机器学习(周志华) 西瓜书 第四章课后习题6.3—— Python实现
-
实验题目
选择两个UCI数据集,分别用线性核和高斯核训练一个SVM,并与BP神经网络和C4.5决策树进行实验比较。
-
实验原理
sklearn.svm.SVC
参数:
kernel:Specifies the kernel type to be used in the algorithm. It must be one of ‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’ or a callable.
- ‘linear’:线性核函数
- ‘poly’:多项式核函数
- ‘rbf’:径像核函数/高斯核
- ‘sigmod’:sigmod核函数
- ‘precomputed’:核矩阵
参考文档:
https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html
-
实验过程
数据集获取
选取最受欢迎的Iris数据集:
http://archive.ics.uci.edu/ml/machine-learning-databases/iris/
算法实现
数据集读取

划分数据集

将数据集以样例类别比例划分成n等分,默认划分为10等分,但实际传入n=3,也就是将数据集划分为3等分,分别都是50个正例和50个反例;之所以分为3个等分,是为了让训练集分到2个等分,测试集获得1个等分,使其比例为2:1
运行函数

函数接受参数:训练数据集、测试数据集、核选项默认为高斯核;函数负责训练和验证SVM的准确性,最终输出准确率。
主函数
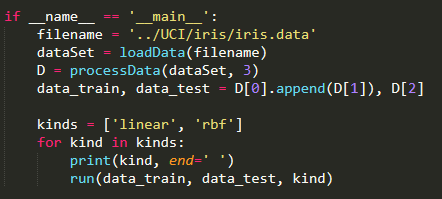
调用上述功能函数,调用两次运行函数,核选项分别为线性核、高斯核,比较两者的准确率;
-
实验结果
BP神经网络预测结果,见习题5.6

C4.5 决策树预测结果,见习题4.6
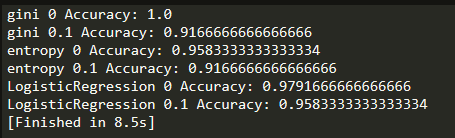
SVM预测结果
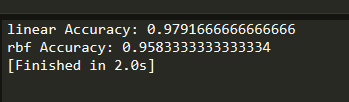
-
程序清单:
import pandas as pd
from sklearn import svm
from sklearn import metrics
names = ['sepal length', 'sepal width', 'petal length', 'petal width', 'class']
def loadData(filename):
dataSet = pd.read_csv(filename, names=names)
return dataSet
# 将数据集划分中对等的训练集和测试集
def processData(dataSet, n=10):
values = ['Iris-setosa', 'Iris-versicolor', 'Iris-virginica']
classifications = []
gaps = []
for value in values:
temp = dataSet.loc[dataSet['class']==value]
classifications.append(temp)
gap = temp.shape[0]//n
gaps.append(gap)
D = [None for _ in range(n)]
for a in range(n):
for gap, classification in zip(gaps, classifications):
begin = a * gap
#print(classification[begin:begin+gap])
if type(D[a]).__name__ == 'NoneType':
D[a] = classification[begin:begin+gap]
else:
D[a] = D[a].append(classification[begin:begin+gap])
#print(type(D[a]))
#print(classification[begin:begin+gap])
return D
def run(data_train, data_test, kernel='rbf'):
train_data, train_target = data_train[names[:-1]], data_train[names[-1]]
test_data, test_target = data_test[names[:-1]], data_test[names[-1]]
# 调用SVC()
'''
kernel: str参数 默认为‘rbf’
算法中采用的核函数类型,可选参数有:
‘linear’:线性核函数
‘poly’:多项式核函数
‘rbf’:径像核函数/高斯核
‘sigmod’:sigmod核函数
‘precomputed’:核矩阵
'''
clf = svm.SVC(kernel=kernel)
# fit()训练
clf = clf.fit(train_data, train_target)
predict_target = clf.predict(test_data)
# Accuracy
acc = metrics.accuracy_score(test_target, predict_target)
print('Accuracy:', acc)
if __name__ == '__main__':
filename = '../UCI/iris/iris.data'
dataSet = loadData(filename)
D = processData(dataSet, 3)
data_train, data_test = D[0].append(D[1]), D[2]
kinds = ['linear', 'rbf']
for kind in kinds:
print(kind, end=' ')
run(data_train, data_test, kind)