1.引言
最近也学习了好几个月的机器学习,感觉知识也只停留在理论方面,但是大佬也说过实战很重要!!所以自己看了几篇Kaggle的文章。刚好前几天加入了一个打卡群,这是第一次发布的数据挖掘任务,在这里记录一下。
任务1 - 数据分析(2天),任务1打卡链接提交截止日期为20190512晚上10点
数据集下载
说明:这份数据集是金融数据(非原始数据,已经处理过了),我们要做的是预测贷款用户是否会逾期。表格中 "status" 是结果标签:0表示未逾期,1表示逾期。
数据集涉密,不要开源到网上,谢谢~
要求:数据切分方式 - 三七分,其中测试集30%,训练集70%,随机种子设置为2018
任务1:对数据进行探索和分析。时间:2天
数据类型的分析
无关特征删除
数据类型转换
缺失值处理
……以及你能想到和借鉴的数据分析处理
2.查看数据
说实话,看到这个数据非常的头疼,特征数量就接近90个,很多连名字都不认识
简单列了一个表格
custid:信用卡ID,没用
trade_no:都一样,没用
bank_card_no:卡号没用
low_volume_percent:
middle_volume_percent
take_amount_in_later_12_month_highest:最后12个月总交易
trans_amount_increase_rate_lately:交易增长率
trans_activity_month:月交易活跃度
trans_activity_day:日交易活跃度
transd_mcc
trans_days_interval_filter
trans_days_interval
regional_mobility:区域流动,有用
student_feature:是否学生,很有用,但缺失值很多
repayment_capability:还款能力,很有用
is_high_user:是否高用户?
number_of_trans_from_2011:自2011的交易数量
first_transaction_time:第一次交易时间
historical_trans_amount:历史交易笔数
historical_trans_day:历史交易天数
rank_trad_1_month:一个月交易排名
trans_amount_3_month:三个月内交易总数
avg_consume_less_12_valid_month:12个月有效交易平均数
abs:??
top_trans_count_last_1_month:
avg_price_last_12_month:12月内交易平均价格
avg_price_top_last_12_valid_month:有效百分比,有缺失值
reg_preference_for_trad:几线城市
trans_top_time_last_1_month:一个月次数
trans_top_time_last_6_month:六个月
consume_top_time_last_1_month:
consume_top_time_last_6_month: #和上面一样的
cross_consume_count_last_1_month:??
trans_fail_top_count_enum_last_1_month
trans_fail_top_count_enum_last_6_month:交易失败计数
trans_fail_top_count_enum_last_12_month
consume_mini_time_last_1_month:
max_cumulative_consume_later_1_month:最大消费累计后1个月
max_consume_count_later_6_month:最大消费计数后6个月
railway_consume_count_last_12_month:铁路消耗在过去12个月计算
pawns_auctions_trusts_consume_last_1_month
pawns_auctions_trusts_consume_last_6_month:典当拍卖信托在过去6个月消耗
jewelry_consume_count_last_6_month:珠宝交易
status:是否逾期还款,预测值
source:都一样
first_transaction_day::所有交易天数??
trans_day_last_12_month:12个月后交易天数??
id_name:姓名没用
apply_score:统计申请
apply_credibility:可信的申请
query_org_count:查询计数
query_finance_count:查询财政??
