以下链接是个人关于FSA-Net(头部姿态估算) 所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:a944284742相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。
姿态估计1-00:FSA-Net(头部姿态估算)-目录-史上最新无死角讲解
话不多说,我们接着前面的继续翻译。
3.6. Details of the architecture
和DeepCD 以及SSR-Net类似,FSA-Net有两个streams,两个streams的建立都是基于
和
两个模块,如下所示:
其上的
就是2维卷积,BN表示批量正则化,
表示通道数,
和
为激活函数,第一streams的结构由下面三个阶段连接而成:
第二streams的结构由下面三个阶段连接而成:
我们使用的K=3折,所以两个streams,分别会输出3个特征图,并且对应阶段的特征会结合起来,变成一个特征图。
下面是我们在实验中设定的参数,结合图示进行查看:
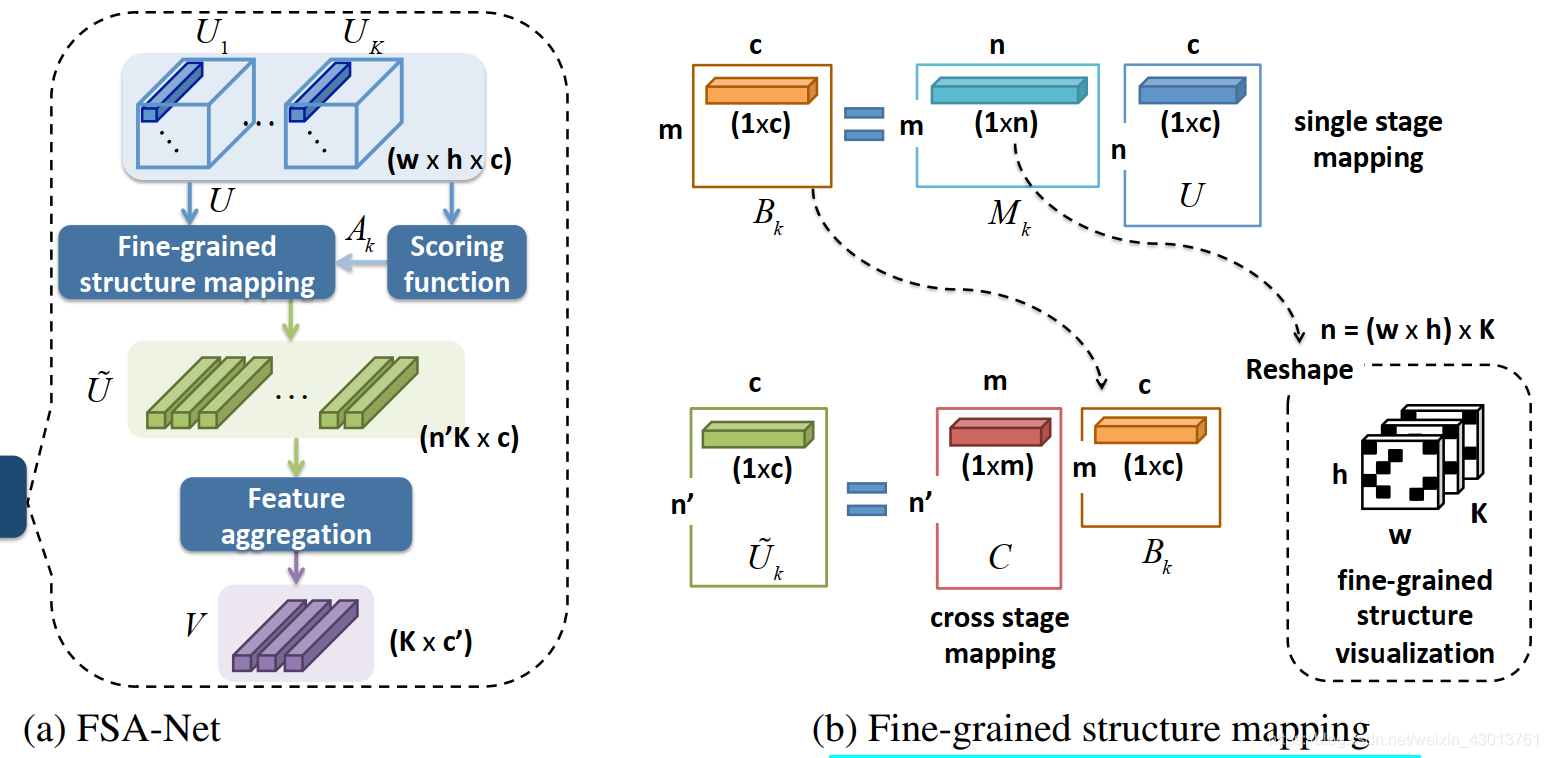
特征图:
,
,
,
fine-grained structure mapping:
,
,
feature aggregation module:
4. Experiments
接下来主要是对实验进行讲解了,主要是训练,测试,评估结果,以及和其他方法的对比,最后做了消融研究(就是探查每个网络组成的作用,如先去掉某个网络子结构,然后再加上某个网络子结构,对比两次实验结果)
