版权声明:个人原创,禁止私自转载,如需转载引用请私信联系——Zetrue_Li https://blog.csdn.net/weixin_37922777/article/details/89473668
机器学习(周志华) 西瓜书 第八章课后习题8.3—— Python实现
-
实验题目
从网上下载或自己编程实现AdaBoost,以不剪枝决策树为基学习器,在西瓜数据集3.0α上训练一个AdaBoost集成,并与图8.4进行比较
-
实验原理
AdaBoost算法

若基学习器直接采用不剪枝决策树,则基本上训练后的每个决策树分类器都是趋于一致。所以为了保证个体学习器的多样性,应采用单层决策树作为基学习器,即以决策树桩作为弱学习器。
-
实验过程
数据集获取
获取书中的西瓜数据集3.0α,并存为data_3α.txt
密度,含糖率,好瓜
0.6970000000000001,0.46,是
0.774,0.376,是
0.634,0.264,是
0.608,0.318,是
0.556,0.215,是
0.40299999999999997,0.237,是
0.48100000000000004,0.149,是
0.43700000000000006,0.21100000000000002,是
0.6659999999999999,0.091,否
0.243,0.267,否
0.245,0.057,否
0.34299999999999997,0.099,否
0.639,0.161,否
0.657,0.198,否
0.36,0.37,否
0.593,0.042,否
0.7190000000000001,0.10300000000000001,否算法实现
因为本题没有限制一定要自己编程,所以本人嫌麻烦,就直接参考了网上上传的《机器学习Python实现AdaBoost》加上自己设计的画图函数,完成了在西瓜数据集3.0α上训练一个AdaBoost集成。不过,个人觉得这位博主的代码实现很难看懂,原本想着在其基础上修改优化,发现要改一个地方都很难,只能全盘重构,不过最终还是放弃这个想法了。其中有一个个人觉得不是很好的编程习惯就是直接利用from numpy import *,这样真的很难让阅读和重用代码的人知道具体这个函数是否在numpy库里面,而且很可能出现同名函数被覆盖的现象,所以适当提供作用域是很有必要的。不过,还是要感谢这位博主提供的实现参考。
数据集读取,做了稍稍改动,适用于txt,pandas形式读取

预测测试样本的标签

画图函数,按照书上图8.4形式,显式画出不同规模的集成及其学习器所对应的分类边界

X, Y分别是属性数据集,对应类别标签;
根据X, Y,画出在X上,Y对应的标签值;
根据每个基分类器决策树的节点属性,属性划分点,画出对应的边界线;
按照书上图8.4的格式设置绘图格式,包括x,y轴范围,标签名等;
main函数,调用上述功能函数

