想写在最前面的碎碎念,“首次加入DataWale举办的系列学习活动中,跟随船长脚步,与其他船员们一起快乐通关!希望能够积累知识,早日带领自己的船员扬帆起航!”
目录
一、机器学习介绍
1. 人工智能、机器学习、深度学习三者之间的联系
人工智能是实现目标,机器学习是实施技术,而深度学习是机器学习的一个分支。人工智能的概念早在1950年就提出来了,而1980年之后才出现机器学习的方法。早年机器学习依赖于人工提取特征,而目前最火热的深度学习可以自主学习数据特征。“人工智能”可以理解为人类教会机器如何去学习(机器学习算法),使得机器变得智能化。
2. 机器学习的三个步骤
- 找函数
- 评估函数的好坏
- 自动筛选最优函数
3. 相关技术(学习策略、任务、方法)
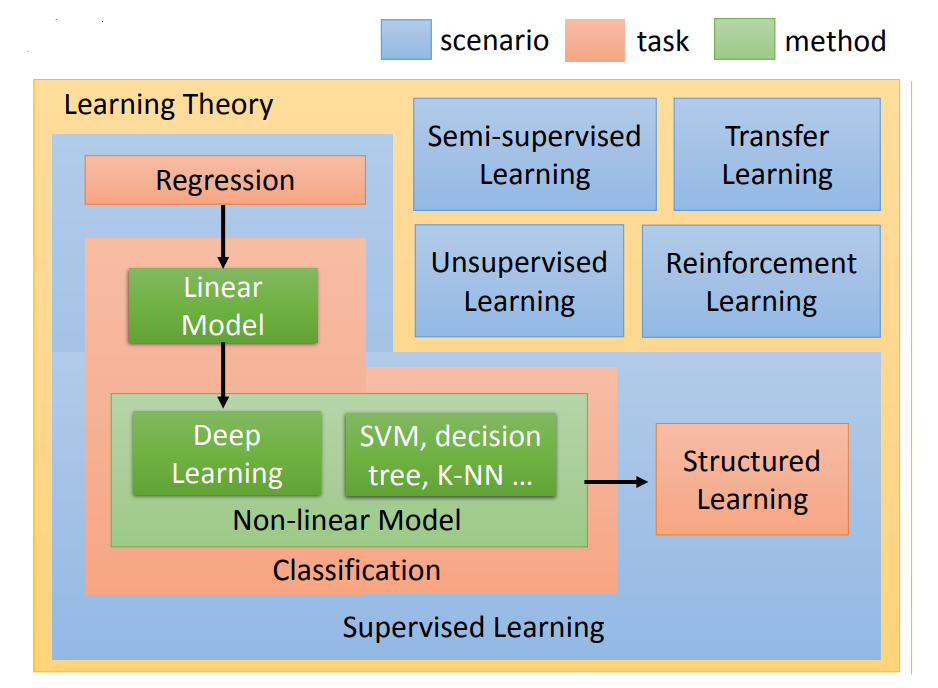
3.1. 监督学习
使用有标签的样本进行模型训练,预测标量的任务叫回归;预测离散结果的任务叫分类。还有一类叫做结构化学习,即模型输出结果是具有结构性的。
3.2. 半监督学习
监督学习需要明确的告诉模型输入和标签,标签一般由人标注,耗时耗力。为了降低标注成本,引入半监督学习的概念。部分带有标签的数据训练模型。
3.3. 迁移学习
任务A有大样本数据,任务B数据量较小,A与B考虑的实际问题并不相同,但是A与B都是分类任务,因而将A的经验权重迁移至B任务中,即是迁移学习的思想。
3.4. 无监督学习
本质思想:无师自通。用无标签数据训练模型。
3.5. 强化学习
代表性实例Alpha Go。将强化学习与监督学习作对比,前者模型会得到固定的正确答案,而后者只能依靠反馈,不断学习,逼近正确答案。
为什么不做强化学习,要做监督学习?如果有大量标签数据,谁还做强化学习。打个比方,医学图像分析领域,如果都能拿到大样本的医生标注的高质量图像数据,谁还会做半监督、无监督模型。
小结:学习策略依据数据的类型(有标签、少量标签、无标签),任务可以出现在不同的学习策略中,针对不同的任务,又有多种实现方法。
二、为什么要学习机器学习
个人观点:在学习“机器学习”的过程中,经常会听到“AI将取代人类工作”,首先我不认同这个观点,从始至终我认为AI是可以使人类提高幸福感的工具,目前已融入到我们的日常生活中,将来只会与我们的生活联系的更加紧密。AI的出现,可能会取代许多传统行业,但是同时也会激发更多新兴产业,人类一直都是最高级的生物,善用AI,才能创造更加美好的未来。
工欲善必先利其器,机器学习算法众多,选择适合任务的算法,才有可能达到预期结果。而且直接照搬算法,可能效果不佳,因此需要有经验的人进行模型调参。
打卡第一天,继续加油!