4.1. Implementation
我是使用基于tensorflow的kreas框架,对于数据增强我们采用了随机剪切以及缩放(0.8~1.2)。整个网络训练了90个epoch,初始学习率为0.001,每30个epoch之后缩减十分之一,在进行结果推断的时候,每张图片只需要1ms。
4.2. Datasets and evaluation protocols
Datasets. 在三个比较流行的人脸姿态估算的数据集上进行了实验,分别为
,
,
。这个
数据集来自于
, Zhu等人基于
数据集,使用3D方法,去生成了61225个太姿态的样本, 加上左右翻转,共122450个样本。这个合成的数据,名字叫做
。
数据集,提供了真实的3D脸,以及68个关键点。这些脸的姿态变化都比较大,并且带有不同的光照条件。
数据集包含了20个目标的24个视频(控制条件下),其大概有15000帧图片。出了RGB图片,其还带有深度图。下图是该数据集的一些实例:

接下来在实验中,我们遵循如下两个协议:
Protocol 1. 在这个协议中,我们的目标是和利用关键点的姿态估计算法进行比较。训练集为 ,测试集为两个真实数据集,即 与 ,注意我们的设置和Hopenet(估计是一篇姿态估算的论文)相同。在 数据集上进行评估的时候,我们只考虑了 [-99°,+99°] 的样本。和最先进的,基于关键点的算法进行了比较,batch_size都设为16。
