文章目录
解决什么问题
6Dpose估计的微调,让结果更精准
本文创新点\贡献
- 基于图片的pose微调网络
- 在目标位姿之间提出了 的untangled表达,这种表达还能用来微调看不见的物体
前人方法
- 将从图像中提取的特征和物体的3D模型中的特征匹配,使用2D-3D对应来估计位姿,但是这种处理不了纹理少的物体,能用来提取的特征很少
- 处理纹理少的方法:估计3D坐标系的像素或者关键点,然后建立对应来估计;用分类或回归的方法(小的的分类或回归误差会影响后来的结果)
本文IDEA来源
没讲,此处写一下借鉴的方法:
- [ Training a feedback loop for hand pose estimation ] 2015 迭代的方法借鉴于此
- [ Geometric loss functions for camera pose regression with deep learning ]使用重投影误差作为loss,作者做了一些修改
方法

方法概述
用输入的poes生成render图片和render mask图片,结合observed图片和obserbed mask图片输入到网络中,生成pose偏差,用这个偏差修改pose后再输入到网络中,再生成一个pose偏差,再修正输入,即得到最后微调的结果
High-resolution Zoom In

目的
很小的图片很难获取好的特征,所以要调高observed图片的分辨率。
步骤
根据输入的pose可以生成rendered图像和rendered mask,observed图像就是检测出来的bbox,根据这个也可以生成一个mask(要注意一点,得到这个ovserved mask之后要随机扩大十个元素,这样可以避免过拟合),然后将这四张图中的物体、mask截取出来,截取的时候要保证两个条件:
- 截取的大小要能在保证长宽比不变的情况下,缩放到原图大小(比如 )
- 截取出来的中心要是3D模型的原点的2D射影(根据输入的pose获得)
之后放大并线性插值到原图的大小(作者的是 )
缩放到原图大小就相当于让摄像机的中心发生了位移
我的理解是obserced和rendered用的是同一个中心,也就是model原点射影的中心,然后截取面积的时候按照跟原图一样的截取,长宽都要比observed图片的bbox大一些
Untangled Transformation Representation

目标
找到一个合适的表达方式,既能得到好的效果,又能处理没见过的物体
分析
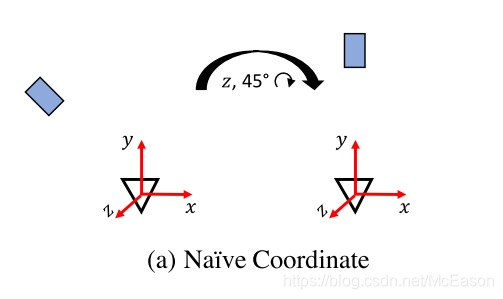
先在 a Naive 坐标系下考虑:
假设当前的pose为
,与真实值
之间的相对差值为
,则真实值为:
表示旋转的差值,它不仅会对旋转产生影响,还会对位移产生影响
转动之后位置就变了,原本两个点之间的相对位置也变了,所以无法在不知旋转差值的情况下知道
是3D坐标系的,图中的对象的实际大小和图中的移动距离是相关,因此,如果想把图中的误匹配转换成位移偏移,那么就需要知道物体的实际大小,这样的话训练起来比较困难,而且没法对没见过的物体的进行预测
因为物体图像已经放大了,所以每次的像素都代表不同的空间大小,所以如果想用网络来预测3D空间偏差,那么必须每次都知道物体的实际大小,不同的物体经过不同的缩放,无法直接从剪切的图得到3D空间的偏移
或许可以在预测上下手?预测像素度量上的偏差?
哈哈哈哈哈哈哈哈哈,猜对了
所以此时得到初步结论:要做去耦操作,分开预测RT,R是不受缩放影响的,再想办法让T不受R影响
旋转

将旋转的中心从摄像机的原点移动到摄像机坐标系下的物体的中心,由当前的位姿来估计差值,这样旋转就不会影响位移了
是的
现在原点移动过去了,剩下坐标轴还没有确定,如何选择坐标轴?
不能选 b Model , b Model 的坐标轴是根据物体选择的,这样的话又面临提前知道每个物体的坐标轴的问题了,难点如上,所以最后选择建立跟摄像机坐标系平行的坐标轴 c Camera
位移
设真实值和输入值分别为 ,两点间直线距离
但是还是扯到了度量的问题,在不知道真实尺度的情况下,依然不能直接从图中获取
,所以改成在像素上回归:
其中
表示物体应该沿着
轴移动的像素数量,
是物体的尺度改变:
其中
很好理解,是到像素平面的转换
缩放变化
被定义成比例,这样就跟物体的实际大小没有关系了,只与rendered距离和observed距离的比例有关,用对数处理,使当没有比例变化的时候,值为0
因为 在特定的数据集里都是固定的,所以这里可以设为1
学到了
优点
- 旋转不会影响位移,计算位移的时候就不用再考虑旋转的影响了
- 中间变量 的提出使在图像空间上的表示变得简单
- 不需要物体的先验知识,不用管实际的大小和坐标系
数据准备
使用的 LINEMOD 数据集,里面有15个物体,13个用于训练。
- 对于每个图像,在真实pose的附近生成10个随机pose,最后在训练集里每个物体有2000个训练样本
- 为每个物体生成10000人工合成的照片,pose分布和真实数据相似,对每个合成照片生成1个靠近真实pose的随机pose,背景从PASCAL里随机选择来代替。
所以每个物体共有12000个训练样本
训练
网络

