回顾与前言
在上一篇博客中,我们通过小明习得“买瓜秘笈”的故事了解了机器学习的大概流程以及一些相应的基本术语。在接下来的文章中,我们将开始学习具体的机器学习算法啦!
学习什么知识模型都是一个从简到难的过程。很多时候未知的问题要通过将其分割成已经解决的问题,复杂的模型要通过简单模型的变形、组合来解决,比如说今天学习的线性模型看似很简单,非线性模型是通过映射等手段将其转化为线性模型而解决的;以及多分类问题也是将其分解成多个二分类问题而解决的。这是一种很经典的数学思维所以大家不要小看第三章 线性模型哦~
第三章 线性模型
对于第三章 线性模型我们主要将学习用途最广泛的对数几率回归的算法。
线性模型是最基本的模型,其基本形式是:
但是这种一维的形式实在是太简单了,于是我们从多维的线性模型开始,也就是将
以及系数都变成向量形式,即:
但是一般情况下,只有数值型的属性数据才能够放入模型进行回归。而实际问题中很多属性并不是通过数值表示的,比如上篇博客提到的西瓜的三个属性“色泽”“瓜蒂”“声响”是通过“光亮”“蜷缩”“浑浊”等词语表示的,标签“好瓜”“坏瓜”也是通过词语表示的。所以,我们要事先将这些属性、标签转化成数值型数据。
- 对于定序尺度的变量,比如{好瓜, 坏瓜}、{大,中,小}我们就可以分别设置每个标签对应一个数值;
比如:
- 对于变量值之间无法排序,也就是说各个属性值可能是并列的,比如颜色属性{绿色,黑色}与方向属性{东,南,西,北};
如果属性有k个可能的取值,我们可以设置一个k维向量来表示属性值, 每个分量取值均为0或1代表是否是对应的属性值。
比如:绿色 (1,0)
南方 (0,1,0,0)
(ps:类似于经济学研究中虚拟变量的设置)
对数几率回归
回到西瓜的例子,我们现在已经将西瓜的标签{好瓜,坏瓜}设置成{0,1}。显然,这里的标签值就是线性模型中的
值,
则是西瓜的各种属性值。
如果将其带入基本模型
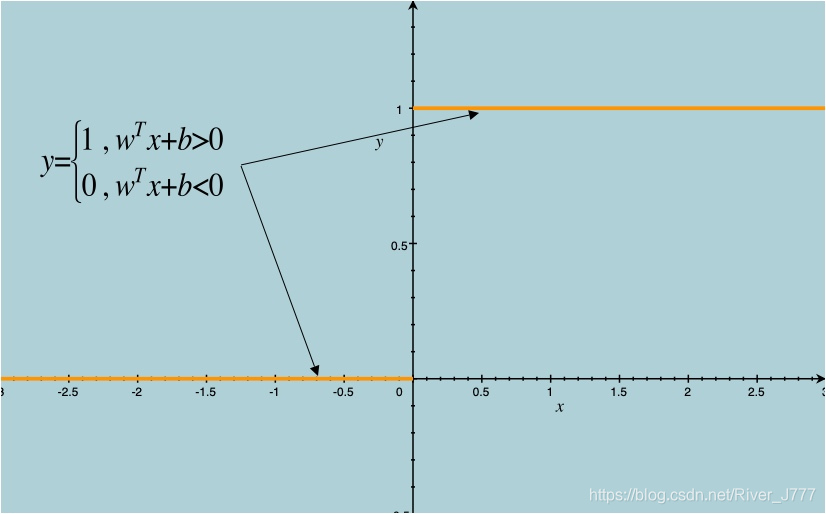
之中,我们则会得到一个单位跃阶函数,如下图:
在
时,
,
当
时,
。
但是,跃阶函数并不是连续可微的,很难进行回归,于是数学家们找到了一个近似函数 ,称之为对数几率函数如图:
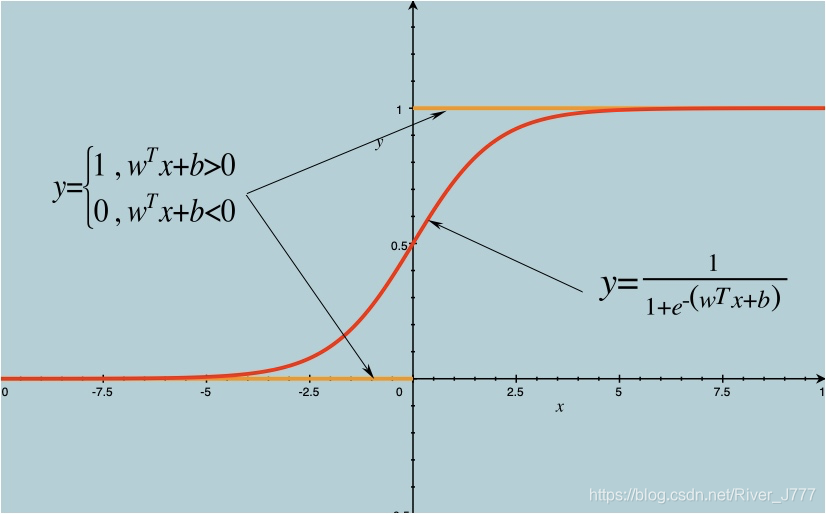
从图中我们可以看出,对数几率函数用来近似单位跃阶函数的两条极大的优点:
- 除了x=0附近,它可以把自变量转化成非常接近1或0的值;
- 它在x=0附近变化很陡。
凭借这两条优点,数学家们利用对数几率函数用来近似单位跃阶函数发明了对数几率回归,也叫做逻辑回归。(其实严格意义来说是分类方法,而不是回归方法)
对于
,我们通常会在
最后加入一列1作为常数项
的系数,记作
便可以将
转化为
,以此来简化模型。
接着我们就可以用极大似然法对参数
