特征表示以提高训练的稳定性。一个分支训练后预测渲染图像和观测图像的光流,另一个分支预测观测图像的前景蒙板;
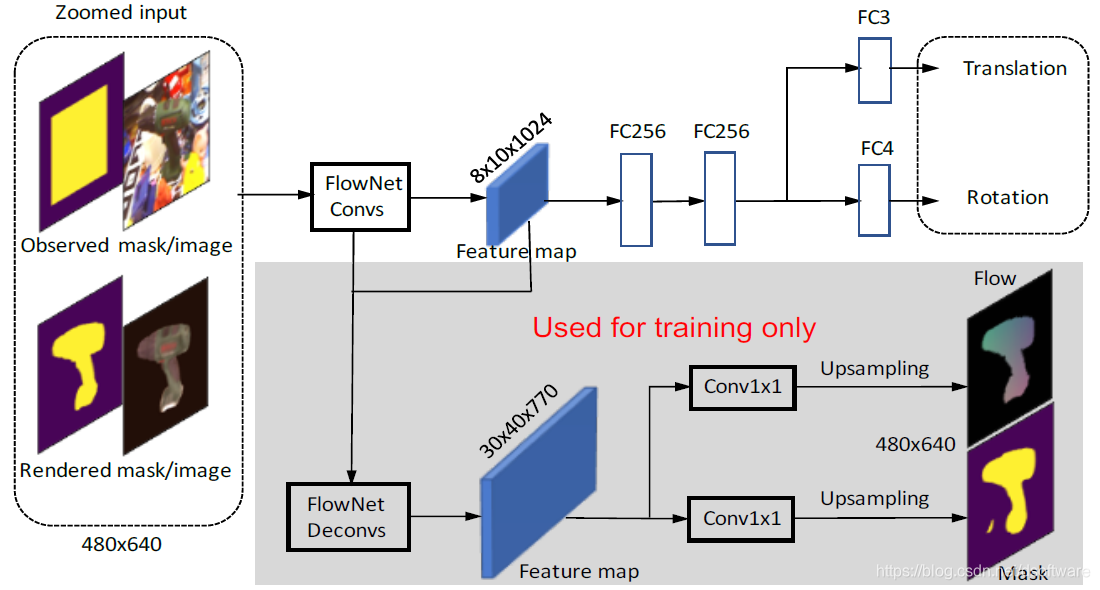
图3 相对姿态估计网络
2.3 解耦的变换表示
当前物体位姿和目标物体位姿之间的
变换
的表现形式具有重要意义。希望能够具有以下特性:和3D物体模型的局部坐标系无关;由网络预测得到的位姿变化应该和图像的变换一致。因此,本文提出将相对旋转R和相对平移t解耦表示。对于旋转,首先将相机帧的原点平移到相机帧中物体的中心(根据当前估计位姿得到),这样的话,旋转变化不会改变物体的平移;其后设置旋转轴为平行于相机坐标系的轴,这样和3D物体模型的坐标系无关。对于平移,训练网络之间回归得到相对变换
,其中,
和
代表着想x轴和y轴方向物体平移的像素,
代表物体的尺度变化:

其中,
和
代表相机的焦距。

这种表示方法具有很多好处:旋转不影响平移;中间变量 代表了图像空间简单的平移和尺度变化;这种表示不需要物体的任何先验信息,也能够适用于具有相同外表但尺度不同的物体。
2.4 匹配损失
将平移和旋转分别计算损失很直观,但是对他们进行平衡非常困难;鉴于我们想精确预测物体在3D空间中的位姿,我们对几何投影误差进行修改,成为点匹配损失:

其中
代表的是真值位姿,
代表的是估计的位姿,
代表物体模型上的随机3D点,$$n代表了用于计算损失的点数目。计算3D点根据真值位姿和估计位姿变换后的L1距离误差。
2.5 训练和测试
- 训练数据:3D物体模型和标记真值物体位姿的图像;通过增加噪声,我们得到初始位姿,并且可以生成观测图像和渲染图像,也可以得到需要输出的位姿变换,也即真值位姿和加噪声位姿之间的变换;
- 测试:训练时使用单次迭代效果不明显,因此在训练时也通过多次迭代的方式,最后使得训练数据更好的代表了测试分布,也得到了更为精确的结果。
3 实验结果
在LINEMOD数据集和Occlusion LINEMOD数据集上进行评测,比其他RGB-only方法效果好了很多,也能够实现未知物体的预测。
- 实现细节:使用FlowNet中的光流损失Lflow以及S形交叉熵损失作为蒙板损失Lmask,最终整体损失如下:

- 实验中设置a=0.1,b=0.25,r=0.03。实验中使用PoseCNN的结果作为初始位姿,在1080TiGPU上迭代两次时,能实现12fps. 后续实验中,网络迭代四次。
实验中设置a=0.1,b=0.25,r=0.03。实验中使用PoseCNN的结果作为初始位姿,在1080TiGPU上迭代两次时,能实现12fps.
- LINEMOD数据集实验

表1 LINOMOD数据集对比结果 - Occlusion LINEMOD数据集实验
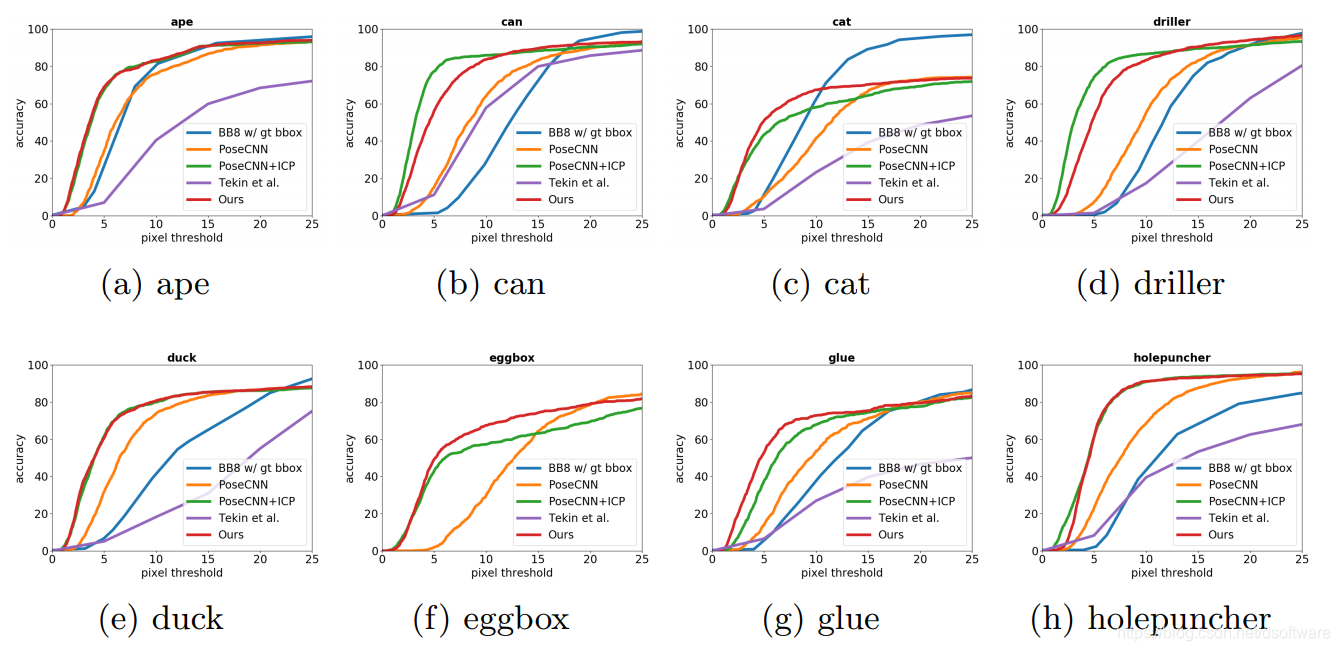
图4 Occlusion LINEMOD数据集对比结果

图5 Occlusion LINEMOD数据集位姿结果 - 未训练物体的姿态估计

图6 未参与训练3D模型位姿结果(红线代表初始位姿,绿线代表我们优化后的位姿)
4 总结
- 提出了DeepIM框架,仅使用RGB图像迭代地匹配以估计位姿;能够得到和基于RGB-D图像的位姿估计算法相当的精度;
- 未来研究方向:可以使用双目版本的DeepIM提高位姿精度;为仅使用RGB图像得到精确的6D位姿提供了可能,可使用高分辨率高帧率宽视野的相机采集数据;
- 论文源代码地址:https://github.com/liyi14/mx-DeepIM。
本文中所有图片均引自改论文。本解读只讲述核心观点,如需深入了解,可阅读原始论文。如有问题,请随时交流,如有错误,请随时指正。