**Protocol 2.**这个协议中,我们使用了70%的 数据当做训练数据,剩下的百分之当做测试数据,使用MTCNN进行人脸检测。在这个协议中吗,我们和多模态的算法进行对比,于基于深度图或者基于时序视频图的。但是我们的模型只使用了一张RGB图,batch_size都设为8。
4.3. Competing methods
我们和以下几个先进的姿态估计算法进行了比较,首先是基于关键的的一组方法:
KEPLER在预测关键点的同时,一进行姿态估算,其是基于GoogLeNet架构实现。姿态的估算是为了改进关键点的检测。
FAN是一个基于关键点检测比较先进的方法,该方法对遮挡的鲁棒性很强,这个方法需要跨尺寸提取特征。
Dlib是一个人脸关键点,姿态检测的标准库
3DDFA是将3D模型拟合到RGB图像上,对遮挡的鲁棒性很强。
对于Hopenet,其是一种没有基于关键点的方法,他采用了ResNet进行训练,以及MSE和交叉损失商为loss。
还有一些基于多模态的方法,如VGG16+RNN(RGB+Time)。Martin使用深度图进行头部姿态估算,DeepHeadPose使用一个低分辨率的RGB-D图像,他同时使用分类和回归来预测姿态。
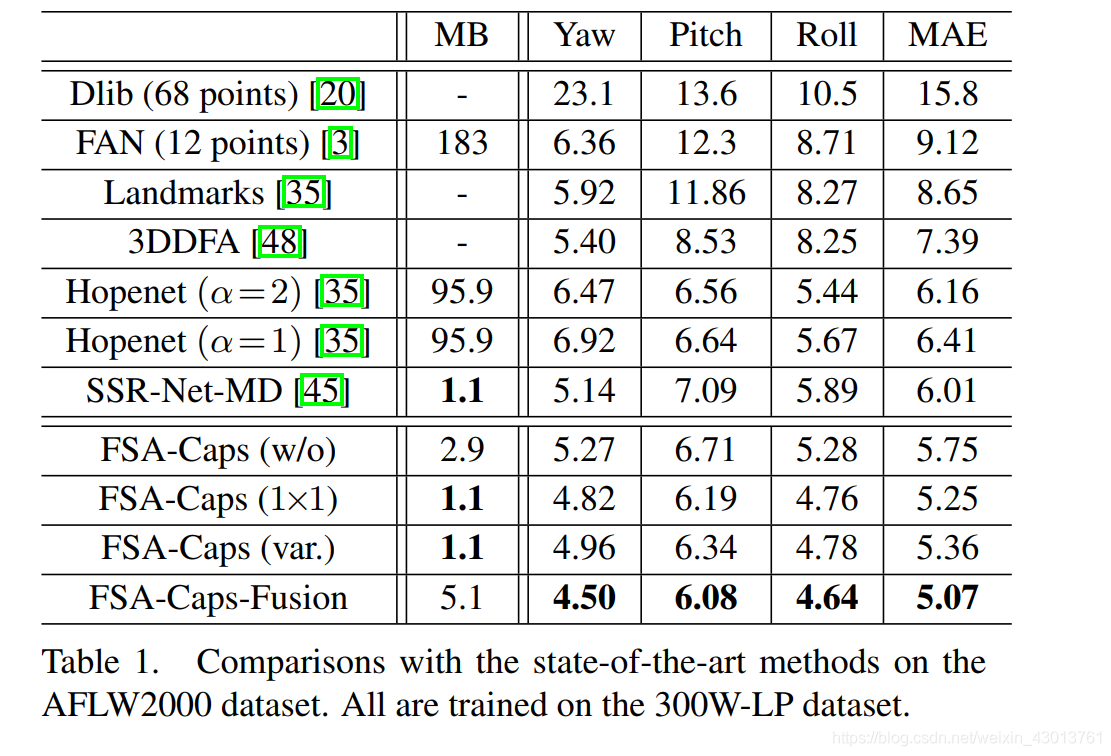
4.4. Results with protocol 1
在改协议的情况下,训练数据为 ,下面的两个表格是FSA-Net和目前最先进的模型比较的结果,基于 与 进行测试,分别的,mean absolute error (MAE) 当做评估的方法,在这个协议下,训练集和测试集的数据分布差距是很巨大的, 与 为真实数据集,而 为人工合成数据集。