输入:
observed图片和rendered图片,以及对应的两个mask组成一个八通道的tensor,输入到网络中
backbone:
使用的FlowNetSimple作为backbone来计算两个图片之间的光流
光流是啥,视频分析好像有,直接换成注意力机制不知可行不
作者还是了用VGG16来做backbone,发现效果很垃圾,然后有个直觉就是与光流相关的表示对于位姿匹配非常有用
或许要看看光流了
Flownet: Learning optical flow with convolutional networks 2015年的论文
直接看看最近还有没有搞光流的
位姿估计分支:
使用FNS的11层之后的特征作为输入,包含两个全连接层,每个的维度是256,然后接上两个额外的全连接层来预测3D旋转的四元数和3D位移
辅助分支:
训练的时候,还添加两个辅助分支,来规范化网络的特征表示,虽然没有让结果变得更好,但是增加了训练的稳定性。
稳定是指loss的变化吧,为什么?
在这个特征图后面的两个1x1卷积,分别是1通道(mask)和2通道(光流),然后用双线性差值的上采样方法还原到原图大小 来计算loss
- 一个被训练来预测observed图片和rendered图片之间的光流
- 另一个来预测观测图中的前景mask
观测到的才是真实的,必然要让预测的mask很准,现在的mask已经挺准的了,那么用预测出来的rt生成mask,再利用分割网络预测出的mask,来做微调?
其他的方法是用mask来预测原来的位置,但用mask和model是得不到rt信息的,那么作者要如何根据render的mask和预测出来的mask来微调呢?
光流又有什么用呢?
mask有啥用呢?
到最后也没说有啥用,或许网络在做这个的反向传播的时候,增强了学习更细节的物体划分的能力,有利于pose估计?
参数设置
初始化:
新的层的权重都是随机初始化的,除了用来处理输入的mask的卷积层和预测位移的全连接层,这两个是用0初始化
学习率:
初始的学习率是0.0001,共训练8个epoch,在epoch为4、6的时候除10
训练和测试
训练:
- 给真实pose添加噪声来生成初始pose,并生成observed图和rendered图
- 不能只进行一次调整,这样的话测试的时候多次迭代也没什么效果,所以训练的时候也要进行多次迭代,把前一次的输出当下一次的输入,这样结果会更好
测试:
- 如果输入的pose和真实的pose相差很大,rendered图可能只有一部分在observed图中,这个时候没有先验知识是很难预测的,所以一般是假定输入的pose和真实的pose差的不是很大,这样才能进行
- 把mask和光流分支抹掉了
- 使用rendered mask的最紧密的bbox来代替observed图的真实mak(都是方框),然后网络就会寻找估计位姿的邻域的对象来匹配
根据rendered位置来找
Loss
Point Matching Loss
直接点方法就是旋转和位移单独计算,旋转用角距,位移用L2距离,但是分开的话平衡这两个又比较困难。
Geometric loss functions for camera pose regression with deep learning 提出用重投影误差作为损失函数,使用真实的位姿和估计的位姿,计算3D点的2D投影的平均距离
什么样的平均距离?每个点之间?
可以稍微看看这个论文怎么说的
作者改动了一下,命名为Point Matching Loss。
其中
是真实值,
是估计值
是在模型上随机选择的3D点,
是选择的点的总数(3000)
这个损失函数函数计算使用真实位姿和估计位姿得到的相机坐标系的点之间的平均 距离
mask和光流 loss
光流loss是[ Flownet: Learning optical flow with convolutional networks ]中的
mask的loss是sigmoid 交叉熵loss
总loss
其中
batch size是16
观测的mask随机扩大十个像素来避免过拟合
怎么扩大?全方位?可能是H or W随机算一个扩大吧
为什么这样能避免过拟合?
扩大之后的mask不仅有object,还有一些背景信息,如果一直只有物体,可能在物体身上发生过拟合,放到别的环境中可能效果很差
实验
度量
6D位姿估计有三个标准:
- 旋转误差在5°以内,位移误差在5cm之内,算作正确的
- 使用估计的pose和真实的poes计算3D点转换的平均距离,对于对称的物体,选最近的那一组,如果平均距离再3D模型直径的10%以内,算正确
- 使用估计的pose和真实的pose计算3D模型点的2D投影平均距离,如果平均距离小于5个像素,则认为正确
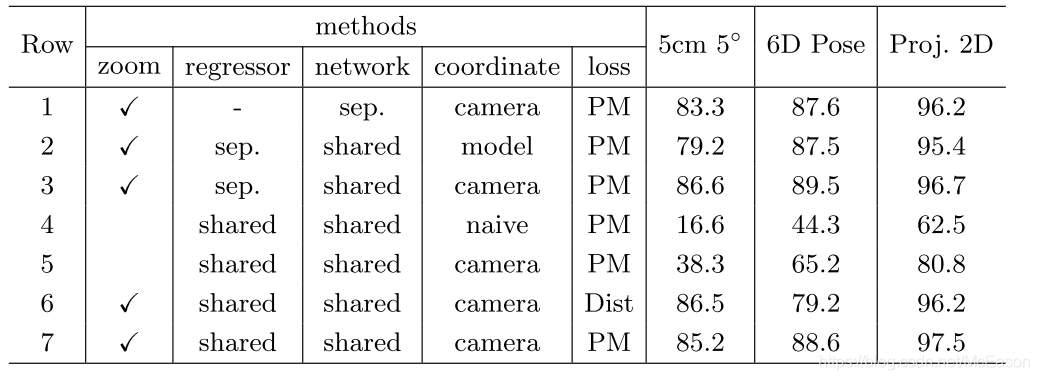
消融实验
迭代

