什么是Machine learning:
Machine Learning( 机器学习)是一种数据分析的技术,是教会计算机知性人和动物与生俱来的活动。同时,机器学习是实现人工智能的手段可以近似看作Looking for a function from data.
机器学习分为3个步骤:
step1: define a set of function
step2: goodness of function
step3 pick the best function
中心极限定理
中心极限定理是研究随机变量和的极限分布在什么条件下为正态分布的问题。
中心极限定理Central Limit Theorem:设从均值为μ、方差为σ^2;
的任意一个总体中抽取样本量为n的样本,当n充分大时,样本均值的抽样分布近似服从均值为μ、方差为σ^2/n的正态分布。
中心极限定理可以总结为以下两句话:
1)任何一个样本的平均值将会约等于其所在总体的平均值。
2)不管总体是什么分布,任意一个总体的样本平均值都会围绕在总体的平均值周围,并且呈正态分布。
中心极限定理作用
1)在没有办法得到总体全部数据的情况下,我们可以用样本来估计总体
如果我们掌握了某个正确抽取样本的平均值和标准差,就能对估计出总体的平均值和标准差。
举个例子,如果你是北京西城区的领导,想要对西城区里的各个学校进行教学质量考核。
同时,你并不相信各个学校的的统考成绩,因此就有必要对每所学校进行抽样测试,也就是随机抽取100名学生参加一场类似统考的测验。作为主管教育的领导,你觉得仅参考100名学生的成绩就对整所学校的教学质量做出判断是可行的吗?
答案是可行的。中心极限定理告诉我们,一个正确抽取的样本不会与其所代表的群体产生较大差异。也就是说,样本结果(随机抽取的100名学生的考试成绩)能够很好地体现整个群体的情况(某所学校全体学生的测试表现)。
2)根据总体的平均值和标准差,判断某个样本是否属于总体
如果我们掌握了某个总体的具体信息,以及某个样本的数据,就能推理出该样本是否就是该群体的样本之一。
通过中心极限定理的正态分布,我们就能计算出某个样本属于总体的概率是多少。如果概率非常低,那么我们就能自信满满地说该样本不属于该群体。这也是统计概率中假设检验的原理。
定理表达式

正态分布
正态分布:
正态分布(Normal distribution)又名高斯分布(Gaussiandistribution),若随机变量X服从一个数学期望为μ、方差为σ^2
的高斯分布,记为N(μ,σ^2)。其概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。我们通常所说的标准正态分布是μ = 0,σ = 1的正态分布。
当μ=0,σ=1时,正态分布就成为标准正态分布N(0,1)。概率密度函数为:

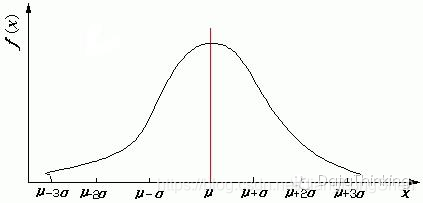
正态分布的密度函数的特点是:关于μ对称,并在μ处取最大值,在正(负)无穷远处取值为0,在μ±σ处有拐点,形状呈现中间高两边低,图像是一条位于x轴上方的钟形曲线。
极大似然估计
极大似然估计(MLE)由高斯1821年针对正态分布提出。
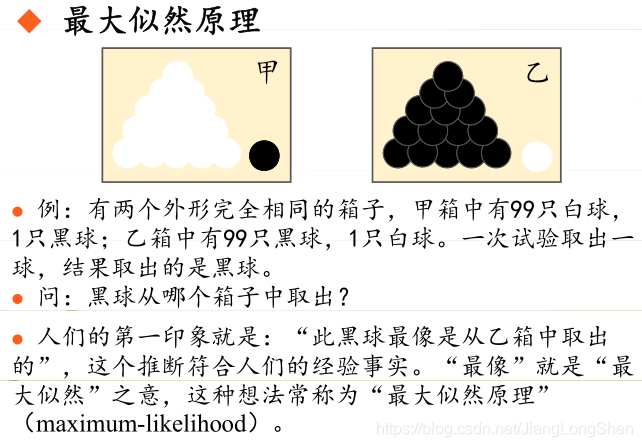
最大似然估计的一般求解过程:
(1) 写出似然函数;
(2) 对似然函数取对数,并整理;
(3) 求导数 ;
(4) 解似然方程
最大似然估计的特点:
1.比其他估计方法更加简单;
2.收敛性:无偏或者渐近无偏,当样本数目增加时,收敛性质会更好;
3.如果假设的类条件概率模型正确,则通常能获得较好的结果。但如果假设模型出现偏差,将导致非常差的估计结果。
局部最优和全局最优:
局部最优一般来讲算出来的往往不一定是最好的,有可能存在较大误差,而全局最优解往往才是正确的解。
梯度下降
https://blog.csdn.net/pengchengliu/article/details/80932232

代码示例:
https://blog.csdn.net/huahuazhu/article/details/73385362
参考文档:
1.中心极限定理, https://www.zhihu.com/question/22913867/answer/250046834.
2最大似然估计,https://blog.csdn.net/zengxiantao1994/article/details/72787849.
3损失函数,https://blog.csdn.net/wjlucc/article/details/71095206.