没有使用关键点姿态估算方法,相对来做,能够更好的跨越数据域的阻碍。所以无关键的方法(Hopenet, SSR-Net-MD and FSA-Net)的性能在 与 上的测试结果是比较好的。SSR-Net-MD and FSA-Net两个模型比Hopenet小,所有的FSA-Net变体模型表现的结果都比SSR-Net-MD好。
FSA-Caps 表示使用 capsule进行feature aggregation(特征聚合)。scoring function有种方式:
1.w/o没有使用scoring function功能,
2.1x1表示使用1X1的卷积
3.var表示使用方差的方式
4.Fusion表示融合了所有方式
详细的实验结果如下两表格所示:

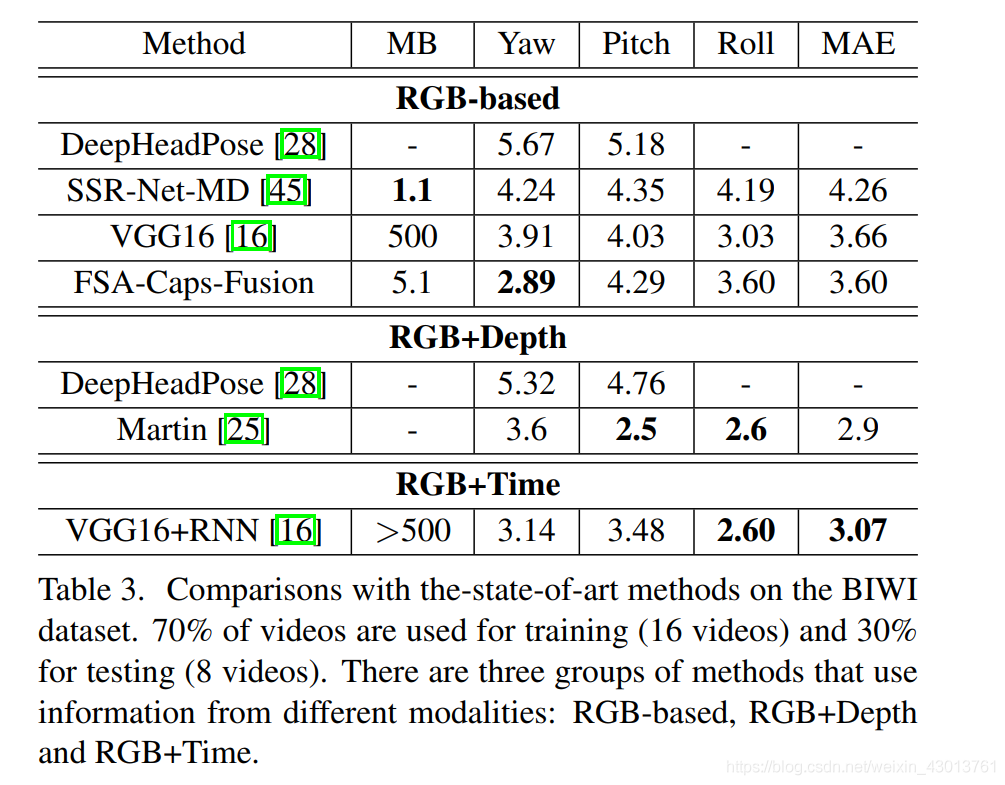
4.5. Results with protocol 2
该实验下,主要和多模态的算法进行了比较,在
数据集上进行测试,百分70为训练数据集,百分之30为测试数据集:
4.6. Visualization
可视化fine-grained structures结构捕获细节的能力,该方法为FSA-Caps(1x1)模型,基于$300W-LP $数据集进行训练,如下图所示:

图像的第一列展示的是模型估算的姿态结果,剩下的图像展现的是从像素级特征,聚合而来特征的可视化。这个heatmaps是
每个行向量重新改变形状之后的可视化。在上篇博客,讲解过
的每一行,可以转化为一个
