作者:仲夏夜之星Date:2020-04-08
文章“A Method for 6D Pose Estimation of Free-Form Rigid Objects Using Point Pair Features on Range Data” 2018年发表在《sensors》上,是近年来对PPF方法的进一步继承与改进。
1.本文的思路
本文介绍的方法主要分为两个阶段即线下建模与线上匹配,在建模时,通过计算和保存所有可能的模型对及其相关的PPF来创建全局模型描述符。在匹配阶段,通过使用PPF将场景对与存储的模型对匹配来估计场景中的模型姿态。这一匹配过程由两个不同的部分组成:(1)利用四维特征找到对之间的对应关系;(2)将产生假设姿态的对应关系分组。
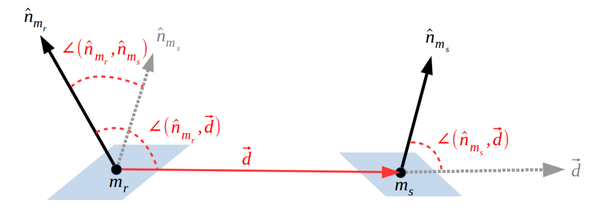
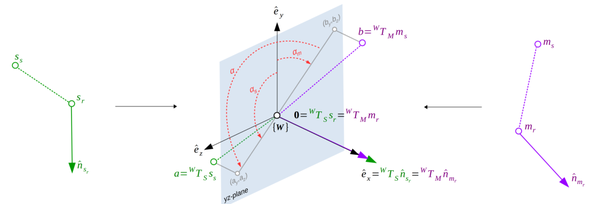
模型点对(mr,ms)定义的点对特征
2.本文内容

(1)模型的前处理
前处理包括法向估计和对点云的下采样。其中法向估计问题,本文建议使用两个不同的变体来表示每个阶段的输入数据表示。对于离线阶段,使用重构或cad网格数据,通过平均每个顶点周围三角形的法线平面来估计法线。对于在线阶段,利用有组织的点云数据,本文提出了一种基于一阶Taylor展开的方法,包括对表面深度差高于给定阈值的情况下的双边滤波器启发解决方案。而对点云下采样方面,本文是基于一种新的利用表面信息的体素网格下采样方法和一个额外的非识别对的平均步骤。首先计算点云数据的体素网格结构,对于每个体素单元,采用贪婪聚类方法对具有相似正态信息的点进行分组,即法线之间的角度小于阈值。然后,对于每个聚类组,我们平均定向点,有效地合并相似点,同时保持判别数据。与原始方法一样,体素大小设置为,定义相对于模型大小的值,然而,在本文方法中,参数对算法性能的影响显著降低,转向了一种更鲁棒的参数无关方法。
(2)特征提取
在离线阶段,得到模型包围盒,并将模型直径估计为包围盒的对角线长度,对于给定的ppf,使用方程(1)中定义的量化函数来获得四维数组:
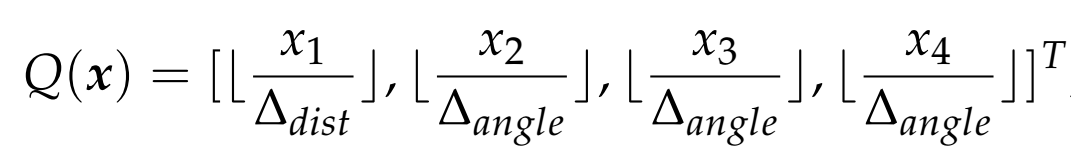
(1)
其中量化步骤设置为0.05dm,固定为,这些值被设置为识别率和速度之间的权衡。这样,哈希表的尺寸得定义为,在预处理后,对于每个模型点对,得到量化的ppf索引,并将参考点和计算的保存到哈希表对应的单元格中。
在线阶段,对于每个参考点,将计算所有可能的点对,并使用四维查找表与对象模型进行匹配,其中每五个点中只有一个(按输入顺序)将用作参考点,其余点将用作第二点,为了提高匹配部分的效率并且避免考虑比模型直径更远的点对,对于每个场景参考点,我们建议使用一个有效的kd-tree结构来获得模型直径内的第二个点。
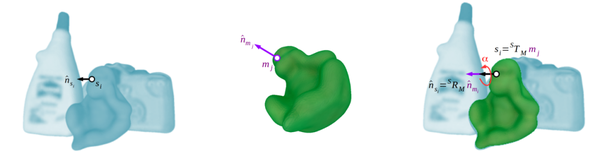
(3)线上匹配
本文提出了一个更有效的解决方案,只检查保持量化步骤大小的16个邻域中最大一个,如图7d所示。考虑到相似点对之间的差异主要是由传感器噪声产生的,可以合理地假设这种噪声遵循一个正态分布,其特征是一个相对较小的标准差,即小于量化步骤,基于这一假设,我们检查量化误差方程
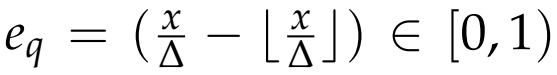
,以确定哪些邻域更有可能受到噪声的影响。这个过程是由方程(2)中表示的分段函数为每个维度定义的:
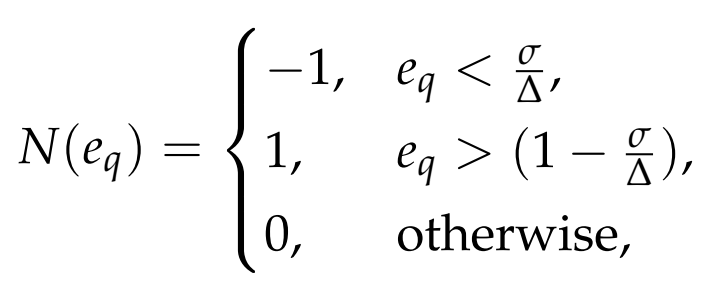
(2)
其中-1表示左邻域可能受到影响,1表示右邻域可能受到影响,0表示没有邻域可能受到影响。
在实验中,我们将标准差值设置为量化步骤;然而,对于任何特定的噪声模型,都可以使用其他值,该方法可以访问单个哈希表单元格的最佳情况和访问16个单元格的最坏情况。
(4)位姿假设
在假设生成过程中,所有一致的点对应被分组在一起,生成一个候选姿态。详细地说,对于每个获得的场景模型点对,在二维投票表中投票一个LC组合。这样,哈希表的每个位置都表示一个LC,定义了场景中的模型姿态候选,其值表示支持的数量,这表明姿态的可能性有多大。通过一个总大小为
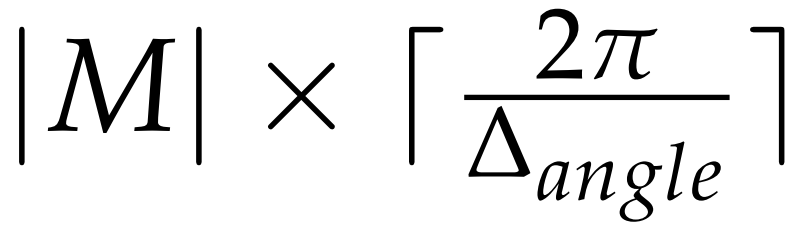
的投票表定义的来量化LCα,在所有投票被投完后,哈希表的最高值表示最可能的LC,为这个场景参考点定义一个候选姿态。该文定义一个阈值,只考虑具有最小支持数的LC,如果哈希表的峰值低于这个数字,则姿态将被丢弃;否则,将生成具有相关分数的候选姿态。
(5)位姿聚类
为了将相似的姿态组合在一起,我们提出了一种分层完全链接聚类方法。这种聚类方法强制要求每个聚类的所有元素组合基于两个主要阈值,即距离和旋转,在实验中,我们根据候选位姿的投票决定对位姿进行排序,并为每个位姿创建一个集群。然后,按顺序检查所有集群,当条件保持其元素的所有组合时,两个集群被连接在一起。这样,最有可能的集群将首先合并,减少相互排斥组合的影响。
(6)后处理
由于摄像机视图自遮挡在场景中的模型点产生的偏差和对象模型相对于场景的可能对齐误差,我们将上述位姿通过ICP算法进一步进行细化匹配,得到最优位姿。