query_cash_count:查询支付
query_sum_count:总和
latest_query_time:组后查询时间
latest_one_month_apply:申请次数
latest_three_month_apply
latest_six_month_apply
loans_score:贷款方面的
loans_credibility_behavior 下面都是一些关于贷款的信息,就没有仔细看了
loans_count
loans_settle_count
loans_overdue_count
loans_org_count_behavior
consfin_org_count_behavior
loans_cash_count
latest_one_month_loan
latest_three_month_loan
latest_six_month_loan
history_suc_fee
history_fail_fee
latest_one_month_suc
latest_one_month_fail
loans_long_time
loans_latest_time
loans_credit_limit
loans_credibility_limit
loans_org_count_current
loans_product_count
loans_max_limit
loans_avg_limit
consfin_credit_limit
consfin_credibility
consfin_org_count_current
consfin_product_count
consfin_max_limit
consfin_avg_limit
latest_query_day
loans_latest_day
3.做特征分析
3.1第一个想到的是处理缺失值
导入数据,看一看大小
df = pd.read_csv('data2.csv') df_raw = df.copy()
df.shape
写一个查看缺失值数量和百分率的函数
def draw_missing_data_table(df): total = df.isnull().sum().sort_values(ascending=False) percent = (df.isnull().sum()/df.isnull().count()).sort_values(ascending=False) missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent']) return missing_data
draw_missing_data_table(df)
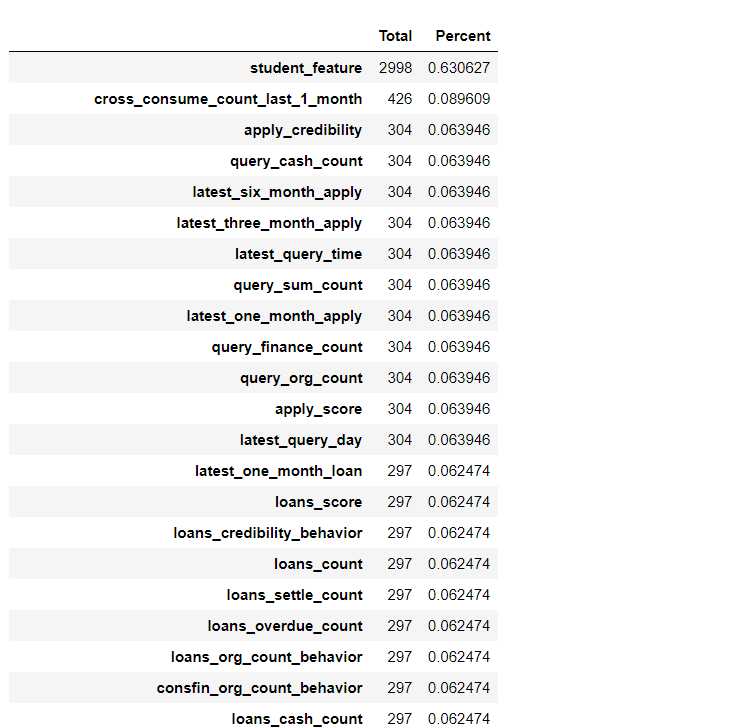 个人认为第一个特征是否为学生还是非常重要的,奈何63%的缺失率,删除!
个人认为第一个特征是否为学生还是非常重要的,奈何63%的缺失率,删除!

df.drop('student_feature',axis=1,inplace=True)
其他特征差最多不到300个人缺失,我不知道怎么填充(能力有限),缺失率也不到1%,并且观察数据基本都是单个样本缺失很多值,还是直接删除吧
df.dropna(axis=0)
接下来看一看删除了多少
1 - df.shape[0]/4754
删除了16.2%的数据,有点难受,先这样吧!!
3.2人工选择删除没用的特征
这些卡号,姓名我觉得都没用,第二行我看csv文件与前面的两个特征重复的,拜拜!
