机器学习(周志华) 西瓜书 第三章课后习题4.4—— Python实现
-
实验题目
试编程实现基于基尼指数进行划分选择的决策树算法,并为表4.2中数据生成预剪枝、后剪枝决策树,并与未剪枝决策树进行比较。
-
实验原理
基于基尼系数作为划分选择

预剪枝
预剪枝是在决策树的生成过程中,对每个结点划分前先做评估,如果划分不能提升决策树的泛化性能,就停止划分并将此节点记为叶节点;
预剪枝使得决策树的很多分支没有展开,可以降低过拟合的风险,减少决策树的训练时间和测试时间。但是,尽管有些分支的划分不能提升泛化性能,但是后续划分可能使性能显著提高,由于预剪枝没有展开这些分支,带来了欠拟合的风险。
后剪枝
后剪枝是在决策树构造完成后,自底向上对非叶节点进行评估,如果将其换成叶节点能提升泛化性能,则将该子树换成叶节点。
后剪枝通常比预剪枝保留更多的分支,欠拟合风险小。但是后剪枝是在决策树构造完成后进行的,其训练时间的开销会大于预剪枝。
-
实验过程
数据集获取
获取书中的西瓜数据集2.0,并存为data_2.txt;将其划分为训练集和验证集;
编号,色泽,根蒂,敲声,纹理,脐部,触感,好瓜
1,青绿,蜷缩,浊响,清晰,凹陷,硬滑,是
2,乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,是
3,乌黑,蜷缩,浊响,清晰,凹陷,硬滑,是
4,青绿,蜷缩,沉闷,清晰,凹陷,硬滑,是
5,浅白,蜷缩,浊响,清晰,凹陷,硬滑,是
6,青绿,稍蜷,浊响,清晰,稍凹,软粘,是
7,乌黑,稍蜷,浊响,稍糊,稍凹,软粘,是
8,乌黑,稍蜷,浊响,清晰,稍凹,硬滑,是
9,乌黑,稍蜷,沉闷,稍糊,稍凹,硬滑,否
10,青绿,硬挺,清脆,清晰,平坦,软粘,否
11,浅白,硬挺,清脆,模糊,平坦,硬滑,否
12,浅白,蜷缩,浊响,模糊,平坦,软粘,否
13,青绿,稍蜷,浊响,稍糊,凹陷,硬滑,否
14,浅白,稍蜷,沉闷,稍糊,凹陷,硬滑,否
15,乌黑,稍蜷,浊响,清晰,稍凹,软粘,否
16,浅白,蜷缩,浊响,模糊,平坦,硬滑,否
17,青绿,蜷缩,沉闷,稍糊,稍凹,硬滑,否算法实现:
不剪枝的决策树的生成方法与基于信息熵增益为划分选择的决策树生成方法基本一致,主要不同点是每次从A中选择最优划分属性的方法;决策树生成细节详见4.3题:https://blog.csdn.net/weixin_37922777/article/details/88829801
本题不考虑出现缺省值和连续值
计算基尼值函数

计算基于属性值key的基尼指数

从A中选择最优的划分属性值
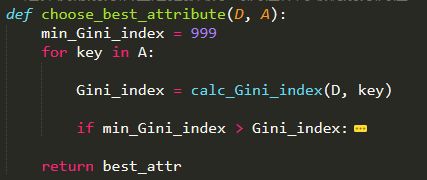
判断是否需要预剪枝

后剪枝:递归思想,从叶节点往根节点逐层判断是否需要剪枝

决策树递归生成函数

决策树训练及其测试

绘制树图的模块
详见 https://blog.csdn.net/weixin_37922777/article/details/88821957
主函数

-
实验结果

| 不剪枝 : |
预剪枝 : |
后剪枝 : |
| Hit: 2 / 7 |
Hit: 4 / 7 |
Hit: 4 / 7 |
| Accuracy: 0.2857142857142857 |
Accuracy: 0.5714285714285714 |
Accuracy: 0.5714285714285714 |
| {'色泽': {'青绿': {'敲声': {'清脆': '否', '沉闷': '否', '浊响': '是'}}, '乌黑': {'根蒂': {'蜷缩': '是', '硬挺': '是', '稍蜷': {'纹理': {'稍糊': '是', '模糊': '是', '清晰': '否'}}}}, '浅白': '否'}} |
{'色泽': {'青绿': '是', '乌黑': '是', '浅白': '否'}} |
{'色泽': {'青绿': '是', '乌黑': {'根蒂': {'蜷缩': '是', '硬挺': '是', '稍蜷': '是'}}, '浅白': '否'}} |
不剪枝 :

预剪枝 :

后剪枝 :

