版权声明:个人原创,禁止私自转载,如需转载引用请私信联系——Zetrue_Li https://blog.csdn.net/weixin_37922777/article/details/90138139
机器学习(周志华) 西瓜书 第九章课后习题9.10—— Python实现
-
实验题目
试设计一个能自动确定聚类数的改进k均值算法,编程实现并在西瓜数据集4.0上运行。
-
实验原理
K均值算法原理

K均值算法

自动确定k值的度量指标,最小化E:
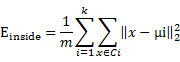

![]()
E值越小则簇内样本相似度越高,簇间样本相似度越低,且k值保证是较小的值,即簇类尽可能保证是大型簇类(这里考虑样本只有两种类别,所以k值应趋近于2);
-
实验过程
数据集获取
将西瓜数据集3.0保存为data_3.txt
编号,色泽,根蒂,敲声,纹理,脐部,触感,密度,含糖率,好瓜
1,青绿,蜷缩,浊响,清晰,凹陷,硬滑,0.697,0.46,是
2,乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,0.774,0.376,是
3,乌黑,蜷缩,浊响,清晰,凹陷,硬滑,0.634,0.264,是
4,青绿,蜷缩,沉闷,清晰,凹陷,硬滑,0.608,0.318,是
5,浅白,蜷缩,浊响,清晰,凹陷,硬滑,0.556,0.215,是
6,青绿,稍蜷,浊响,清晰,稍凹,软粘,0.403,0.237,是
7,乌黑,稍蜷,浊响,稍糊,稍凹,软粘,0.481,0.149,是
8,乌黑,稍蜷,浊响,清晰,稍凹,硬滑,0.437,0.211,是
9,乌黑,稍蜷,沉闷,稍糊,稍凹,硬滑,0.666,0.091,否
10,青绿,硬挺,清脆,清晰,平坦,软粘,0.243,0.267,否
11,浅白,硬挺,清脆,模糊,平坦,硬滑,0.245,0.057,否
12,浅白,蜷缩,浊响,模糊,平坦,软粘,0.343,0.099,否
13,青绿,稍蜷,浊响,稍糊,凹陷,硬滑,0.639,0.161,否
14,浅白,稍蜷,沉闷,稍糊,凹陷,硬滑,0.657,0.198,否
15,乌黑,稍蜷,浊响,清晰,稍凹,软粘,0.36,0.37,否
16,浅白,蜷缩,浊响,模糊,平坦,硬滑,0.593,0.042,否
17,青绿,蜷缩,沉闷,稍糊,稍凹,硬滑,0.719,0.103,否算法实现
读取数据

计算两样本向量的的欧式距离

为给定的簇类计算均值向量

静态K均值算法,获得划分为k簇类集

对划分后的结果进行误差计算,基于自动确定k值的度量指标

动态K均值算法,返回最佳的k值

main函数,调用上述函数,输出自动确定k值后的划分结果

-
实验结果

-
程序清单:
import random as rd
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def loadData(filename):
dataSet = pd.read_csv(filename)
dataSet.drop(columns=['编号'], inplace=True)
return dataSet
#计算每个向量和均值向量之间的距离
def calc_distance(x, mu):
distance = 0
for xi, yi in zip(x, mu):
distance += (xi-yi)**2
return distance**(.5)
#根据目前的簇类计算出均值向量
def calc_mu(dataSet, indexs):
Ci = dataSet.loc[indexs]
return np.array(Ci.mean())
def k_means(dataSet, k, iterate=100):
Mu_indexs = rd.sample(range(dataSet.shape[0]), k)
Mu = [np.array(dataSet.loc[index]) for index in Mu_indexs]
now, flag = 0, True
while flag and now < iterate:
C = [[] for _ in range(k)]
for index, row in dataSet.iterrows():
distances = []
for mu in Mu:
# x = np.array(dataSet.loc[index])
distance = calc_distance(row, mu)
distances.append(distance)
label = np.argmin(distances)
C[label].append(index)
flag = False
for i in range(len(Mu)):
new_mu = calc_mu(dataSet, C[i])
if (new_mu!=Mu[i]).any():
flag = True
Mu[i] = new_mu
now += 1
return C, Mu
def calc_E(dataSet, C, Mu, k):
E_inside, E_outside, size= 0, 0, dataSet.shape[0]
#簇内
for Ci, mu in zip(C, Mu):
for index in Ci:
distance = calc_distance(dataSet.loc[index], mu)
E_inside += distance**2
# 正则化保持权重
E_inside /= size
# 簇间
for a in range(k):
for b in range(k):
if a == b:
continue
distance = calc_distance(Mu[a], Mu[b])
E_outside += distance**2
E_outside /= k
return E_inside - E_outside + 2*k/size
def Dynamic_K_means(dataSet):
size, before_E = len(dataSet), 9999
for k in range(2, size):
Es = []
# 计算多次k均值,取平方误差平均值
for time in range(10):
C, Mu = k_means(dataSet, k)
E = calc_E(dataSet, C, Mu, k)
Es.append(E)
Best_E = sum(Es)/len(Es)
if before_E <= Best_E:
return k-1
else:
before_E = Best_E
return 1
if __name__=='__main__':
filename = 'data_4.txt'
dataSet = loadData(filename)
k = Dynamic_K_means(dataSet)
Best_E = 9999
# 多次计算,取最好结果
for _ in range(10):
C, Mu= k_means(dataSet, k)
E = calc_E(dataSet, C, Mu, k)
if E < Best_E:
Best_E = E
Best_C = C
print('k =', k)
for Ci in Best_C:
print(Ci)