df.drop(['custid','trade_no','bank_card_no','source','id_name'],axis=1,inplace=True) df.drop(['consume_top_time_last_1_month','consume_top_time_last_6_month'],axis=1,inplace=True)
3.3处理标签型特征
df.info()
可以看到有三个特征类型要改变
-
reg_preference_for_trad 3983 non-null object
-
latest_query_time 3983 non-null object
-
loans_latest_time 3983 non-null object
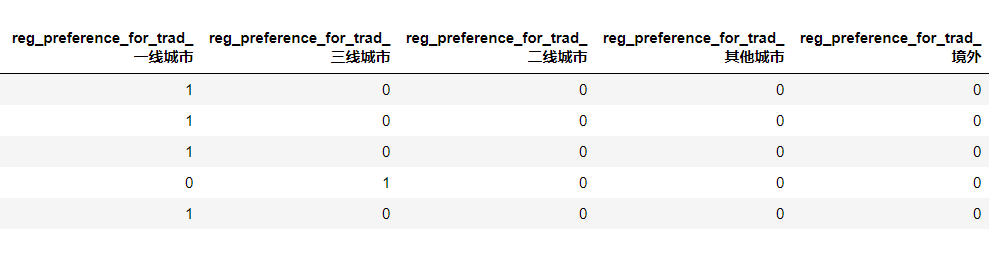
第一个是用户所在几线城市,有五个类别(array(['一线城市', '三线城市', '二线城市', '其他城市', '境外'], dtype=object)
其实一开始我用的是sklearn里的方法
from sklearn import preprocessing label = preprocessing.LabelEncoder() reg = label.fit_transform(df['reg_preference_for_trad'])
df['reg_preference_for_trad'] = reg
后来一想不对,这样每个城市的值不一样,权重也就不同了,应该是用那个啥矩阵型的
df['reg_preference_for_trad'] = df_raw['reg_preference_for_trad'] df = pd.get_dummies(df)
处理另外两个时间特征没什么思路,最后还是用时间减去样本中的最小时间,让天数来作为数据(两个都是这样的操作)
new_df = pd.DataFrame(pd.to_datetime(df['latest_query_time']) - pd.to_datetime(df['latest_query_time'].min())) df['latest_query_time'] = new_df df['latest_query_time'] = df['latest_query_time'].map(lambda x:x.days)
4.特性相关性分析
由于特征太多了,人脑选几个看得顺眼的来分析分析
import seaborn as sns sns.barplot(x=df['status'],y=df['repayment_capability'])
 还款能力,emmm差距不是很大啊
还款能力,emmm差距不是很大啊
这是一开始用的那种方法画的图


sns.barplot(y=df['status'],x=df['reg_preference_for_trad']) df['reg_preference_for_trad'].value_counts() label.classes_
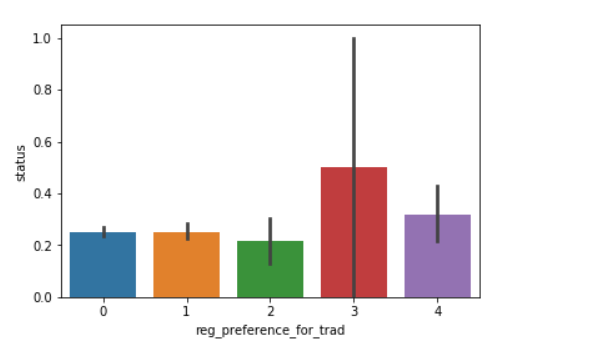
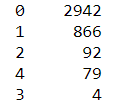 数量
数量
接下来看一看目标特征
sns.distplot(df['status'])

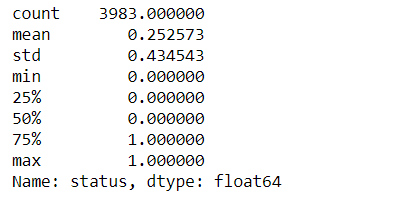 四分之一的人逾期
四分之一的人逾期
贷款持续日期,差距不大
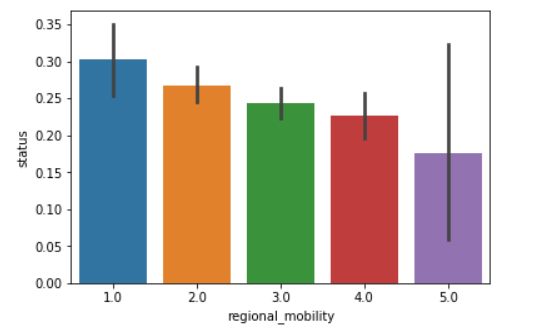
还有一个区域特征(regional_mobility)
sns.barplot(x=df['is_high_user'],y=df['status']) #这里可以看出这个高用户(??)逾期比率要低一点
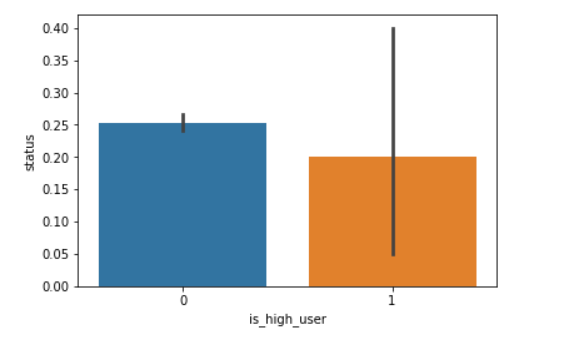

其他的特征就没怎么看了!!