-
程序清单
import json
import math
import plotTree
import numpy as np
import pandas as pd
class_name = '好瓜'
D_keys = {
'色泽': ['青绿', '乌黑', '浅白'],
'根蒂': ['蜷缩', '硬挺', '稍蜷'],
'敲声': ['清脆', '沉闷', '浊响'],
'纹理': ['稍糊', '模糊', '清晰'],
'脐部': ['凹陷', '稍凹', '平坦'],
'触感': ['软粘', '硬滑'],
}
# 读取数据
def loadData(filename):
dataSet = pd.read_csv(filename)
return dataSet
# 叶节点选择其类别为D中样本最多的类
def choose_largest_example(D):
Count = D[class_name].value_counts()
Max, Max_key = -1, None
for key, value in Count.items():
if value > Max:
Max = value
Max_key = key
return Max_key
# 判断D中的样本在A上的取值是否相同
def same_value(D, A):
for key in A:
if len(D[key].value_counts()) > 1:
return False
return True
# 计算基尼值
def calc_Gini(D):
Sum, Total = 0, D.shape[0]
Count = D[class_name].value_counts()
for key, value in Count.items():
prob = value / Total
Sum += prob**2
return 1 - Sum
# 计算属性值为key的基尼指数
def calc_Gini_index(D, key):
Sum, D_size = 0, D.shape[0]
for value in D_keys[key]:
Dv = D.loc[D[key]==value]
Dv_size = Dv.shape[0]
Sum += (Dv_size/D_size) * calc_Gini(Dv)
return Sum
# 从A中选择最优的划分属性值
# 选择使得划分后基尼指数最小的属性作为最优划分属性
def choose_best_attribute(D, A):
min_Gini_index = 999
for key in A:
Gini_index = calc_Gini_index(D, key)
if min_Gini_index > Gini_index:
min_Gini_index = Gini_index
best_attr = key
return best_attr
# 计算测试集中被分类正确的样本个数
def classify_accuracy(D, label):
return D.loc[D[class_name]==label].shape[0]
# 判断是否需要预剪枝
# 预剪枝的策略,验证集精度没有提升的话,不再划分
def judge_whether_prune(D_train, D_test, key, label):
do_prune_accuracy = classify_accuracy(D_test, label)
undo_prune_accuracy = 0
for value in D_keys[key]:
Dv_train = D_train.loc[D_train[key]==value]
Dv_test = D_test.loc[D_test[key]==value]
temp_label = choose_largest_example(Dv_train)
undo_prune_accuracy += classify_accuracy(Dv_test, temp_label)
# print(key, label, do_prune_accuracy, undo_prune_accuracy)
return undo_prune_accuracy <= do_prune_accuracy
# 后剪枝操作:
def post_prune(Tree, D_train, D_test):
if type(Tree).__name__ == 'dict':
label = choose_largest_example(D_train)
do_prune_accuracy = classify_accuracy(D_test, label)
undo_prune_accuracy = 0
key = list(Tree.keys())[0]
for value in D_keys[key]:
next_Tree = Tree[key][value]
Dv_train = D_train.loc[D_train[key]==value]
Dv_test = D_test.loc[D_test[key]==value]
temp_label = choose_largest_example(Dv_train)
undo_prune_accuracy += classify_accuracy(Dv_test, temp_label)
flag = post_prune(next_Tree, Dv_train, Dv_test)
if flag:
Tree[key][value] = temp_label
return undo_prune_accuracy < do_prune_accuracy
else:
return False
# 函数TreeGenerate 递归生成决策树,以下情形导致递归返回
# 1. 当前结点包含的样本全属于一个类别
# 2. 当前属性值为空, 或是所有样本在所有属性值上取值相同,无法划分
# 3. 当前结点包含的样本集合为空,不可划分
# prune: 0 - undo, 1 - pre prune, 2 - post prune
def TreeGenerate(D, A, D_test, prune=0):
Count = D[class_name].value_counts()
if len(Count) == 1:
return D[class_name].values[0]
if len(A)==0 or same_value(D, A):
return choose_largest_example(D)
node = {}
best_attr = choose_best_attribute(D, A)
if prune == 1:
label = choose_largest_example(D)
flag = judge_whether_prune(D, D_test, best_attr, label)
if flag:
return label
new_A = [key for key in A if key != best_attr]
for value in D_keys[best_attr]:
Dv = D.loc[D[best_attr]==value]
Dv_test = D_test.loc[D_test[best_attr]==value]
if Dv.shape[0] == 0:
node[value] = choose_largest_example(D)
else:
node[value] = TreeGenerate(Dv, new_A, Dv_test, prune)
# plotTree.plotTree(Tree)
return {best_attr: node}
# 深度优先遍历,判断预测值
def dfs_Tree(Tree, row):
if type(Tree).__name__ == 'dict':
key = list(Tree.keys())[0]
value = row[key]
next_Tree = Tree[key][value]
return dfs_Tree(next_Tree, row)
else:
return Tree
def run_DT_test(data_test, Tree):
accuracy = 0
for index, row in data_test.iterrows():
result = dfs_Tree(Tree, row)
if result == row[class_name]:
# print(row.values)
accuracy += 1
print('Hit:', accuracy, '/', data_test.shape[0])
print('Accuracy:', accuracy/data_test.shape[0])
# 决策树训练及其测试函数
def run_DT_program(data_train, data_test, prune=0):
A = [column for column in data_train.columns if column != class_name]
Tree = TreeGenerate(data_train, A, data_test, prune)
# post prune
if prune == 2:
post_prune(Tree, data_train, data_test)
run_DT_test(data_test, Tree)
print(Tree)
if type(Tree).__name__ == 'dict':
plotTree.createPlot(Tree)
if __name__ == '__main__':
# 读取数据
filename = 'data_2.txt'
dataSet = loadData(filename)
dataSet = dataSet.drop(columns=['编号'])
index_train = [0,1,2,5,6,9,13,14,15,16]
data_train = dataSet.iloc[index_train]
data_test = dataSet.drop(index_train)
kinds = ['不剪枝', '预剪枝', '后剪枝']
for prune in range(3):
print(kinds[prune], ':')
run_DT_program(data_train, data_test, prune)