的特征图。上图(c)显示,其是聚合了前额和眼睛的空间特征。可以看到检测的范围都是相似的,但是由于姿态不一样,略有不同。就是注意力集中的地方不一样。
4.7. Ablation Study
我们还做了消融实验(主要是为了对比每个网络部件的作用),其结果展示在下面的表格:
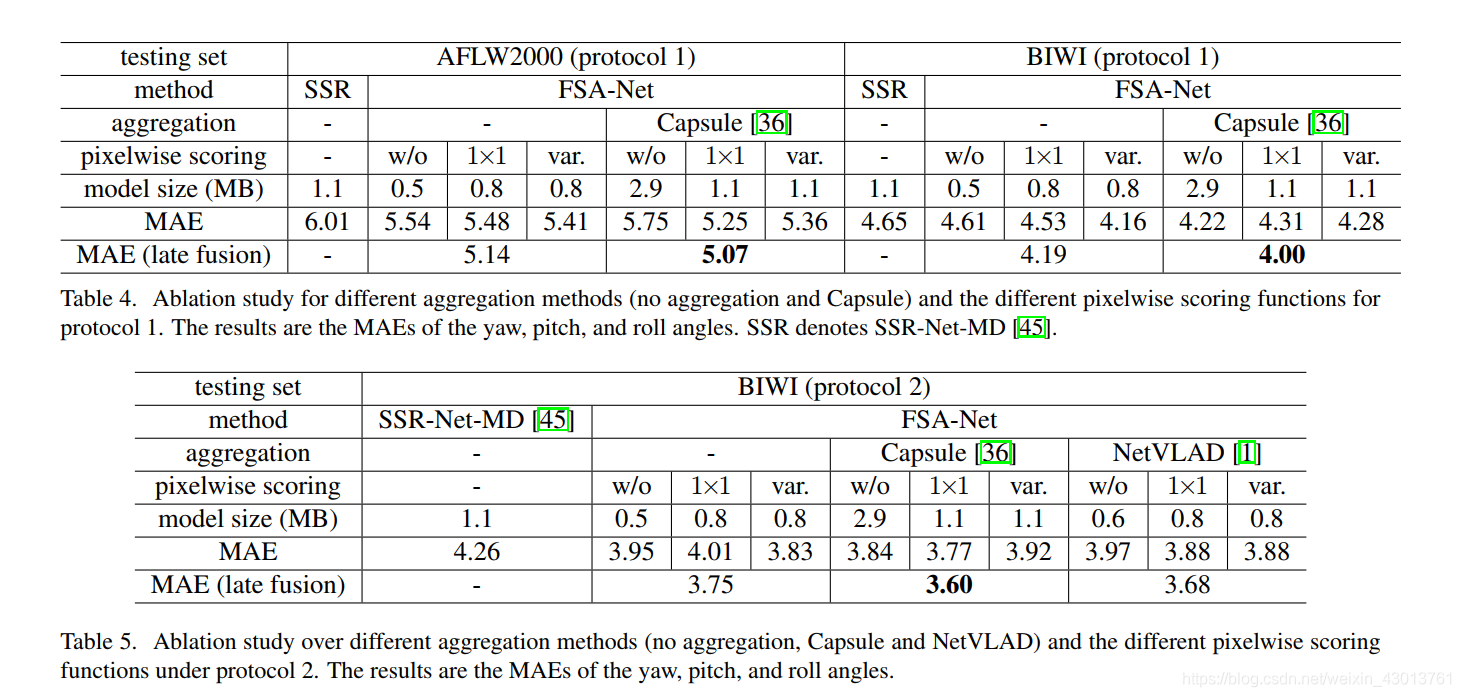
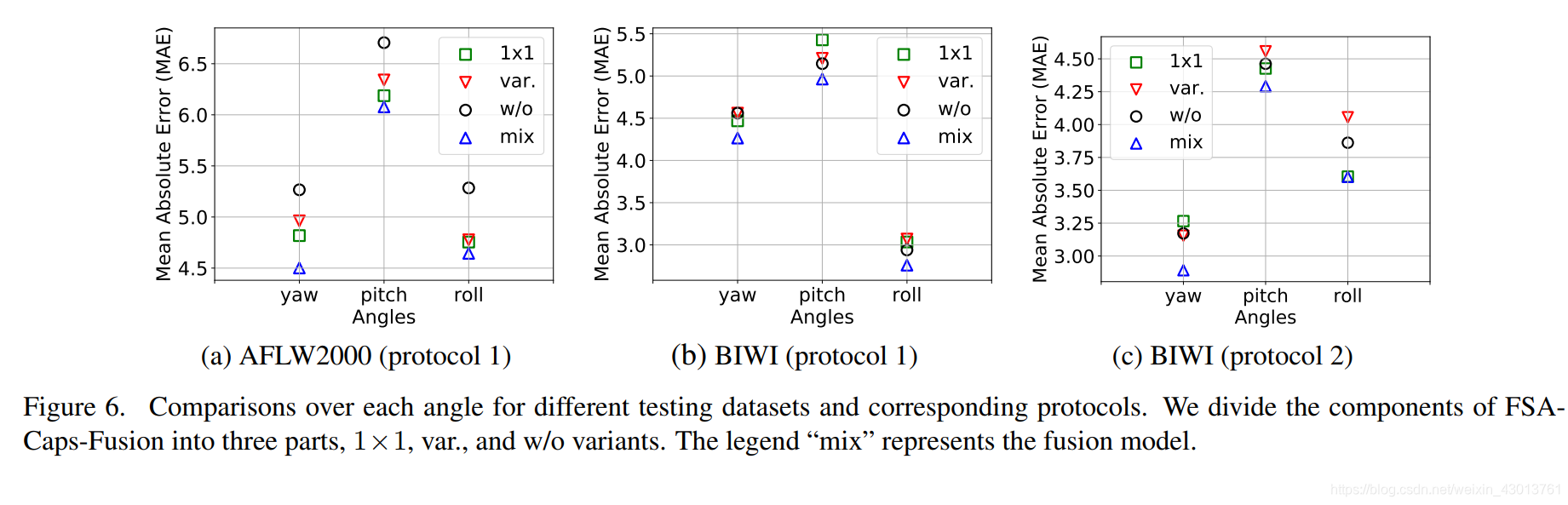
包含了不同的aggregation方法(none, capsule, NetVLAD),以及不同的pixelwise scoring functions方法(none, 1×1 convlution,
or variance)。
因为我们的方法是基于SSR-Net-MD,所以他也当做一个对比的对象,列出在表格中,通过 capsule 或者 NetVLAD 对其进行改进,也就是说,最先进的aggregation方法,可以自然的和我们提出的方法进行结合。Figure 6 详细的显示了他们的对比结果,可以看到单个的
scoring function都没有获得最好的结果,融合的scoring function可以达到最先进的结果。展现出可以学习的1x1卷积方法,和基于方差的方法,他们之间是互补的。
5. Conclusion
一堆吹逼的客套话,我就不翻译了。以后自己写论文,加上这些吹逼的话,其实也是有必要的。
结语
到这里,论文翻译就完成了,下面我们就要结合代码,深入的分析,其实现的每一个细节了。圣诞节快乐啊,各位小姐姐小哥哥!