(画了一个热力图,奈何特征太多太混乱)
5.数据处理
5.1数据分割,标准化
这里三七分
from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=2018) from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_train_scled = scaler.fit_transform(X_train) X_test_scaled = scaler.fit_transform(X_test)
6.上模型(sklearn)
大佬说过:invariably, simple models and a lot of data trump more elaborate models based on less data.
还有句补充:added that 'better data beats more data.
(其实是自己能力有限,只会简单模型)
6.1逻辑回归
from sklearn.linear_model import LogisticRegression log_reg = LogisticRegression(C=1) log_reg.fit(X_train_scled,y_train)
参数:
LogisticRegression(C=1, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='warn',
n_jobs=None, penalty='l2', random_state=None, solver='warn',
tol=0.0001, verbose=0, warm_start=False)
画出learning curv
from sklearn.model_selection import learning_curve # 绘制学习曲线,交叉验证(默认10折) def plot_learning_curve(estimator, title, X, y, ylim=None, cv=10, #estimator是模型 n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)): plt.figure() plt.title(title) if ylim is not None: plt.ylim(*ylim) plt.xlabel("Training examples") plt.ylabel("Score") train_sizes, train_scores, test_scores = learning_curve( estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes) #输出训练大小,训练得分,交验得分 train_scores_mean = np.mean(train_scores, axis=1) train_scores_std = np.std(train_scores, axis=1) test_scores_mean = np.mean(test_scores, axis=1) test_scores_std = np.std(test_scores, axis=1) plt.grid() plt.fill_between(train_sizes, train_scores_mean - train_scores_std, #用标准差填充一个上下波动的范围 train_scores_mean + train_scores_std, alpha=0.1, color="r") plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.1, color="g") plt.plot(train_sizes, train_scores_mean, 'o-', color="r", #画出平均值的那条线 label="Training score") plt.plot(train_sizes, test_scores_mean, 'o-', color="g", label="Validation score") plt.legend(loc="best") return plt plot_learning_curve(log_reg,'LogisticRegression curve',X_train_scled,y_train,ylim=(0.5,1.0),n_jobs=-1)
 感觉还不错,标准的学习曲线(感觉80%的得分挺低的)
感觉还不错,标准的学习曲线(感觉80%的得分挺低的)
参数问题吗??画图看一下