3.实验结果
(1)BOP基准数据集
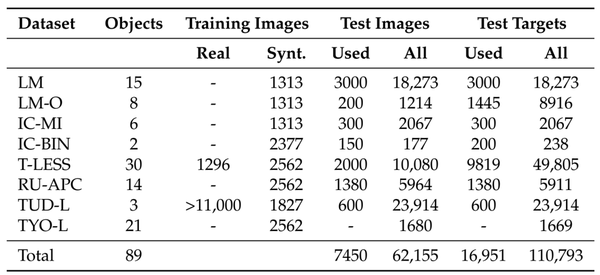
(2)不同方法之间的性能比较
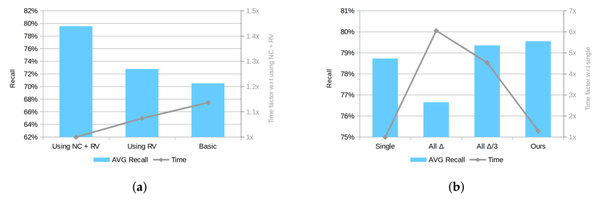
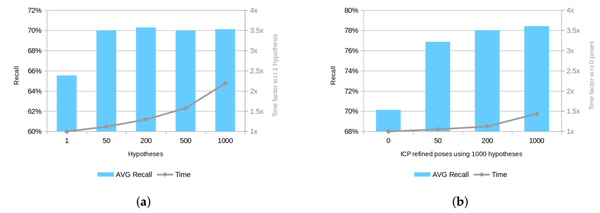
(3)使用不同的后处理参数进行性能比较
(4)所提出的方法对BOP基准数据集的场景的影响。场景RGB数据以灰色显示, 对象模型以颜色和绿色包围框内显示。

4.参考文献
[1] Drost, B.; Ulrich, M.; Navab, N.; Ilic, S. Model globally, match locally: Efficient and robust 3D object recognition. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 998–1005.[2] Vidal, J.; Lin, C.; Martí, R. 6D pose estimation using an improved method based on point pair features.In Proceedings of the 2018 4th International Conference on Control, Automation and Robotics (ICCAR),Auckland, New Zealand, 20–23 April 2018; pp. 405–409.