-
实验结果

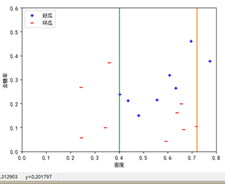



-
程序清单:
import pandas as pd
from numpy import *
import matplotlib.pyplot as plt
#数据集
def loadData(filename):
dataSet = pd.read_csv(filename).replace(['是', '否'], [1, -1])
dataMat = mat(dataSet[['密度', '含糖率']])
classLabels = dataSet['好瓜'].values
return dataMat, classLabels
#比较阈值,进行分类 threshVal 是阈值,即对某个特征的分割,threshIneq为不等号,确定是大于为-还是小于为-1
def stumpClassify(dataMtrix, dimen, threshVal, threshIneq): #dim为那一列(那个属性)
retArray = ones((shape(dataMtrix)[0],1)) #把类别都先设置为1
if threshIneq == 'lt':
retArray[dataMtrix[:,dimen] <= threshVal] = -1
else:
retArray[dataMtrix[:,dimen] > threshVal] = -1
return retArray
#单层决策树 D为权重
def buildStump(dataArr, classLabels, D):
dataMAtrix = mat(dataArr)
labelMat = mat(classLabels).T
m,n = shape(dataMAtrix) #行数和列数
numSteps = 10.0 #每个特征迭代的步数
bestStump = {} #保存最好的分类的信息
bestClassEst = mat(zeros((m,1))) #保存最好的
minError = inf #误差的值
for i in range(n): #循环每个属性
rangeMin = dataMAtrix[:,i].min()
rangeMax = dataMAtrix[:,i].max() #每个列的最大最小值
stepSize = (rangeMax - rangeMin)/numSteps #每一步的长度
for j in range(-1,int(numSteps)+1):
for inequel in ['lt','gt']:
threshVal = rangeMin + float(j)*stepSize #每一步划分的阈值
predictedVals = stumpClassify(dataMAtrix,i,threshVal,inequel) #预测的分类值
errArr = mat(ones((m,1))) #假全错了
errArr[predictedVals == labelMat] = 0 #分正确的变为0
weightError = D.T*errArr #errArr为1的位置说明是分错的,则对应位子的样本的权重相加
#保存信息
if weightError < minError:
minError = weightError
bestClassEst = predictedVals.copy() #保存最好的分类预测值
bestStump['dim'] = i #最好的列(最好的属性)
bestStump['thred'] = threshVal #属性列最好的分割阈值
bestStump['ineq'] = inequel #最好的符号
return bestStump,minError,bestClassEst
#基于单层的决策树AdaBoost训练函数 numIt指的迭代的次数
def AdaBoost(dataArr, classLabels, numIt = 40):
weakClassArr = [] #保存每次迭代器的信息
m = shape(dataArr)[0]
D = mat(ones((m,1))/float(m)) #初始化权重
aggClassESt = mat(zeros((m,1))) #累计每次分类的结果
for _ in range(numIt):
bestStump, error, classEst = buildStump(dataArr,classLabels,D)
alpha = float(0.5*log((1 - error)/max(error,1e-16))) #函数的权重
bestStump['alpha'] = alpha #记录权重
weakClassArr.append(bestStump) #保存每一轮的结果信息
#更新权重
expon = multiply(-1 * alpha * mat(classLabels).T, classEst) # 计算指数
D = multiply(D, exp(expon))
D = D / D.sum() # 归一化
#累计每个函数的预测值 (权重 * 预测的类)
aggClassESt += alpha *classEst
errorRate = 1.0 * sum(sign(aggClassESt) != mat(classLabels).T)/m #预测的和真实的标签不应样的个数/总的个数
if errorRate == 0.0:
break #如果提前全部分类真确,则提前停止循环
return weakClassArr
#分类
def predict(datatoClass, classifierArr):#大分类的数据,训练好的分类器
dataMatrix = mat(datatoClass)
m = shape(dataMatrix)[0]
aggClassEst = mat(zeros((m,1))) #保存预测的值 m个数据m个预测值
for i in range(len(classifierArr)): #循环遍历所有的分类器
classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],
classifierArr[i]['thred'],
classifierArr[i]['ineq'])
aggClassEst += classifierArr[i]['alpha'] * classEst #第i个分类器的预测值*他的权重
return sign(aggClassEst)
#绘制数据集
def plotData(X, Y, clf):
X1, X2 = [], []
Y1, Y2 = [], []
for data, label in zip(X, Y):
if label > 0:
X1.append(data[0, 0])
Y1.append(data[0, 1])
else:
X2.append(data[0, 0])
Y2.append(data[0, 1])
x = linspace(0, 0.8, 100)
y = linspace(0, 0.6, 100)
for weakClasser in clf:
# print(weakClasser.attribute, weakClasser.partition)
z = [weakClasser['thred']] * 100
if weakClasser['dim'] == 0:
plt.plot(z, y)
else:
plt.plot(x, z)
plt.scatter(X1, Y1, marker='+', label='好瓜', color='b')
plt.scatter(X2, Y2, marker='_', label='坏瓜', color='r')
plt.xlabel('密度')
plt.ylabel('含糖率')
plt.xlim(0, 0.8) # 设置x轴范围
plt.ylim(0, 0.6) # 设置y轴范围
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.legend(loc='upper left')
plt.show()
if __name__=='__main__':
filename = 'data_3a.txt'
dataSet, classLabels = loadData(filename)
sizes = [3, 5, 11]
for size in sizes:
weakClassArr = AdaBoost(dataSet, classLabels, size)
predictLabels = predict(dataSet, weakClassArr)
accuracy = 0
for y1, y2 in zip(classLabels, predictLabels):
if y1 == y2:
accuracy += 1
print('Size:', size)
print('Accuracy:', accuracy, '/', len(classLabels))
print('')
plotData(dataSet, classLabels, weakClassArr)