from sklearn.model_selection import validation_curve def plot_validation_curve(estimator, title, X, y, param_name, param_range, ylim=None, cv=None, n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)): train_scores, test_scores = validation_curve(estimator, X, y, param_name, param_range, cv) train_mean = np.mean(train_scores, axis=1) train_std = np.std(train_scores, axis=1) test_mean = np.mean(test_scores, axis=1) test_std = np.std(test_scores, axis=1) plt.plot(param_range, train_mean, color='r', marker='o', markersize=5, label='Training score') plt.fill_between(param_range, train_mean + train_std, train_mean - train_std, alpha=0.15, color='r') plt.plot(param_range, test_mean, color='g', linestyle='--', marker='s', markersize=5, label='Validation score') plt.fill_between(param_range, test_mean + test_std, test_mean - test_std, alpha=0.15, color='g') plt.grid() plt.xscale('log') plt.legend(loc='best') plt.xlabel('Parameter') plt.ylabel('Score') plt.ylim(ylim) param_name = 'C' param_range = [0.001, 0.01, 0.1, 1.0, 10.0, 100.0] plot_validation_curve(log_reg,'LogisticRegression curve',X_train_scled,y_train,param_name,param_range,ylim=(0.5,1.0),n_jobs=-1)
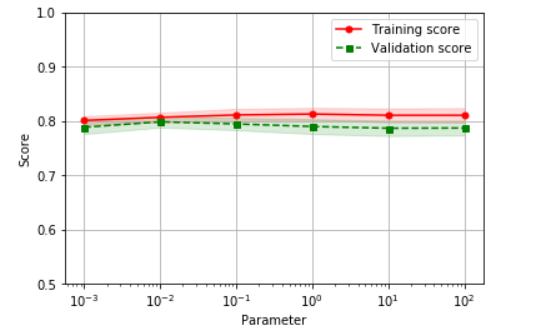 差不多啦
差不多啦
混淆矩阵

6.2随机森林
from sklearn.ensemble import RandomForestClassifier forest_clf = RandomForestClassifier(n_estimators=400) forest_clf.fit(X_train_scled,y_train) #这里400棵树是不是有点多了???
看下得分
from sklearn.model_selection import cross_val_score score1 = cross_val_score(forest_clf,X_train_scled,y_train,cv=10) score1.mean()
0.7930617625715096 没有改善!!!
6.3线性SVR
from sklearn.svm import LinearSVC svc = LinearSVC() svc.fit(X_train_scled,y_train) score = cross_val_score(svc,X_train_scled,y_train,cv=10) score.mean()
0.7909098988090634
说实话正确率比较低,这还是在训练集上的表现
6.4目前阶段总结
- 没有很好的利用测试集来选择模型
- 特征工程做的非常不好,靠人力来选择特征很terrible
- 下一步试一试集成学习
- 个人不是很喜欢KNN算法,所以没用
7.利用特征相关系数选择特征
coor = df.corr() corr_status = abs(coor['status']) corr_status_sorted = corr_status.sort_values(ascending=False) corr_status_sorted[corr_status_sorted.values>0.05]
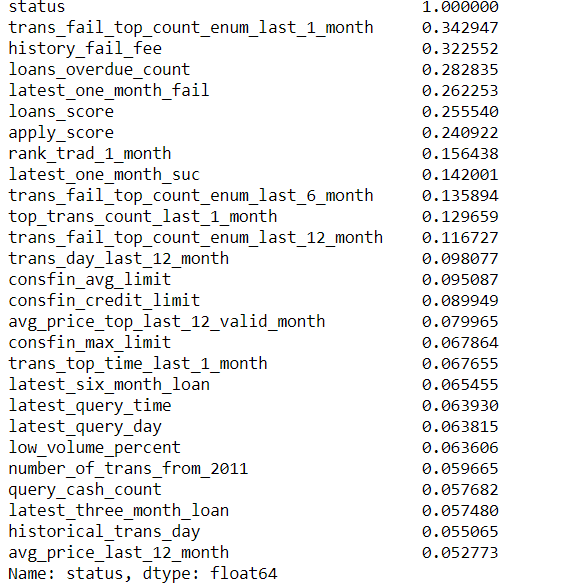 保留了27个特征
保留了27个特征
8.总结
做的比较仓促,流程也有点乱,还是要多看看别人的思路,继续加油!!!!!!!!!