进行估计。
极大似然法的核心理念是“发生概率越大的事件越有可能发生”。所以我们要求出事件发生的概率,也就是在给定数据集后所有样本取到其对应标签的概率,定义为似然函数,并求最大值。不同的样本之间视为独立的,所以其联合事件的概率是各个样本概率的连乘,即:
取对数并不会改变似然函数的最大值点,所以为了方便计算,我们一般要取对数:
并可得标签取1或0的概率为:
由于
, 则:
整合成一个式子后并取相反数,我们可以知道,最大化似然函数等价于最小化下式:
并求对应的参数
,即:
对于如同本文中似然函数的高阶可导连续凸函数,根据凸优化理论,可以利用最速下降法、牛顿法等求其最值。
以牛顿法为例, 其第 t + 1 轮迭代解的更新公式为:
可以表示为:
其中,
称为牛顿方向.
式子中关于
的一阶、二阶导数为:
所以算法的流程为:
- 给定待估参数 的初始值 ,给定允许误差 ,置迭代次数 ;
- 计算牛顿方向 ;
- 如果
,则停止运算;
否则,更新 ,置 ,转到步骤2;
于是,我们便可以利用对数几率函数进行回归,称之为对数几率回归,以课后习题3.3为例。
课后习题3.3
3.3 编程实现对率回归,并给出西瓜数据集3.0
上的结果。
数据集:西瓜数据集3.0
提取码:950l
首先,我们要读取数据集,并将样本属性与标签分别存入
、
中:
# 读取数据
inputfile = '/Users/Downloads/test.xlsx'
data_original = pd.read_excel(inputfile)
# 为了方便运算一般将x矩阵转置,得到2行17列的矩阵,第一行为密度,第二行为含糖率;加入一行1作为第三行,对应于常数项b
x = np.array(
[list(data_original[u'密度']), list(data_original[u'含糖率']), [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])
y = np.array([1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0])
其次,我们要初始化参数。
牛顿法等数值算法估计
均需要迭代计算,所以需要定义初始值,即密度的系数、含糖率的系数和常数项
,此处初始值设为0,0,1.
允许误差
,设为0.00001.
另外定义
记录迭代次数,初始值为0.
# 定义初始值,分别对应密度、含糖率与常数项的系数
beta = np.array([[0], [0], [1]]) # β列向量
n = 0
epsilon = 0.000001
开始牛顿法的迭代,使用while循环,跳出循环条件在后面
while 1:
为了便于计算似然函数关于 的导数,现将 与 的乘积记为一个整体,记作 .