方法:
控制epoch的总数不变为32,迭代一次有32个epoch,迭代两次有16个epoch
结论:
实验证明,训练只迭代一次的话,测试的时候迭代多次也没有提升,甚至会下降;迭代两次和四次都有提升,效果最好的是训练迭代两次,此时测试四次迭代比两次有较小提升。
分析:
作者认为只有训练只迭代一次的效果很差的原因是,网络训练不够,训练2测试2比训练4测试4好不少,这说明网络想要学到微调的能力并不困难,不需要使用3,4次训练迭代。
为什么这个网络的想学习是通过迭代来进行的,epoch次数都一样,为什么对微调过的再微调,网络能学习的更好? 而不再利用网络的输出的情况就不好?
还是说网络一次性能做成的调整有限?比如一开始的差值是8,一次之后差值是6,再迭代一次差值是4,网络只有一次将差距缩小2的能力,而在训练的时候这么做网络才能学会6-4的能力,如果网络不做迭代只能学到8-6的能力,是这样吗?四次迭代结果不能更好,是因为已经很好了,还是网络的上限就是到4了?
但是这样也不能说明在其他数据集上也是这样,所以其他的实验也用的4次训练,4次测试
这点要注意
缩放
zoom列表示使用全部图片或者扩大bbox到原图尺寸,5,7行显示提高分辨率有巨大提升
regressor
shared:
所有的物体共同一个网络训练,最后生成pose的全连接层也公用
seq:
每种物体都是用独立的全连接
结论:
比较3,7行可以看到效果都不错,但是共享的明显更有效率
做实验的时候是否可以直接套用这个结论?
是不是说明主要的信息在FC256之前就已经确定的差不多了?
Network
其他人的相似操作:
[ A scalable, accurate, robust to partial occlusion method for predicting the 3D poses of challenging objects without using depth ]其中每个对象都单独训练一个网络
结论:
比较1和7,多物体共享一个网络会更好,这也暗示在多种物体上训练能帮助网络学习用来匹配的更一般的表达
那如果用其他的类的训练模型作为预训练,不知会不会好一些?
或许训练数据少的时候可以这么做?
Coordinat
前面说的差不多了,移动中心到物体并建立于camera平行的坐标轴是最好的,而且之后这样能处理没见过的物体
loss
作者的loss在6Dpose上效果很好
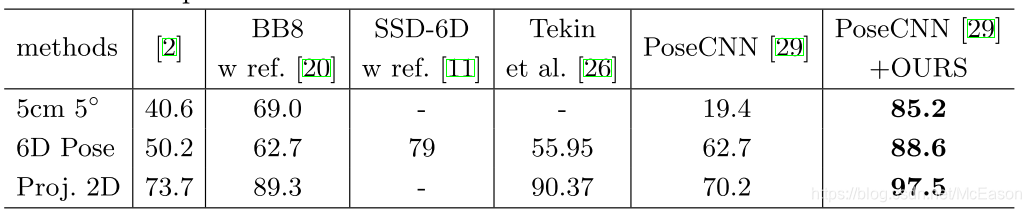
不同的初始位姿估计网络的应用

在使用这些方法的时候把bbox的中心看成物体的中心,通过最大化三维物体模型投影与边界框的重叠来估计物体的距离。
???难道要不断的试距离?还是说先跟据bbox大小确定个差不多的距离,然后再调整,找iou最大
应用到没见过的物体

红色表示输入的pose,绿色表示微调的pose,图片内容来自[ ModelNet dataset ]
在这个数据集上训练了200个3D模型,然后用剩下的70个没见过的3D模型作为测试
训练的时候给每个模型生成了50张图片,epoch 4 次,发现效果不错
代码
训练测试部分差不多看完了,其中render部分的具体操作还没看,之前没接触过,现在也没条件运行,等回学校再看看
render
update_batch
坐标轴原理
总结
- 坐标系的选择分析
- 借鉴其他领域方法
- 同epoch,迭代与不迭代的区别
- 要完成不需要先验的预测,只能从图中找信息,将一些度量换成比例
- 这个方法不需要先验知识,主要是利用mask轮廓和外观吧