# 对β进行转置取第一行,再与x相乘(dot),beta_x表示β转置乘以x
beta_x = np.dot(beta.T[0], x)
通过先求出关于 的一阶、二阶导数来求出牛顿方向d
# 先求关于β的一阶导数和二阶导数
dbeta = 0
d2beta = 0
for i in range(17):
# 一阶导数
dbeta = dbeta - np.dot(np.array([x[:, i]]).T,
(y[i] - (np.exp(beta_x[i]) / (1 + np.exp(beta_x[i])))))
# 二阶导数
d2beta = d2beta + np.dot(np.array([x[:, i]]).T, np.array([x[:, i]]).T.T) * (
np.exp(beta_x[i]) / (1 + np.exp(beta_x[i]))) * (
1 - (np.exp(beta_x[i]) / (1 + np.exp(beta_x[i]))))
#得到牛顿方向
d = - np.dot(linalg.inv(d2beta), dbeta)
根据牛顿方向的模与事先给定的允许误差 比较大小,如果小于允许误差,则认为很接近极小值点,停止迭代:
# 迭代终止条件
if np.linalg.norm(d) <= epsilon: # 牛顿方向向量的模小于0.000001时认为很接近极小值点,停止迭代
break # 满足条件直接跳出循环
如果大于允许误差 ,则更新待估参数 ,继续迭代
# 牛顿迭代法更新β
beta = beta + d
n = n + 1
输出结果:
print('模型参数:')
print(' 密度的系数为: ',beta[0],'\n','含糖率的系数为:',beta[1],'\n','常数项为: ',beta[2])
print('迭代次数:', n)
全部代码为:
# 对率回归分类
import numpy as np
from numpy import linalg
import pandas as pd
# 读取数据
inputfile = '/Users/Downloads/test.xlsx'
data_original = pd.read_excel(inputfile)
# 为了方便运算一般将x矩阵转置,得到2行17列的矩阵,第一行为密度,第二行为含糖率;加入一行1作为第三行,对应于常数项b
x = np.array(
[list(data_original[u'密度']), list(data_original[u'含糖率']), [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])
y = np.array([1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0])
# 定义初始值,分别对应密度、含糖率与常数项的系数
beta = np.array([[0], [0], [1]]) # β列向量
n = 0
epsilon = 0.000001
while 1:
# 对β进行转置取第一行
# 再与x相乘(dot),beta_x表示β转置乘以x)
beta_x = np.dot(beta.T[0], x)
# 先求关于β的一阶导数和二阶导数
dbeta = 0
d2beta = 0
for i in range(17):
# 一阶导数
dbeta = dbeta - np.dot(np.array([x[:, i]]).T,
(y[i] - (np.exp(beta_x[i]) / (1 + np.exp(beta_x[i])))))
# 二阶导数
d2beta = d2beta + np.dot(np.array([x[:, i]]).T, np.array([x[:, i]]).T.T) * (
np.exp(beta_x[i]) / (1 + np.exp(beta_x[i]))) * (
1 - (np.exp(beta_x[i]) / (1 + np.exp(beta_x[i]))))
#得到牛顿方向
d = - np.dot(linalg.inv(d2beta), dbeta)
# 迭代终止条件
if np.linalg.norm(d) <= epsilon: # 牛顿方向向量的模小于0.000001时认为很接近极小值点,停止迭代
break # 满足条件直接跳出循环
# 牛顿迭代法更新β
beta = beta + d
n = n + 1
print('模型参数:')
print(' 密度的系数为: ',beta[0],'\n','含糖率的系数为:',beta[1],'\n','常数项为: ',beta[2])
print('迭代次数:', n)
结果为:
模型参数:
密度的系数为: [3.15832966]
含糖率的系数为: [12.52119579]
常数项为: [-4.42886451]
迭代次数: 5
第三章的学习笔记很详细地将对数几率回归算法的来历、原理与编程展现给了大家,本章的其他内容如Fisher判别分析等,以理解算法的思维为主,大家阅读书本即可。
相关链接:
周志华《机器学习》西瓜书 小白Python学习笔记(一) ———— 第一章 绪论 & 第二章 模型评估与选择